自动驾驶:自动泊车之AVM环视系统算法2
本文的内容主要讲述AVM 3D算法pipeline,一种自研提取角点标定方法,汽车辅助视角。每个部分都涵盖了完整的算法理论以及部分代码,适合有一些计算机视觉基础的同学,或许可以给相关方向的同学做些参考。
一. 一种更优的联合标定方案
1.1 算法原理分析
在前面的工作中,我们调用opencv函数findChessboardCorners提取图像上位于标定布中间的棋盘格角点,然后计算投影矩阵H。在SLAM 14讲中[1],计算H就是求解Ax=0这样一个问题。其原理就是构造一个最小二乘的形式,用奇异值分解的方式来计算一个误差最小的解。而为了逼近这个最小误差,可能造成除了棋盘格角点以外的其他像素值的投影误差很大。换句话说,由于棋盘格角点集中于鸟瞰图的中心很小的一部分区域,如果选择棋盘格角点进行H的计算,会导致只有棋盘格附近的区域能够进行准确的投影,远离该区域会有较大误差。类似于nn的训练数据过于局限,训练的模型过拟合了。这也就能够解释为什么在之前的工作中,我们的鸟瞰图拼接区域总是拼不齐,就是因为我们选择的角点远离拼接区域,计算出的投影矩阵H在拼接区域的投影误差太大。我们开发了一种基于自动提取角点算法的汽车标定方法,该方法可以提取标定布上拼接区域黑色方格的角点。如图所示:

拼接区域角点提取通过提取拼接区域的角点最终获得的全景鸟瞰图与前面工作的对比如下,左侧为以前的工作中提取棋盘格角点的方法且没有使用光流微调,右侧是我们提取拼接区域角点的拼接结果。差别就很大。
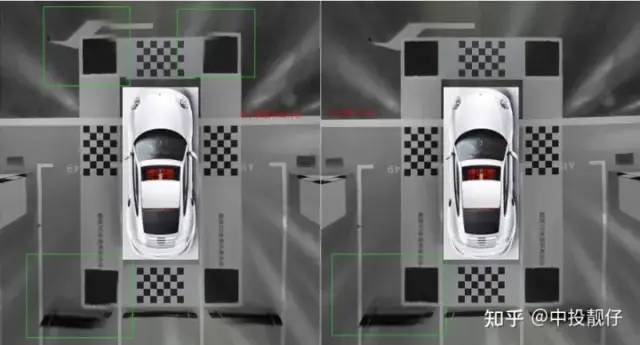
左:提取棋盘格角点 右:提取拼接区域角点再仔细想想这样做是很合理的,因为AVM产品中最影响驾驶体验的就是拼接区域的伪影,其他一切都好说。标定布的测量误差会导致单应矩阵计算不准确,这一问题是无法避免的,我们选择拼接区域的特征点计算单应矩阵,使得拼接区域的拼接结果非常准确。随之而来的可能是其他区域的不准确,例如贴近车身周围的棋盘格区域,但是这些区域用户并不care,虽然车身周围会引入些许误差,但只要车身与周围环境的的相对位置呈现的正确,不会引起碰撞事故,对于驾驶员来讲就是OK的。以上就是为什么我们要开发一种基于自动提取角点算法的汽车标定方法。
1.2 基于自动提取角点算法的汽车标定方法

标定场景对于标定布上的棋盘格,我们可以使用opencv的角点检测函数findChessboardCorners来提取,建议读者自行阅读该函数源码,我们提出的方法的思路就来源于这个算法。下面我们来简述我们提取大方格角点的方法:算法流程:
| 1. 双峰自适应阈值二值化 2. 多边形检测 3. 四边形筛选 4. 提取四边形顶点 |
·双峰自适应阈值二值化大体思路为:计算图像的亮度直方图。分别计算暗区局部极大值,亮区局部极大值,即“双峰”。计算双峰亮度的平均值,作为阈值,来对图像做二值化。因此称为“双峰自适应阈值”。

