
半导体行业观察CPU,一个现代人天天在用的元件。举凡手机、笔电里皆有其存在。然而,每当有新的 CPU 发布,我们关注于表象但华丽的数字,像是 Cache 的大小、CPU 的执行时脉以及采用几纳米制程等。这一次,让我们撇除以上这些外在事物,一探现代 CPU 的微架构这个“内在美”吧。
从 2007 年开始,Intel 所采取的 Tick-Tock 策略,不断地提升个人电脑的计算速度。其中,Tick 为纳米制程上的演进,每次新产品发布,便是华丽的数字以及技术的炫耀。然而,在 Tock 时,却没有多少人关注微架构的改善。何不从现在起,一同认识 Intel 的 Skylake 微架构。
在先前介绍 CPU 时(【电脑科普】CPU-电脑运作的核心),便说明 CPU 可以分成 3 个部分,分别为“控制单元”、“算数逻辑运算单元”与“暂存器”。控制元件会依据程序的指令,控制所要执行的功能。算术逻辑运算单元则负责进行各类运算。暂存器则分成两类,分别储存运算的资料,以及要接续执行的指令。
现代的 CPU 也没有脱离这一类的规范。当将 Skylake 的元件分类,如下图,也区分成 3 大类。

控制元件是 Front End,算术逻辑运算单元是 OOO (Out Of Order)Execution Engine,快取内存则有储存资料的 L1 DCache、接续执行指令的 L1 ICache 以及共用的 L2 Cache。那么,各个元件的有什么功能呢?就让我们看下去。
各元件功能为何?
首先,就从名字很有趣的 OOO Execution Engine 开始介绍。OOO(Out Of Order)是指在这一个运算单元里面,指令的运行顺序不会按照顺序,尽可能地让指令可以偷跑,让 CPU 处于满载状态。为了可以更明确的知道 OOO 的优点,就从简单的小数计算例子来看吧。

在 in order 的 CPU 中,每一次皆只能执行一个指令。假设 CPU 在浮点数计算需要 5 个 CPU 循环,而且一次只能执行一个指令。进行这 4 个计算需要 20 个循环才能完成。那采用 OOO 技术的 CPU 呢?因为在 OOO 的 CPU 里面,它有多个计算核心,可以预先执行没有相依性的资料。
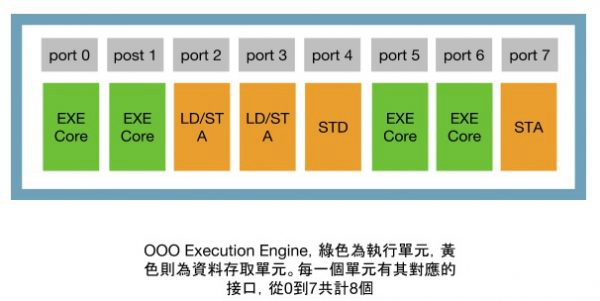
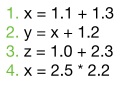
在这个情况下,4 个计算仅需 15 个循环便得以完成,大幅的提升效能。那么在 Skylake 内部,OOO Execution engine 究竟长什么样子呢?它一共有 8 个执行小单元、4 个资料存取单元,以及 4 个计算单元。
其中,每一个执行单元,皆有其可执行的指令,详细的功能图置于最后。
假的资料相依性,断开链接的方法

