距离城市道路通关,自动驾驶还差在哪?
“人们习惯将凡事分出黑与白,但很遗憾,现实全是灰色的。”刘慈欣笔下的这句话,恰恰也是自动驾驶行业的真实写照。两个流派,重感知和重地图,华山论道,暗流击水。只是眼下,尚没有一个最优解,让汽车彻底摆脱人类干预。
因为无论什么样的捷径,打造智慧的车都是必由之路。尤其当自动驾驶场景从高速延伸到城市道路,提高车端的感知与认知能力将变得愈发关键。
一方面,高度信息缺乏之余,地图始终在变化。举例来说,北京半年内道路拓扑变化约达到平均每百公里5.06处,广州市内改道施工平均一天能有两起,只有采集车不停采不停回传数据,才能保证地图的“鲜”度;另一方面,道路参与者无序且随机。除了车辆,行人、非机动车等不确定因素也成为自动驾驶进阶的一大考验。
小鹏汽车自动驾驶副总裁吴新宙曾直言,“和高速NGP相比,如果要拿一个数字作说明,城市NGP可能是百倍以上的困难程度。”但要实现自动驾驶规模量产,就必须通过城市道路这个关卡。
训练数据之“九九八十一难”
截止到目前,国内已有北京、重庆、武汉、深圳、广州、长沙等多个城市允许自动驾驶车辆在特定区域、特定时段进行商业化试运营。前不久,北京颁发了“无人化车外远程阶段”道路测试许可。
自动驾驶无人测试从“副驾有人”、“前排无人,后排有人”迈向第三阶段——“车外远程”。一个永恒主题是,利用源源不断的数据,打磨自动驾驶感知模型。模型决定了功能的上限,数据是源驱动力。而首要问题在于,如何以更低成本、更高效率获取更多有价值的训练数据?
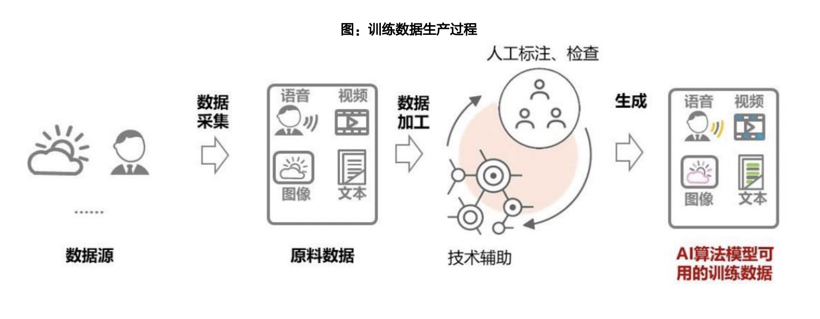
图片来源:天风证券
听起来或许有些不可思议,仅以数据标注为例,过去业内普遍做法是标注单帧2D图像,也就是每秒标注一帧,但真实视频每秒由10帧以上图像构成,换句话说,中间有很多空隙没有被标注,这部分也成了“白白浪费”的资源。
不仅如此,随着自动驾驶数据标注转移到4D空间(3D空间+时间维度),数据以一个Clip相当于包含了摄像头、传感器数据的短视频为最小标注单位,使得人工标注难度增大。
天风证券的研报显示,L3级别以上自动驾驶需要大量的3D点云数据支撑,不仅要求对传感器回传的数据进行实时处理分析,大量的弯道车道线、日积月累的消耗和损坏等带来的形状和反射率失真问题,也给识别的准确率带来极大挑战。
因此如果将这些离散帧扩充成Clip的形式,采用人工标注和返工的成本势必将垫高自动驾驶模型训练的开支。这也是,特斯拉从外包数据标注,到建立自己的人工标注团队、再到推进自动化标注的关键原因。国内车企如小鹏也打造了全自动标注系统,效率方面提高近4.5万倍,过去2000人一年的标注任务,现在只需16.7天左右就能完成。
除了车企,自动驾驶公司也在积极尝试,包括毫末智行在数据智能体系MANA的基础上,推出了视频自监督大模型。简单理解,利用图像掩膜对视频某些区域作屏蔽,给出上一帧,让模型猜下一帧,自主学习进行特征提取。

图片来源:毫末智行