解释下这样做的理论基础:标定布上的大块黑色方格被白色布包围在中间,我们的目的是将标定布上的黑色方格与白色布通过某个阈值分割开。通常白色布的亮度值在直方图亮部阈值附近,黑色方块的亮度值在直方图暗部阈值附近。因此取两个亮度峰值取平均,一定可以将黑色方块与白色标定布分开。当然,光照条件不能过于恶劣,对于这一点即便是opencv提取棋盘格的方法也要限定光照条件。

基于自适应阈值的二值化·多边形检测以及四边形筛选约束条件
| 1. 多边形拟合结果必须为四边形,即筛选出二值化图中的四边形 2. 四边形面积必须大于某阈值(opencv源码中这个超参适用于筛选棋盘格的,我们要把这个阈值搞得大一些,用于筛选大方格) 3. 相邻边长不可相差过多 4. 选取黑色的四边形,而不是白色的四边形 5. 限制四边形分布范围,即四边形不能过于靠近图像边缘,具体情况与相机的位姿相关 |
·使用上述约束条件筛选出大方格的角点。综上,使用这种方法提取出的角点分布得更广泛,且都在鸟瞰图的分布区域,因此拼接融合得效果更佳。
二. AVM辅助视角——基于外参的视角变换
本章节主要讲述单应矩阵与PNP的原理,以及它们在AVM辅助视角中的实际应用,附带部分代码。关键词:单应矩阵、PNP、标定、广角、超广角、车轮视角、越野模式车载鱼眼相机可以获取到范围非常大的内容,但是鱼眼图像并不能够在汽车行驶过程中给驾驶员提供符合人类视觉习惯的视频图像,这一章节主要来讲述如何利用鱼眼相机的图像信息,来提供各种辅助视角。例如:(1)在进出车位或经过狭小空间时,驾驶员会更加关注车轮位置的内容,那么我们需要使用某种算法对左侧、右侧的鱼眼相机拍摄到的内容进行处理,得到“车轮视角”;

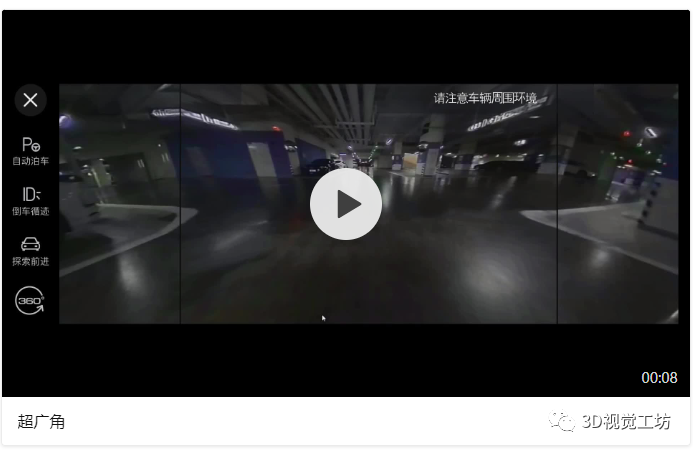
(2)对于正前方、正后方,我们提供了广角、超广角。超广角由前方鱼眼相机通过多次投影变换得到。
(3)左右视角根据不同的要求,我们提供三种不同的辅助视角
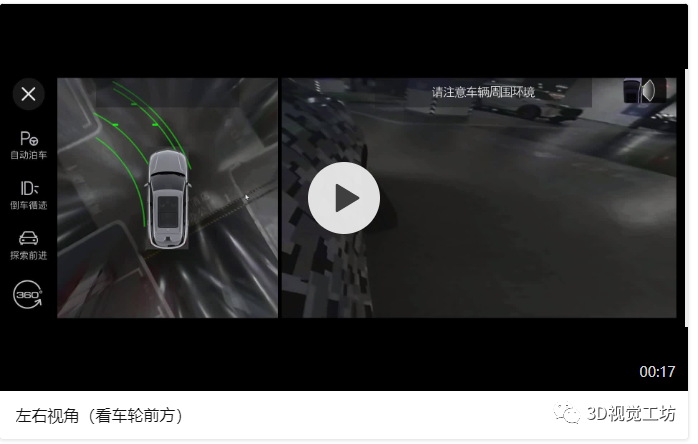

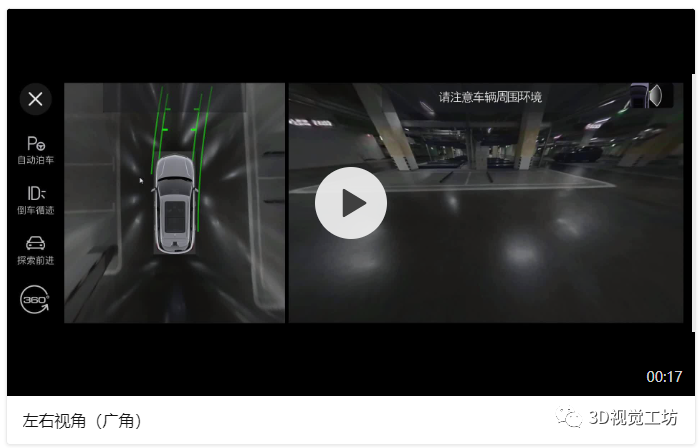
从以上的demo中不难看出,我们是通过投影变换的方法,将鱼眼相机的图像从本身相机部署的视角,转换为我们想要的视角。例如:对于车轮视角的demo,不难看出这个辅助视角中全部都是左、右两侧的鱼眼相机中的内容。已知这两个鱼眼相机A和B的位姿为:朝向左右两侧的地面;而我们实际想获取的车轮视角对应的相机a和b摆放位姿应该为朝向前方偏下,即朝向车轮的那个位置,这是两个虚拟的相机。那么如果我们通过标定+PNP的方法计算出右侧鸟瞰相机A与右侧虚拟相机a之间的位姿关系Rt,进一步地计算出A、a这两个不同位姿下拍摄某个平面(地面)时,他们之间的投影关系H,就可以将实际的鱼眼相机视角A转换为虚拟的车轮视角a。左侧鱼眼相机B视角与左侧虚拟车轮视角b同理。
2.1 单应矩阵H的原理
