1. 全文一览
激光雷达全景分割是自动驾驶车辆全面理解周围物体和场景的关键技术,它要求算法具有实时性。最近的无先验方法虽然加快了运算速度,但由于难以建模不存在的实例中心和高昂的基于中心的聚类开销,其有效性和效率仍然有限。为了实现准确和实时的激光雷达全景分割,本文提出了一种新的中心对焦网络(CFNet)。具体来说,本文提出了一种中心对焦特征编码(CFFE)模块,它通过移动激光雷达点并填充中心点,显式地建模了原始激光雷达点与虚拟实例中心之间的关系。此外,本文提出了一种中心去重模块(CDM),它可以高效地保留每个实例的唯一中心,消除冗余的中心检测。在SemanticKITTI和nuScenes两个全景分割基准数据集上的评估结果表明,与所有现有方法相比,我们的CFNet在性能上取得了显著的提升,同时速度比最高效的方法快1.6倍。

图1. SemanticKITTI测试集上的PQ与运行时间。
2. 问题简介
全景分割是一种将语义分割和实例分割结合在一起的技术。它为不可数的东西类(例如道路,人行道)分配语义标签,同时为可数的东西类(例如汽车,行人)分配语义标签和实例ID。激光雷达全景分割是自动驾驶安全的重要基础,它利用激光雷达传感器采集的点云有效地描述周围环境。现有的激光雷达全景分割方法通常先进行语义分割,然后通过两种方式实现东西类的实例分割,即基于先验框架和无先验框架的方法。
基于先验框架的方法采用与图像领域中著名的Mask R-CNN类似的两阶段流程。它首先使用3D检测网络生成物体先验框,然后在每个先验框内单独提取实例分割结果。如图1所示,这些方法通常非常复杂,由于其顺序的多阶段流水线,难以实现实时处理。
基于无先验框架的方法更为简洁。为了将东西点与实例ID关联起来,这些方法通常利用实例中心。具体来说,它们回归从点到对应中心的偏移量,然后采用与类别无关的基于中心的聚类模块或基于鸟瞰图(BEV)的中心热力图。然而,这些方法存在两个问题。首先,对于中心特征提取和中心建模,由于激光雷达点通常是表面聚集的,在大多数情况下,实例中心是不存在的,这增加了难度。如图2(a)所示,这种困难通常导致一个实例被错误地分割成多个部分。其次,对于利用冗余检测到的中心,聚类模块(例如MeanShift,DBSCAN)的计算时间过长,无法满足实时自动驾驶感知系统的需求,而BEV中心热力图无法区分不同高度的物体位于同一个BEV网格中。

图2. 一辆车的实例分割案例,不同颜色表示不同的实例。不带我们的CFFE模块,汽车被分割成部分(a),而CFFE显著改善了这个问题(b)。
为了实现准确和快速的激光雷达全景分割,本文提出了一种无先验框架的中心对焦网络(CFNet)。为了更好地编码中心特征,本文提出了一种新的中心对焦特征编码(CFFE)模块,它通过移动激光雷达点并填充中心点,以获得更精确的预测(如图2(b)所示)。为了更好地建模中心,CFNet不仅将全景分割任务分解为广泛使用的语义分割和中心偏移回归,而且还提出了一个新的置信度评分预测,以指示中心偏移回归的准确性。然后,为了高效地利用检测到的中心,本文设计了一个新的中心去重模块(CDM),以选择每个实例的唯一中心。CDM保留预测置信度更高的中心,同时抑制预测置信度较低的中心。最后,通过将移动后的东西点分配给最近的中心来实现实例分割。为了提高效率,CFNet建立在基于2D投影的分割范式之上。
3. 方法详析
激光雷达全景分割任务的输入是激光雷达点云数据集(其中是笛卡尔空间中的3D坐标,表示附加的激光雷达点特征,例如强度)。该任务的目标是为这些点分配一组标签,其中是语义标签(例如道路、建筑、汽车、行人),是第个点的实例ID。此外,可以分为不可数的东西类(例如道路、建筑)和可数的东西类(例如汽车、行人)。东西点的实例ID设置为0。