接着再将带有完整标注的Clip给到该模型,进行微调。循环往复,基于深度学习算法提高模型的准确率和精度。通过视频自监督大模型,毫末智行降低了98%的Clip标注成本。同时鉴于服务器端跑的大模型具有更高的泛化性,训练完成部署在车端自动驾驶平台后,预测能力要更强一些。
不过仅有这些还不够,现阶段自动驾驶对于数据的渴望远远没有达到尽头,丰富的数据分布,是训练和优化自动驾驶感知模型的前提,没有之一。
对于打造自动驾驶系统来说,不论是采集车预先采集数据,还是量产车回灌数据,都存在较长的开发周期和不菲的成本问题。也因此,仿真技术被视为自动驾驶开发的加速器,受到业内广泛采用。通常自动驾驶系统在装车量产前,都需要经过大量的仿真测试。
然而毫末智行技术副总裁艾锐指出,从各传感器不同的特性来看,当前仿真技术还有很大的进步空间。比如,激光雷达底噪普遍低于毫末波雷达,二者对于雨雪雾等条件的要求也大不相同,导致同一场景下建模难度较高。
“好比看电影一样,CG动画即便做得再好,但仍能和真实场景区分开来。”相比于过分依赖仿真技术,毫米智行看中的是,用低成本的一般场景生成得到高成本的边缘场景(corner case)优势。
这也是毫末智行在3D重建大模型中引入了NeRF(Neural Radiance Fields)技术的根本原因。NeRF是一种3D重构技术,起步于2020年,凭借几张图片就可以合成360度全包围视角的特点,迅速风靡电商领域。

放到自动驾驶领域,NeRF不仅有助于重构场景数据,还可以做相应视角的调整。如此一来,便可以模拟极端路况的车辆行驶,实现对长尾场景的全面覆盖。除此之外,还可以模拟光线调整、夜晚效果等生成所需数据。
在增加NeRF生成的数据后,毫末智行将感知错误率在原基础上至少降低了30%。数据越多越好,关键不仅在纵向的“量”,更关乎横向的“丰富度”。面对数据这座大山,积累是唯一的出路。
特斯拉有百万车队,小鹏有十万车队,而毫末智行依托长城汽车的品牌规模,截止2022年底累计行驶里程已经突破2500万公里。搭载毫末HPilot系统的车型将近二十款,月度搭载增速超过200%。预计到2024年上半年,毫末将完成HPilot落地中国100个城市的计划。
自动驾驶“进城” 认知比感知难
从大数据里锻炼感知能力是自动驾驶目标实现的第一步。不止如此,清华大学教授邓志东在接受国内媒体采访时指出,自动驾驶核心技术难点之一是汽车如何理解复杂的动态驾驶场景(DDS),保证自动驾驶的安全性。
据其表示,人类驾驶是建立在认知理解基础之上,依靠可理解的视觉感知和大脑实现决策。相比之下,自动驾驶车辆很难在复杂动态环境中获得人类水平的驾驶知觉、预测与认知判决能力。
早些时候,毫末智行推出了基于transformer模型的环视感知算法(BEV),并逐渐应用于实际道路。但CEO顾维灏也指出,BEV方案上车后,对车道线和常见障碍物的检测效果相对不错,各种复杂工况下的探测范围和测量精度也有明显提升。但仍然遗留了一些比较困难的挑战,特别是视觉方案对城市道路多种多样异形障碍物的稳定检测问题。