有CV基础的同学们大多知道单应矩阵表示“一个平面到另外一个平面的变换关系”。这样的描述是不准确的,或者如果对单应矩阵仅能说出这些,说明对单应矩阵的认识是片面的。正确的理解应该是:H描述的是在不同位姿下的两个相机cam1,cam2拍摄同一个平面(例如标定板),这个平面在两个相机成像平面上的成像结果之间的变换关系。投影变换模型图如下。以上这段话,被很多人简单理解成了“H描述的是两张图象之间的变换关系”,这里有两个点需要注意:(1)不要忽略掉了前面那部分和相机投影相关的物理模型(2)H描述的是空间中的某个平面分别在两个相机图像平面上的成像结果之间的变换,而不是两个图像之间的变换。对于单应矩阵,我们可以思考一个问题:我们拍摄到的内容,大多数情况下不仅仅包含某一个平面。而我们在做投影变换的时候,H就是基于某个平面计算出来的,这会导致虽然图像中的该平面部分的投影是合理的,但是因为平面以外的其他部分依然用相同的H做投影,这些部分的投影结果就会显得非常的奇怪。相信很多同学听说过一个结论:基于H的图像拼接方法,比较适用于视距较远的环境下。这是因为视距较远的环境下,拍摄到的景象我们可以近似认为它们在同一个平面上,那么我们基于这个平面计算出来的H,就几乎适用于整个图像中的内容。我们从最基础的相机物理模型来推导一遍单应矩阵H的公式,这样有利于我们更深入地理解。(本文仅推导这一个公式,通过物理模型对单应矩阵进行推导对后面的算法理解十分重要)如图所示,同一个相机在A,B两个位置以不同的位姿拍摄同一个平面:
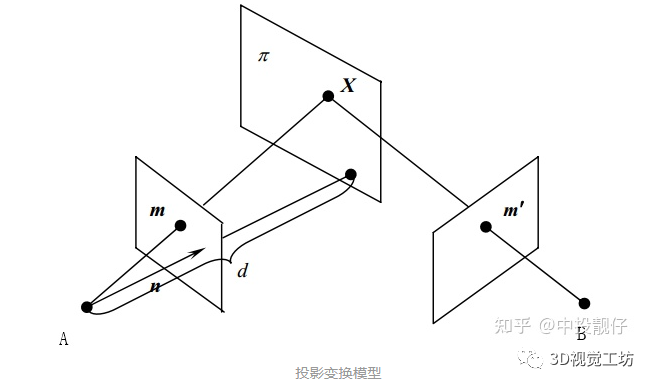
图中n表示穿过相机A的光心垂直于平面π的单位向量,d为相机A与平面π之间的距离。π平面上的点X分别投影到A、B相机平面上的m和m'上。X在A相机坐标系下坐标为X1,在B坐标系下坐标为X2。因此有:

假设相机A与B之间的相对位姿为R t,即旋转和平移,那么有:
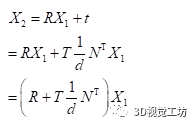
根据相机成像模型,其中K为相机内参,s1为某像素的实际深度
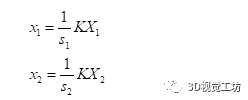
因此推导到最后,H结果为:
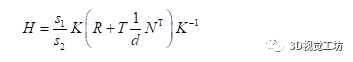
由于H有尺度不变性,因此
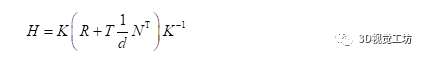
经过上述推导后我们可以得出结论:假设我们可以获取到两个相机之间的位姿关系R和t、相机的内参、相机与π平面之间的向量n和距离d,那么我们就可以计算出π平面在两个相机图像平面上的投影关系H。以上即为单应矩阵求解的一种方法(基于真实的物理模型),也是本章中AVM辅助视角所用到的方法。那么,如何才能获取到相机之间的位姿关系呢?我们用到了PNP的方法。
2.2 PNP的原理
用一句话概括PNP到底做了什么:已知相机A坐标系下的一组三维点,以及这组三维点在另外一个相机的图像坐标系下的二维坐标,就可以通过数学方法计算出A、B两个相机之间的位姿R,t。注意R,t是从A->B。公式如下:
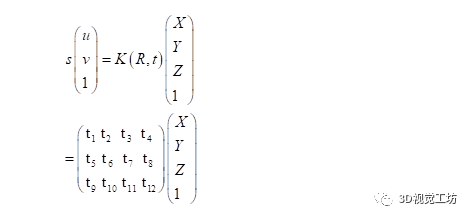