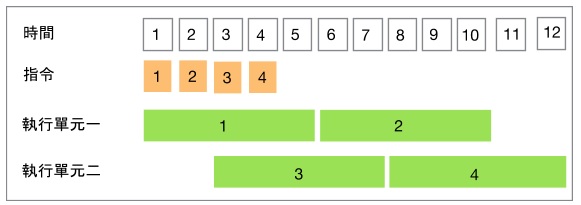
在前个例子中,可以发现第 4 个指令其实和第 2 个指令的 x 不相干。第 4 个 x 实际上是运算新的资料。然而,在前一个例子里,他却需要等待第 4 个指令结束时,如果,可以将变数改名,将可以获得更进一步的平行。
因此,在 Front End 里面,有 Renamer 此一元件,负责将假的相依性剔除,以此获得更多效能改善。然而,在 Skylake 内部,实际上只有 2 个浮点数计算单元。因此,这 4 个指令总共需要 12 个循环才能结束。和最一开始的 20 个循环相比,执行时间大幅的减少。
或许会有人说,这一类的功能一般的编译器就得以完成了,何必需要新增这一类的硬件增添麻烦呢?原因在于,目前的编译器为了让编译完成的程序,得以在多种 CPU 上执行,因此,他只会用到基本的暂存器,然而,在现代的 Intel CPU 中,有更多的暂存器可以使用,为了避免对软件进行过多的更动,最后选择于硬件端完成这一类的工作。
指令集的解码器,切开硬件和指令集的关联
在 Front End 里面,除了 Renamer 这一元件外,还有一个指令集的解码器。在指令集架构发展初期,曾经有过 RISC 和 CISC 的争论。也就是指令集架构是越复杂越好,还是简单就行。X86 架构,做为 CISC 的领头羊以及 CPU 界的巨星,不断地证明 CISC 的优异之处。
然而,在现今的 X86 架构中,CPU 底层硬件运行的指令,却已经采用了 RISC 的概念。CISC 的最大拥护者的易位,便代表着 RISC 在指令集的争论中胜出。那么,究竟是如何将原本的 X86 指令转换成硬件指令呢?沟通的桥梁,便是接下来要介绍的解码器。
在 X86 架构内,有多种复杂的指令集会将数种功能结合在一起。以 Intel 所发布文件中的“ ADD RAX, [ RBP+RSI ] ”为例子,它是将两件工作结合再一起的指令。可以将其解读成 RAX = RAX + LD[ RBP+RSI ]。也就是将资料从 RBP+RSI 中取出,并和 RAX 中的数值相加。
可想而知,此一解码器可以将这两个不同的工作拆开,分成取资料的指令以及数值相加的指令。解码后的结果,就和 RISC 的想法接近,断开复杂指令的锁链!此外,简单的 x86 指令也会被拆开来,重新组成硬件的底层指令。解析完的硬件指令,则有 micro-op 的别称。接下来,便会有一个 micro-op 的序列,储存解析后的指令。实际的 Front End 简图如下。
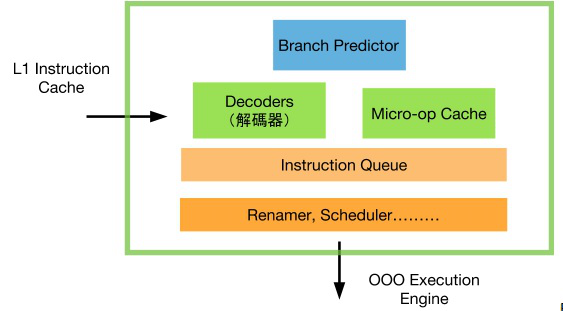
其中,有一个 Micro-op Cache 这个需要特别注意的元件。此元件是从 Intel Sandy Bridge 才加入。如其名,他是将过去曾经解码过的指令存起来的暂存内存。在 Sandy Bridge 中,此一元件最多可以储存 256 个 x86 指令,以及其对应的 micro-op。借由 Micro-op Cache,可以减少使用频繁之指令的解码,大大提升计算的效能。
至此,对于 Intel Skylake 的“内在美”已经做了充足的介绍。最后,附上完整版的 Skylake 微架构图。
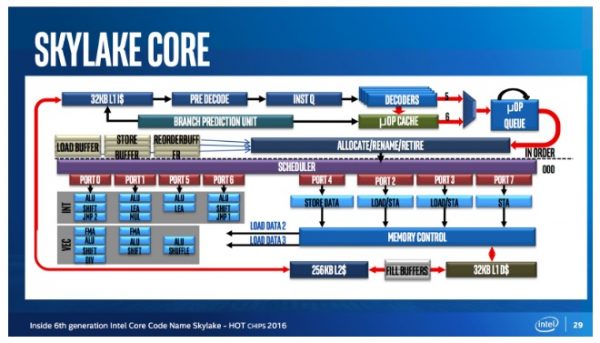
(Source:Intel)
- Computer Architecture, Fifth Edition: A Quantitative Approach
- Computer Architecture, A Quantitative approach
- INSIDE 6TH GEN INTEL CORE: NEW MICROARCHITECTURE CODE NAMED SKYLAKE
- Intel’s Haswell Architecture Analyzed: Building a New PC and a New Intel
(首图来源:Intel)
延伸阅读:
- 【电脑科普】CPU-电脑运作的核心
如需获取更多资讯,请关注微信公众账号:半导体行业观察