一般有两种解决思路:扩大语义白名单。以识别轮胎为例,需要搜集大量的轮胎信息,扩充标注样本容量,这种方法往往要耗时费力;相比之下,更通用的方法或许可以事半功倍。即不需理解障碍物到底是什么,根据高度等信息判断若对通行有影响,就避让或者绕行。
毫末为此推出了多模态互监督大模型和动态环境大模型。前者是利用摄像头、激光雷达、毫米波雷达等传感器的不同特性,互相监督的方式进行通用障碍物或者通用结构的识别,后者有点类似视频自监督大模型,其目的是让系统增强感知能力。
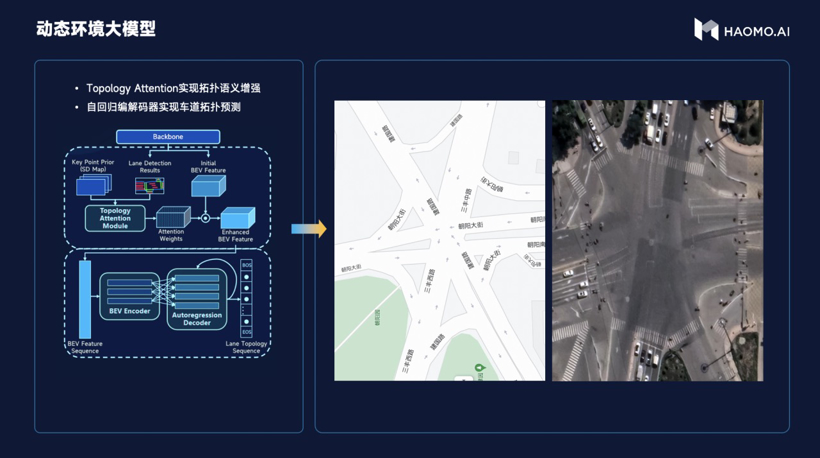
利用自回归编解码网络将BEV特征解码为结构化的拓扑点序列,实现车道拓扑预测。“让自动驾驶系统像人类一样,在标准地图的导航提示下实现对道路拓扑结构的实时推断。”尽管这是一个理想状态,但根据艾锐的说法,毫末接下来将致力于解决“二选一”的难题。如果地图导航的是明显有错误的路线,模型可以通过事先输入的地图先验信息,作出纠错改道判断。
不乏有观点指出,自动驾驶的下一战场将聚焦城市导航辅助驾驶功能。正如前文所述,城市道路的不断变化和随机的参与者构成,都对感知提出了更高要求,尤其城市路口的通过率已经成为城市导航辅助驾驶的最大难点。
在近日举办的 HAOMO AI DAY上,毫末智行也交出了首份成绩单,在河北保定和北京85%的路口拓扑预测上,其算法准确率高达95%。尽管对于一些小路、支路的判断还有待提升,但在城市NOH上,毫末算是首战告捷。
除了以上四个大模型,毫末还发布了人驾自监督认知大模型。与自动驾驶感知相比,用顾维灏的话说“认知更是业界难题。”尤其自动驾驶朝更高级别升级的过程中,决策规划将是核心能力,传统基于规则的认知算法已经进入瓶颈,已很难再取得突破。
一个突出问题是,由于相同场景不同司机的驾驶开法大不相同,完全基于大模型拟合海量的人驾数据,最终结果往往会倾向于拟合均值而不是最优值。也就是说,系统学到的并不是最佳开法,并且效果也不十分稳定。
全自动驾驶大范围落地的必要条件是具备足够的安全性,1%的失误都可能导致其无法落地应用。如何让机器更像人,确切地说是车技成熟且优秀的司机,是摆在自动驾驶决策规划面前的一个待解课题。
因而从ChatGPT的走红,毫末发现自动驾驶也可以借鉴人类反馈强化学习RLHF的训练方式,先从模型入手得到一个奖励模型(reward model),让其知道什么是好的开法,什么是不好的,以及哪些行为需要改进。
通俗地讲,绩效越高工资就越高,要想工资更高,绩效就得跟上。按照此方法,更容易培养出一个高质量模型。诸如在掉头、环岛等场景下,毫末可以将通过率提升30%以上。
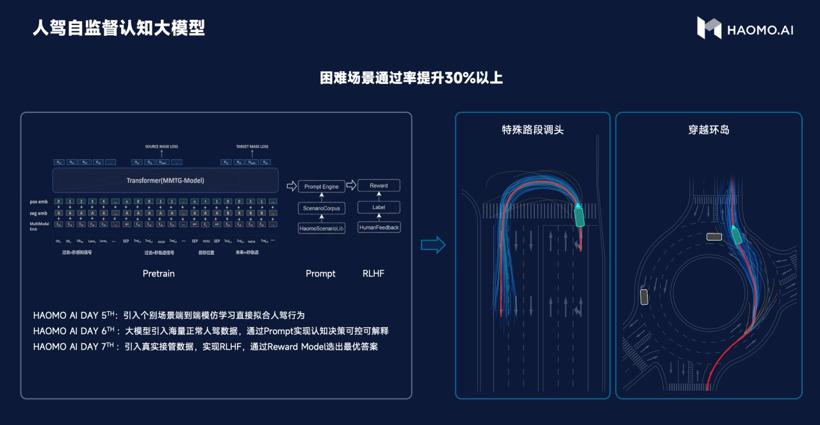
人的认知能力并非一朝一夕练就的,机器也一样,尽管有大量的科技手段可以加速迭代进程,但以卷积神经网络(CNN)、生成对抗网络(GANs)、深度强化学习(RL)等为代表的深度学习算法都需要数据和时间的积累才能形成一个逐步稳定的认知体系。
这也决定了,自动驾驶不仅是数据战,模型战,更是算力战。
