最近,在蔚来NIO IN和理想智驾系统发布会上,都提到了“世界模型”这个概念。
蔚来智能驾驶研发副总裁任少卿判断,传统的端到端方案+“世界模型”才能将自动驾驶推进到下一个阶段——端到端并非自动驾驶技术路线的终局。
理想也认为,数据驱动的端到端只能实现L3,要继续迈向L4,需要+基于知识驱动的视觉语言模型/世界模型。
其实何小鹏也曾提出过相似观点,端到端是“L3的最佳路线,但一定不是L4的优选。端到端+大模型才能最终实现L4”。
经过大半年的探索和初步实践,目前本土玩家纷纷发布或量产了各自的端到端方案,后者的价值也得到了自动驾驶行业的一致认可。但它并不是宇宙的尽头。
所以,更进一步的“世界模型”到底是什么?目前发展到了什么阶段?更值得思考的一个问题是,它是智驾大模型的最优解吗?
“世界模型”的启源
还得是特斯拉
2023年的CVPR会议(即IEEE国际计算机视觉与模式识别会议)上,特斯拉自动驾驶负责人Ashok Elluswamy用15分钟,介绍了以车道网络和占用网络为主要内容的FSD基础模型(Foundation Model)。
Ashok抛出了引人深思的问题:把车道网络、占用网络这些东西结合在一起,就足以全面地描述驾驶场景吗?基于这些场景描述就能规划安全、高效且舒适的轨迹了吗?

图片来源:特斯拉
答案当然是不能。
因为在空间层面,OCC空间的颗粒度不够精细,算法检测不到比网格单位尺寸更微小的障碍物,也不包含天气、光照、路面情况等对行车安全性和舒适性,有密切影响的语义信息。时间层面,规划算法是以定长的时间节拍进行信息融合和推演,所以自动建模长时序信息能力的相对匮乏,很难基于当前的场景和车辆动作,精确预测未来一段时间内对汽车驾驶安全性和效率至关重要的场景变化。
怎么办?
特斯拉给出的答案是通过海量数据学习出一个“世界模型”的神经网络,它可以“以过去或其他输入为条件,预测未来。”

图片来源:特斯拉
是的,“世界模型”是一年前由特斯拉正式提出的。
可是因为害怕被友商逐帧学习而不再召开AI Day的特斯拉,在“世界模型”上坚持保持着语焉不详的神秘画风,只用了一句哲思意味的“以过去预测未来”来概括,让人听君一席话,如听一席话。

图片来源:蔚来汽车
蔚来在解释它的世界模型NVM时,让这个概念更清晰、具体起来。概要来说,其两大核心能力是空间认知和时间认知。
空间认知能力可以理解物理规律,进行想象重建;时间认知能力可以生成符合物理规律的未来场景,进行想象推演。
所以在空间理解能力上,NVM作为生成式模型,能全量理解数据,从原始传感器数据中重建场景,减少传统端到端方案从传感器数据到BEV和OCC特征空间转换过程中的信息损耗。
而在时间理解能力上,NVM具备长时序推演和决策能力,通过自回归模型自动建模长时序环境,具有更强的预测能力。