其中(X,Y,Z,1)为某一个相机坐标系下的三维点齐次坐标,(u,v)为另一个相机图像平面的二维坐标点。这两组点在真实世界中应该是一一对应的关系。K为相机内参,Rt为相机之间的外参。这个模型其实就是SLAM14讲中的单目相机物理模型,世界坐标系->相机坐标系->图像坐标系的过程。求解方法有“直接线性法”、“最小化重投影误差”等,我们就不展开来说了。针对于我们的AVM算法:先验信息必然是由标定布来提供的(即第一章中讲到的标定布上的大方格角点信息,包含图像上的二维坐标和标定的三维坐标)。虚拟相机的位置、朝向由我们自己设定,换句话说虚拟相机坐标系是根据不同功能(例如车轮视角、超广角等)由算法工程师自行设计的,因此我们是可以获取到标定布上的角点的三维坐标。二维点:图像中提取(1.1 1.2中已经讲述了提取方法)三维点:标定
2.3 车轮视角
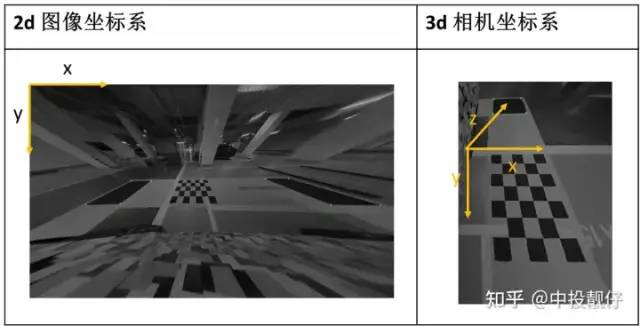
车轮视角算法坐标系示意图

车轮视角算法坐标系示意图2d图像坐标系没什么可说的,就是真实相机拍摄到的图像上黑色方格角点的坐标3d相机坐标系是一个虚拟的视角,模拟的是朝向正前方的一个视角,即y垂直地面,x垂直车身向右,z朝正前方由于我们已知标定布的全部尺寸参数,因此可获取虚拟相机坐标系下标定布上黑色方格角点的3维坐标。用PNP算法可以计算出实际相机与虚拟相机之间的位姿关系R,t。
//函数定义 void solveRtFromPnP(const vector &corners2D, const vector&obj3D, const Mat &intrinsic, Mat &R, Mat &t) { Mat r = Mat::zeros(3, 1, CV_32FC1); solvePnP(obj3D, corners2D, intrinsic, cv::Mat(), r, t); Rodrigues(r, R); } //函数调用 solveRtFromPnP(corners_2D, obj_3D, m_intrinsic_undis, R, t);以上,我们获取到了虚拟相机->真实部署相机之间的位姿R,t。至于R,t为什么不是从真实部署相机->虚拟相机,可以从PNP算法的公式推导中得知(前面已经讲过),或者见视觉SLAM第二版P180-P181。再回到投影变换H模型图中,图中的A就是虚拟相机,B就是真实部署相机。我们已经通过PNP计算出虚拟相机->真实部署相机的R,t。但是我们想要的是如何将真实相机拍摄到的某个平面(对于车轮视角而言是地面)通过H转换到虚拟相机的视角下。因此我们需要对R,t做一些处理,将其转化为真实部署相机->虚拟相机的位姿关系:公式推导:

代码:求解单应矩阵:
//基于Rt计算H Mat solveHFromRt(const Mat &R, const Mat &t, const float d, const Mat &n, const Mat &intrinsic) { Mat intrinsic_inverse; invert(intrinsic, intrinsic_inverse, DECOMP_LU); Mat H = intrinsic * (R + t / d * n.t()) * intrinsic_inverse; return H; }PNP求解外参:
/****************************************************************************************************************/ //R t:PNP算出的结果,从虚拟相机->真实部署相机的位姿 //计算出 真实部署相机->虚拟相机的位姿 Mat R_Camera2Real; invert(R, R_Real2Virtual, DECOMP_LU); Mat t_Real2Virtual = -R_Real2Virtual * t; //虚拟相机到地面的垂直单位向量 Mat n = (Mat_(3, 1) << 0, 1, 0); //真实部署相机到地面的垂直单位向量 n = R * n; // rotation float theta_X = m_wheel_sight_angle / 180.f * 3.14f; Mat R_virtual = (Mat_(3, 3) << 1, 0, 0, 0, cos(theta_X), -sin(theta_X), 0, sin(theta_X), cos(theta_X)); R_Camera2Virtual = R_virtual * R_Camera2Virtual; t_Camera2Virtual = R_virtual * t_Camera2Virtual; //计算单应矩阵H:真实视角->虚拟视角 Mat H = solveHFromRt(R_Camera2Virtual, t_Camera2Virtual, d, n, intrinsic);几点说明:·n(0,1,0),说明单应矩阵选取的平面为地面。不要忘了我们最开始强调的,H描述的是在不同位姿下的两个相机cam1,cam2拍摄同一个平面(例如标定板),这个平面在两个相机成像平面上的成像结果之间的变换关系。因此这个平面的选择,对最终的投影结果有很大的影响。车轮视角选取地面作为我们要进行投影的平面,最终的效果非常nice。·代码中还包含rotation部分,这是因为我们在标定的时候让虚拟相机朝正前方,但显然理想的车轮视角相机应该朝向车轮,即应加一个俯仰角pitch。
2.4 超级广角
这部分我们是对标现有某德系车载超广角功能进行实现的,相比于直接做去畸变的广角效果,超广角的优势在于·纠正了相机翻滚角带来的视觉不适·纠正了左右两侧远离图像中心的拉伸效果·纠正了竖直方向由于透视畸变“近大远小”带来的柱体倾斜效果 大部分车上的广角功能是对鱼眼图直接做了去畸变,这种方法带来的问题及产生原因如下:·放大上表中普通广角图,不难发现标定布前边缘并不是平直的,它有一定的倾斜。这是因为相机有一个roll翻滚角,相当于人眼没有水平正视前方,而是歪着脑袋看前面。·在远离图像中心的位置,像素被严重拉伸,这是透视畸变的一种(见附录),会导致即便是我们把去畸变图的分辨率调整到非常大,在这张图像上依然不能看到FOV范围很大的内容,如图所示。
大部分车上的广角功能是对鱼眼图直接做了去畸变,这种方法带来的问题及产生原因如下:·放大上表中普通广角图,不难发现标定布前边缘并不是平直的,它有一定的倾斜。这是因为相机有一个roll翻滚角,相当于人眼没有水平正视前方,而是歪着脑袋看前面。·在远离图像中心的位置,像素被严重拉伸,这是透视畸变的一种(见附录),会导致即便是我们把去畸变图的分辨率调整到非常大,在这张图像上依然不能看到FOV范围很大的内容,如图所示。