图3. 我们CFNet的概览。它由四个步骤组成:1) 基于2D投影的backbone在2D空间上提取特征;2) 提出的中心对焦特征编码(CFFE)模拟和增强不存在的实例中心特征;3) 全景分割head预测输出结果;4) 提出的中心去重模块(CDM)实现实例分割,其与语义分割结果融合生成最终全景分割结果。虚线表示操作仅在推理时使用。
为了预测输入激光雷达点云的标签,我们的CFNet将这个过程分解为四个步骤,如图3所示:1)应用现成的基于2D投影的backbone在2D空间上高效提取特征;2)使用新的中心对焦特征编码(CFFE)生成中心对焦特征图,以获得更准确的预测;3)全景分割head将来自3D点和2D空间的特征进行融合,分别预测语义分割结果、中心偏移和中心偏移的置信度评分;4)在推理时进行后处理,生成全景分割结果,其中新的中心去重模块(CDM)对移动后的东西点操作,选择每个实例的一个中心,然后分配移动后的东西点到最近的中心以获取实例ID。
3.1 中心对焦特征编码
如上所述,一个对象的激光雷达点通常是表面聚集的,尤其对于汽车和卡车类别,这导致对象的中心是虚构的,在激光雷达点云中不存在。为了编码不存在中心的特征,提出了一种新的中心对焦特征编码(CFFE),它以backbone提取的2D特征和3D点坐标为输入,生成增强的中心对焦特征图,如图3所示。

图4. 提出的中心对焦特征编码(CFFE)。“Conv”表示带有3×3内核、批归一化和ReLU层的2D卷积。语义分支和实例分支的细节如图3所示。蓝色箭头是坐标相关的操作。
CFFE模块由三个步骤组成,包括中间结果预测、中心特征生成和特征增强模块,如图4所示。
中间结果预测。在这一步中,CFFE根据2D特征 和3D点特征 预测中间结果(包括语义分割、中心偏移和其置信度分数),以便后续模拟中心特征。具体来说,在2D特征 上分别应用两个卷积层,生成语义特征 和实例特征 (m是特定的2D视图,如RV、BEV和极坐标视图)。

其中Conv表示顺序2D卷积、批归一化和ReLU操作, 和 是它们的可学习参数。然后,语义分支通过融合点特征和2D语义特征生成每点3D语义特征,

其中Seg是语义分支,是参数。最后,根据生成中间语义结果。中间的中心偏移结果和置信度分数是通过实例分支预测的,输入为点特征和2D实例特征,

其中Ins是实例分支,FC表示全连接层。语义分支和实例分支的结构及训练目标与全景分割head中的相同,在图3和3.2节中说明。
**中心特征生成(CFG)**。在这一步中,CFFE通过将3D语义点特征根据上述中间结果移位到预测的中心,生成移位的中心特征。
首先,根据以下公式计算一个预测中心的坐标:

其中是原始3D激光雷达点坐标,是一个二值指示器,指示置信度是否大于。换句话说,它不移动东西点或置信度低的东西点。
然后,将移位的3D点作为新坐标的特征点,将3D语义特征 通过Point to Grid (P2G)操作重新投影到具有这个新坐标的2D投影特征图上。

与相比,更关注假想的中心,因为大多数东西点已经移位到它们预测的中心。
**特征增强模块(FEM)**。CFFE最后融合语义特征图和重新投影的移位中心特征图来生成中心对焦语义特征图和实例特征图,它们将由后续的语义分支和实例分支进行更准确的预测。增强模块由简单的连接操作和几个卷积层组成,详细结构在补充材料中。
另外,对于应用多视图融合backbone的情况,每个视图的特征图、、、 (例如m ∈ {RV, BEV})都根据上述流程独立计算。然后,它们在点融合(PF)模块中进行融合,生成集成的3D点特征和每点预测。
3.2 全景分割头
为了更好地建模实例中心,全景分割头使用语义分支预测语义分割,实例分支同时估计中心偏移和新引入的置信度分数,给定中心对焦语义特征图和实例特征图。
语义分支。为了进行每点预测,语义分支首先应用Grid到点(G2P)操作从2D语义特征图获取3D点表示。然后,一个PF模块将来自G2P操作的点表示和原始3D点进行融合,生成点表示的语义特征。在获得点的语义特征之后,一个全连接(FC)层用于预测最终的每点语义结果()。 表示第个激光雷达点属于第类的概率。预测的语义标签通过选择概率最高的类获得,即 。
参考CPGNet,采用了相同的损失函数,包括加权交叉熵损失、Lovász-Softmax损失和转换一致性损失。
实例分支。与语义分支类似,实例分支也采用G2P操作和一个PF模块获得点表示的实例特征。一个FC层用于预测每点的中心偏移。的真值是从第个点到其对应的实例中心的偏移向量。
对于中心偏移回归,优化的损失函数仅考虑东西类,形式化如下:

其中是实例的轴对齐中心。
然后,损失函数求和如下:

其中和分别是所有点和东西点的数量。
对于置信度分数回归,另一个FC层用于预测每点的置信度分数,以指示的准确度。通过sigmoid激活函数激活以确保。监督的真值标签由以下生成:

对于东西点,越低,越高。这意味着中心偏移回归更准确的点有更高的置信度分数。
采用加权二进制交叉熵损失,

其中东西点被手动强调,因为它们的数量远少于东西点的数量。
最后,每个结果组(来自CFNet或CFFE)的损失定义为:

总损失是来自CFNet和CFFE的两个损失之和。
3.3 中心去重模块
给定最终预测的语义分割结果、中心偏移和置信度分数,本节介绍如何在推理时利用检测到的中心来获取全景分割结果,并阐述关键模块中心去重模块(CDM)。
后处理。对于全景分割结果,首先生成实例分割,然后通过融合语义分割和实例分割标签获得最终全景分割。有五个步骤生成最终全景分割:
根据预测的语义标签选择东西点,以及它们的偏移和置信度分数(其中M是东西点的数量)。
每个移位后的东西点作为实例中心候选。
CDM根据坐标和置信度分数为每个实例选择一个中心,同时抑制其他候选中心。
实例ID 通过将移位后的东西点分配给所有中心中最近的一个获得(D是检测到的实例数量)。
多数投票法将一个预测实例中最频繁出现的语义标签重新分配给该实例的所有点,以进一步确保预测实例内语义标签的一致性。
**中心去重模块(CDM)**。CDM以移位点和置信度分数为输入,为每个实例获得一个中心。受到边界框NMS的启发,如果两个中心之间的欧式距离小于阈值,我们的CDM会抑制置信度较低的中心。CDM的伪代码如算法1所示,其中两个中心距离小于被认为是同一个实例。CDM的过程很简单,可以轻松在CUDA中实现。
4. 实验结果
本文在SemanticKITTI和nuScenes全景分割基准上评估了CFNet,在单个NVIDIA RTX 3090 GPU上进行运行时间测量,使用全景质量(PQ)指标评估性能。经验证,CFNet在两个基准上的表现均远超现有方法,CFNet比最高效的方法快1.6倍。

图5. 我们的 CFNet 在 SemanticKITTI 测试集上的可视化。不同的颜色代表不同的类或实例。

表1. SemanticKITTI验证集上的ablation研究。RT:运行时间。

表2. 在SemanticKITTI训练集和验证集上,中间结果和带CFFE的CFNet的东西中心偏移的平均误差,单位米(m)。
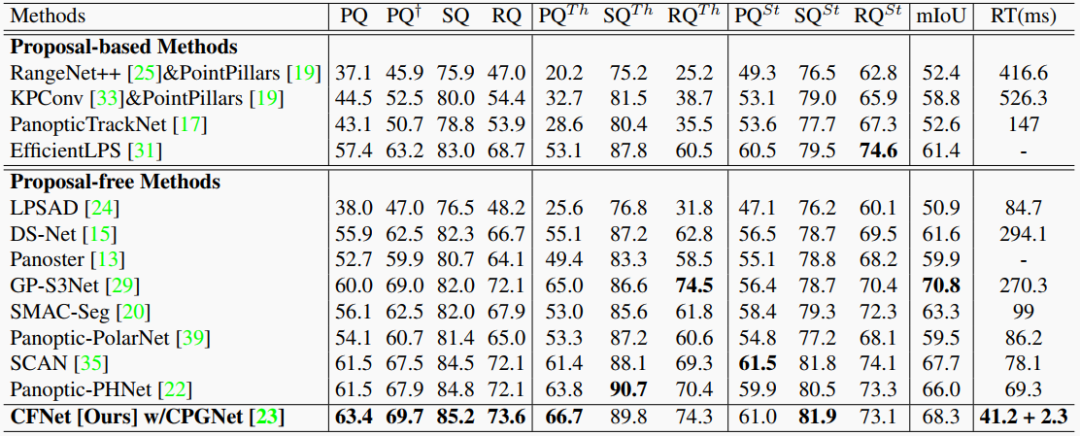
表3. SemanticKITTI 测试集的结果。

表4. NuScenes 验证集的结果。
5. 结论
本文提出了一种新颖的无先验的中心对焦网络(CFNet),用于实时的激光雷达全景分割。为了更好地建模和利用不存在的实例中心,本文提出了一种新的中心对焦特征编码(CFFE)模块,用于生成增强的中心对焦特征图,以及一种中心去重模块(CDM),用于为每个实例保留唯一的中心,然后将移动后的东西点分配给最近的中心,以获取实例ID。从实验中可以看出,中心建模和利用是无先验的激光雷达全景分割方法中的一个关键问题,而模拟不存在的中心特征是有前景的,并且显示出明显的优势。