算力的比拼不仅仅是堆GPU卡
在车端,大算力智能驾驶SoC卷出新高度,英伟达的Thor和高通Snapdragon Ride Flex的目标都涵盖了L5级市场。根据英特尔推算,全自动驾驶时代,单车每天可产生大约4000GB的数据量。
不仅如此,小鹏自动驾驶专家陈林在GTIC 2022全球自动驾驶峰会上也表示,相比高速NGP,城市NGP代码量大约提升6倍,感知模型的数量增加4倍,决策控制相关的代码量更是达到惊人的88倍。
如果采用单机训练AI算法模型,就需要276天才能完成,即使优化后的单机训练也要耗时32天。车端需要大算力芯片,云端训练模型更需要算力的支撑。
NVIDIA汽车数据中心业务总监陈晔之前就表示 ,如果这家车厂以自动驾驶或者科技为主打,那么超算中心将必不可少。在未来甚至会成为准入门槛。因为如果没有超算中心,就无法做软件的持续开发与迭代。
小鹏率先发布了智算中心“扶摇”,而在本届 HAOMO AI DAY上,毫末智行也联手火山引擎发布了自己的智算中心“雪湖·绿洲”(MANA OAISIS)。MANA OASIS的算力高达67亿亿次/秒,存储带宽可以达到2T/秒,通信带宽达到800G/秒。
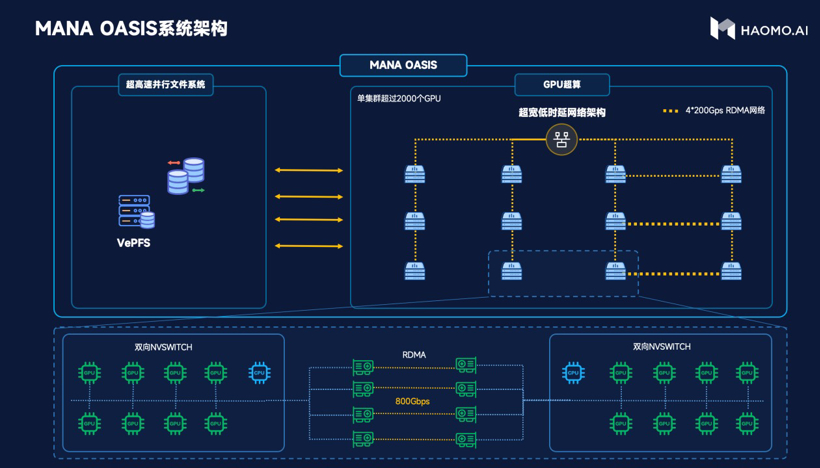
搭建自动驾驶模型训练所需的智算中心,不仅仅是堆服务器和GPU卡就能成。主要需求体现在以下几点:
-
算力。算力一定程度上能代表可以做什么大模型,能做多少大模型,以及能支持多少个AI工程师在这个“练武场”中进行训练;
-
存储效率。自动驾驶的数据是片段式的,最大特点是小文件多,达到百亿个。因此对这些小文件随机存储的效率,也代表着模型训练效率;
-
存储带宽。自动驾驶的大模型训练需要交换的数据颇多,这就要求有高性能的存储带宽(指单位时间里存储器所存取的信息量),这样大量的数据才能在大模型中顺畅流动;
-
通讯带宽。所有的这些计算能力不能在单台服务器中完成,需要多台服务器协同工作,这也就要求了集群的通讯带宽;
-
并行计算能力。自动驾驶所需要的模型,例如transformer,当变得很大的时候,就会稀疏,也就不要求有更好的并行计算框架,在训练时将硬件资源都利用起来;
创新能力。人工智能发展很快,新的算法层出不穷,这就要求车企和自动驾驶公司能够尽快引入新的技术和新的模型。
自动驾驶数据量不断累积,大模型复杂度不断提高,新车交付和创新周期却不断收窄,都对智算中心这个承载平台提出了更高要求。更为重要的是,自动驾驶未来的形态以及到底能达到怎样的高度,没有人知道。在真正的量产日前,唯有储备粮草建设营地,才能巧借东风。
结语
1886年,卡尔·本茨为他发明的三轮汽车“Motorwagen”申请了全球第一项汽车发明专利,之后汽车工业成为制造业的典范。不久的未来,电动化与智能化浪潮将颠覆整个汽车产业,不仅是自动驾驶,科技的属性将烙印在汽车行业滚滚向前的车轮上。而全无人驾驶时代,即将开启。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。