远离图像中心的区域被严重拉伸这张图的分辨率已经很大,然而在图像的边缘像素跨度太大,图中左侧的黑色车辆被严重拉伸。也就是说同样一辆车,在图像的中心可能只需要100个像素来呈现(例如中间的白车),而在图像的边缘被拉伸的更长,可能需要1000个像素才能完全呈现出来,如果我们想要获取更大范围的视野,就需要超级大分辨率的图像。垂直地面的柱子是斜的:这是因为另外一种透视畸变(见附录),即”近大远小“。类似于平行的车道线在图像中会交于一点的原理。我们可以记住一个理论:只有垂直于相机光轴的那个平面上的平行线,在相机图像平面上的成像结果是平行的(类似于BEV视角);与光轴不垂直的平面上的平行线,在相机成像平面上肯定交于一点,即”近大远小”。对图像做去畸变之后,图中的柱子是斜的,因为我们的前置摄像头有pitch俯仰角,它的光轴超前下方,并非垂直于柱子所在的平面,即不垂直于汽车正前方的平面。解决方案:我们的思路是:首先通过位姿变换的方法将相机摆正(依然是虚拟相机的思想),从而消除“近大远小”的透视畸变和相机roll角带来的视觉不适,然后将图像分为左、中、右三部分,中间这部分的“拉伸”透视畸变较小;对两侧透视畸变较大的部分强制进行某种投影变换,减小拉伸效果。具体如下:·相机位姿矫正

相机位姿矫正示意图相机位姿矫正算法流程的思路依然是将 真实相机视角->虚拟相机视角,以正前方的相机为例,算法流程如下表:算法流程
| 1. 假设虚拟相机的位姿为朝向正前方,光轴与正前方的那面墙垂直,坐标系x、y、z如上表中“位姿校正的广角”所示 2. 标定出地面上那些角点在虚拟相机坐标系下的三维坐标 3. 在真实相机拍摄的图像中提取角点的图像坐标(实际上在第一章的标定过程中已经完成) 4. PNP计算虚拟相机->真实相机的位姿 RT 5. 计算真实相机->虚拟相机的位姿rt 6. 我们选定的是垂直于相机光轴的平面,计算这个平面从真实相机->虚拟相机的单应矩阵H,在我们的算法中,这个平面距离相机的距离d=10m,这是一个经验值。 |
这个流程与上面的车轮视角的算法流程几乎是相同的,所有的相机位姿变换导致的视角转换都可以用这个流程来实现。在上面的相机位姿矫正示意图中我们可以看到,垂直于地面的墙、柱子的倾斜问题都解决了。被我们用基于相机位姿矫正的单应变换强行掰正了。但是,这个图在远离图像中心的边缘依然存在严重的拉伸。导致即使图像的分辨率很大,我们可以看到的实际FOV范围依然很小。针对这个问题,再一次进行平面的单应变换。·平面单应变换
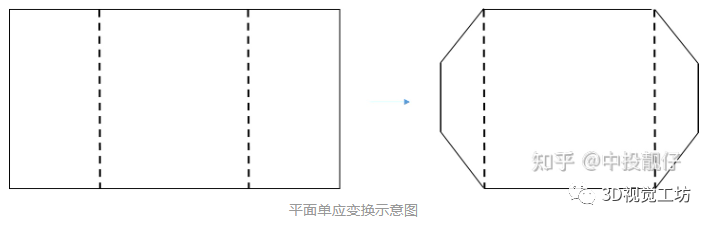
 广角与超广角实际的实现方法如下图所示,在广角图像上选取4个点(即远离图像中心在图像左右两边的两个小长方形),并设置这四个点做投影变换的结果(这4个点是通过大量实验调试出的一组最优超参数),使用这四对匹配点计算单应矩阵H。即计算将小长方形压缩成梯形的单应矩阵H。