图片来源:蔚来汽车
说人话就是——在空间理解上,“世界模型”采用生成模型架构,天然具备全量提取传感器输入信息的能力,可以提取雨雪风霜天气、暗光逆光炫光光照条件,积雪水坑坑洼路面条件等与驾驶密切相关的泛化信息,避免了BEV和占用网络抽取信息的损失。
在时间理解上,“世界模型”是一种自回归模型。可通过当前(时刻为t)视频和车辆动作生成下一帧(时刻为t+0.1)视频,再基于下一帧(t+0.1)视频和当时的动作,生成下下一帧(时刻为t+0.2)的视频。就这么循环往复,通过对未来场景的深层次理解和模拟,规划决策系统在可能发生的场景中进行推演,寻找到安全、舒适、高效三要素最大公约化的最优路径。
“世界模型”走到了什么阶段
其实,“世界模型”的雏形概念最早可以追溯到1989年。不过由于它和人工智能、神经网络的发展史深度绑定说起来实在太啰嗦,我们也没必要把时间拉那么远。
我们直接快进到2024年2月,从OpenAI甩出王炸Sora。后者以生成长时序且具备高度一致性视频的能力,引起一波大争论开说。
支持者认为Sora具备了对物理世界规律的理解能力,标志着OpenAI的能力开始从数字世界走向物理世界,从数字智能走向空间智能。
而以杨立昆为代表的反对者认为:Sora只是符合“直观物理学”而已,它生成的视频骗骗人眼还行,但没法生成对机器人的传感器具有高度一致性的视频,只有世界模型才真正具备理解物理规律、重建并推演外部世界的能力。
因为没有拿到OpenAI控制权最终与OpenAI闹掰的马斯克当然不会错失这场大论战,他傲娇表示,特斯拉在大约一年前就能以精确的物理规律生成真实世界的视频。而且,特斯拉视频生成能力远超OpenAI,因为它可以预测极其准确的物理特性,这对于自动驾驶至关重要。
根据马斯克的发言和2023 CVPR会议上的介绍,可以得出特斯拉的“世界模型”,可以在云端生成用于模型训练和仿真的驾驶场景。更重要的是还可以压缩部署到车端,将车端运行的FSD基础模型升级为世界模型。
结合特斯拉10月即将发布的,理论上应该具备L4能力的Robotaxi的消息,以及国内车圈大佬们一致认为端到端+大模型才能实现L4的重要判断,特斯拉的世界模型大概率已经在车端量产部署了。
而国内绝大部分自动驾驶玩家训练的世界模型,都还只是部署在云端,用于自动驾驶仿真场景生成的阶段。
比如,理想的世界模型,利用3D高斯模型做场景重建,利用扩散模型做场景生成,以重建+生成相结合的方式,共同组成理想汽车自动驾驶系统的考试方案。
华为和小鹏探索使用大模型生成仿真场景,也符合自动驾驶世界模型的概念。
不过,它们的世界模型生成场景的时序一致性如何,时长能有多久,这三家都没有公开过具体数字。
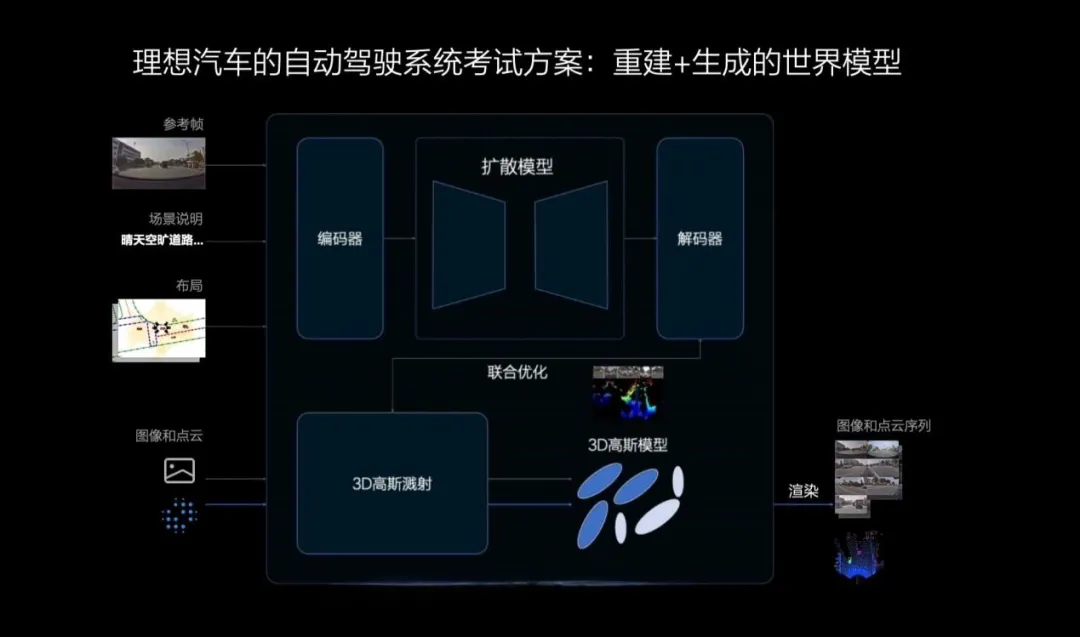
图片来源:理想汽车
蔚来汽车则选择了云端+车端同时攻关的技术路径。
在云端,蔚来的Nsim可以推演万千平行世界,辅助真实数据加速进行NVM的训练。目前,NVM可以生成时间长达120秒的预测。相较之下,OpenAI被吹上天的Sora只能生成60秒的视频。
而且和Sora只有一个简单运镜不同的是,蔚来NVM产生的场景更加丰富多变,可以给出多个指令动作,推演万千平行世界。