广角与超广角实际的实现方法如下图所示,在广角图像上选取4个点(即远离图像中心在图像左右两边的两个小长方形),并设置这四个点做投影变换的结果(这4个点是通过大量实验调试出的一组最优超参数),使用这四对匹配点计算单应矩阵H。即计算将小长方形压缩成梯形的单应矩阵H。

图像两侧的单应变换在图像两侧所进行的单应变换有将像素在x,y方向做压缩的效果,从一定程度上减小了透视畸变带来的拉伸问题。做了投影变换后,在相同幅面的图像中,我们可以看到更大范围的内容,即FOV更大,因此称为超广角。
Mat H_left = getPerspectiveTransform(p_src_left, p_dst_left); Mat H_right = getPerspectiveTransform(p_src_right, p_dst_right);
三. 基于外参的3D 纹理映射方法
单目相机是丢失了深度信息的,计算机图形学中经常会使用将纹理图映射到某个3D模型上的方法,呈现出一种伪3D的效果,即纹理映射。在AVM中,通常使用将相机捕捉到的图像当作纹理,以某种方式映射到 3D 碗状模型上以呈现出一种3D 环视的效果。下面详细讲述下算法实现:
3.1 3D模型
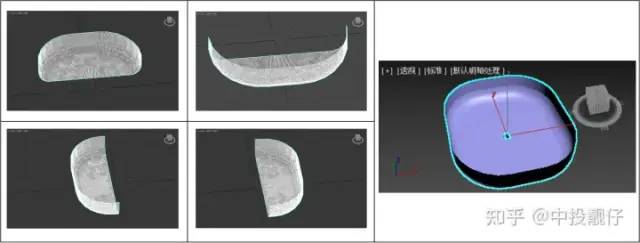
前、后、左、右
3.2 纹理映射
以前置相机为例,详细描述3D模型与相机图像之间的纹理映射关系:
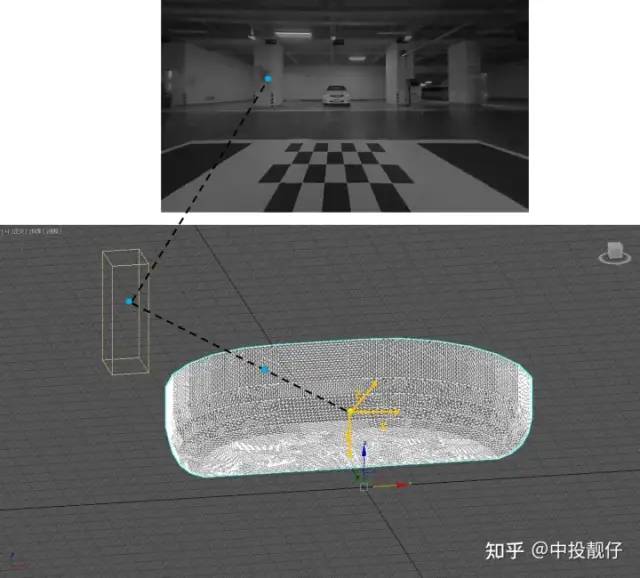
纹理映射示意图注意:世界坐标系、3dsmax坐标系、车身统一坐标系,这三个表达的是同一个意思。坐标原点在汽车中心,右手X,汽车前方Y,垂直地面向上Z。黄色坐标轴为前置相机坐标系。如图所示,3dsmax中的小长方体代表现实世界中在汽车正前方的柱子。该立柱上的一点(第二张图上长方体上的圆圈)通过相机成像模型穿过相机光心映射到成像平面上(即第一张图中柱子上的圆圈位置)。在成像过程中,同时也要穿越我们的3D碗模型。我们通过相机成像模型,可以想象这条光线的路径:现实世界中的物体->3D碗模型顶点->相机拍摄到的图像(去畸变后),也就是通过相机成像模型我们建立起了3D碗模型顶点与图像纹理之间的映射关系。我们通过3dsmax制作的 3D碗模型是一个OBJ文件,解析出来的是3dsmax坐标系下的坐标。我们需要将其转换到相机坐标系下,才可以进行上面说的纹理映射。3dsmax是以汽车的中心为原点,右手为X,前向为Y,垂直地平面向上为Z的,在标定过程中,我们可以获取上图中角点在3dsmax坐标系下的3维坐标;且可以在前置相机图像中通过算法提取角点的图像坐标,因此3dsmax与相机之间的位姿关系,同样可以通过PNP计算。代码如下:
//calculate pose solveRtFromPnP(img_corners, obj_corners, intrinsic_undis, R, t); //3dsmax->camera Mat pts_3DsMax = (Mat_ 融合区相邻两个3D 碗模型上存在重叠区,由于标定误差和avm 3d算法固有的误差,这部分重叠区域会有较严重的重影(下一节中会讲到)。因此需要用融合算法进行平滑过渡。