图片来源:蔚来汽车
在车端,蔚来NVM可以在0.1秒内推演216种轨迹下的平行世界,从中选择最优路径。然后在接下来0.1秒的时间窗口内,再次根据外部世界收入重新更新内在时空模型,预测216种可能发生的轨迹,依次循环往复,跟随驾驶轨迹持续预测,始终选择最优解。
智驾大模型的最优解在哪里?
我们再折回来说,通过大模型赋能端到端,已经成了继续提高智能驾驶系统能力的一致共识。不过如何在车端部署大模型,头部智驾车企蔚来、理想和小鹏给出了三种不同的答案。
小鹏汽车利用LLM(大语言模型)增强对复杂场景的语义理解能力,综合多源信息有效理解场景中的复杂模糊语义,更好地识别复杂路口、左转等待区、潮汐车道、交通标志。
理想汽车使用的是VLM(视觉语言模型)——直接输入原始传感器数据,建立对当前驾驶场景的全面整体理解,应对传统端到端方案因存在从原始传感器数据到特征空间的信息损失而无法有效处理的复杂场景。
蔚来汽车使用WM(世界模型)改造端到端,直接输入原始传感器数据,并在0.1秒内生成216种驾驶轨迹,从中筛选最优轨迹。
大语言模型LLM、视觉语言基础模型VLM和世界模型WM,哪一个才是自动驾驶大模型的最优解?
我们其实可以等到自动驾驶等级接近L4时,再事后诸葛亮一把。也可以基于一个基本的逻辑给出初步的判断,即LLM、VLM和WM,能多大程度发挥或者利用大模型的能力?
众所周知,大模型带来了两个关键能力的根本性提升:超强的理解能力和超强的生成能力。
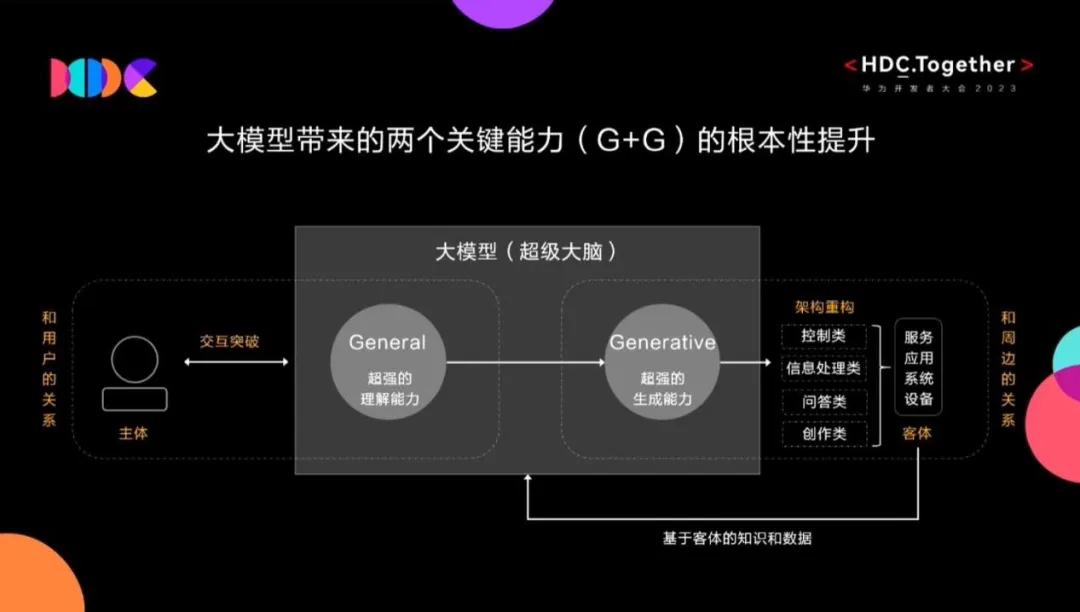
图片来源:华为
小鹏的大语言模型利用大模型的理解能力,理想的视觉语言模型和蔚来的世界模型,既能充分发挥大模型的理解能力,又可以利用大模型的生成能力。
而在以生成能力助力自动驾驶决策规划方面,视觉语言模型适用于生成非实时性的车道建议、车速建议等中间决策。蔚来的世界模型更近一步,可以直接规划轨迹,生成行车路线。
不过我也不是半仙,没法预测世界模型是不是就注定比视觉语言模型的效果好。但是,提醒大家注意一点,行业第一标兵特斯拉的选择,也是世界模型。
写在最后
用一句话总结世界模型的能力:它具备对信息的全景理解力,理解物理规律,并且可以在想象的维度重建当前的世界,推演未来的世界。它能对应生成式AI的“理解+生成”能力上,想象重建对应大模型的理解能力,想象推演对应大模型的生成能力。
而作为本土首个以世界模型赋能端到端的技术架构,蔚来全新智能架构NADArch2.0给人的想象空间是巨大的,也是值得期待的。
据说今年第四季度就能量产上车了,到时再体验体验吧!