具体算法可以参考文章[2] 融合算法示意图大体思路就是计算3d模型上的顶点与缝合线之间的角度,然后求一个比值,没什么太大难度。 在讨论这个问题之前,我们首先要理解相机坐标系。相机坐标系一般x为朝右,y为朝下,z为朝向正前方。图中标记的两个坐标系分别为汽车前置摄像头、左侧摄像头的位姿。一个安装在汽车前方朝向前下方,一个安装在汽车左侧后视镜朝向左下方。 AVM 3D病态问题现实世界中立柱上的一个点通过相机模型分别映射到前置相机、左侧相机的成像平面上从而生成图像img1,img2。在这个过程中会穿过重叠区的前3D碗模型的A点以及左3D碗模型的B点,AB显然不是同一个点。换句话说,img1和img2上相同的纹理(例如现实世界中的柱子)在纹理映射的过程中并没有映射到3d碗模型的同一个位置上,不能够准确地重合,且通常会在模型重叠区有较大的错位。因此,我们可以得出结论:AVM的3D是一种伪3D,是计算机图形学中使用将纹理图映射到3D模型上呈现3D效果的手段,但它不是真正的3D。根本原因是:单目相机模型丢失了深度信息。针对这种问题,通常的优化方法为:·将拼接缝位置设置在较不明显的位置上,例如靠近左右两侧。因为驾驶员开车的视觉习惯通常是正前方,左右两侧的内容不会过分关注。且在切换到其他视角的时候,拼接错位会被汽车模型挡住。·适当缩小拼接区范围·尽量让碗底大一些,让车身附近的地面有较好的拼接效果。3d碗的优化问题属于经验性的问题,需要通过实验慢慢调整适合自己的碗模型。 ·“近大远小”“近大远小”表达的是:同一个物体,在远处的位置投影到相机平面上的大小要小于在近处的位置。例如,车道线投影到图像上并不是平行线,会交于一点。下图中O为相机原点,Image plane为相机成像平面,parallel lines为现实世界中两条平行线。这两条平行线投影到image plane上,距离相机越远的位置,其间距投影到image plane上的长度越短,最后汇聚到一点,即“消失点”。这个现象就类似于我们对图像做去畸变后,汽车前方两个垂直的柱子在图像中是斜的,最终会交于一点。但是如果相机光轴垂直于地面,车道线在图像上的成像结果就是平行的,类似于BEV。所以,我们在做超广角功能的时候,要对相机做位姿矫正,使相机的光轴朝向正前方,这样得到的图像结果中柱子就不会倾斜。
1. 标定3dsmax坐标系下 标定布上角点的三维坐标。(即车身中心为原点的车身坐标系) 2. 检测相机拍摄到图像中标定布上角点的图像坐标。(第一章中已标定) 3. 利用1、2的坐标信息,通过PNP计算出 3dsmax坐标系与相机坐标系之间的位姿关系 R,t 4. 解析3d碗状模型的obj文件 5. 将解析出来的3d碗状模型的顶点三维坐标,通过R,t转换到相机坐标系下 6. 通过内参将相机坐标系的坐标转换到图像坐标系,建立起3d模型与相机图像之间的纹理映射关系 3.3 融合

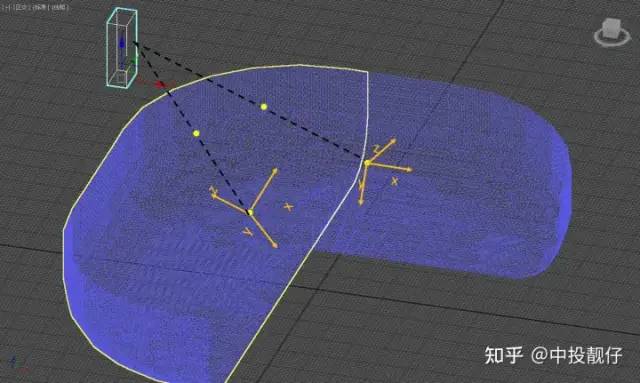
3.4 3D AVM算法存在的问题
四 附录
透视畸变
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。