小鹏的自动驾驶芯片即将上车
蔚来、小鹏、理想都有自研自动驾驶芯片,其中蔚来速度最快,小鹏紧随其后并于2023年底已经拿到样片,2025年就能上车,理想也在紧锣密鼓展开。
小鹏大约在2021年一度想让英伟达定制芯片,据说是因为英伟达Orin的继任者Thor价格昂贵,可能近千美元,小鹏认为2000TOPS没有必要,750TOPS就足够。但汽车业务占整个英伟达收入不足5%,且在持续下降,可谓微不足道,英伟达主要精力都在数据中心领域,自然不可能为小鹏定制芯片。
这个说法可能有误,因为如果量很低的话,即便是750TOPS的定制芯片肯定比通用芯片Thor价格还要高很多。碰壁英伟达后,小鹏转向Marvell和索喜,Marvell是存储和宽带通信系统大厂,汽车以太网物理层和交换机全球第一,但自动驾驶芯片或者说SoC不是其专长。小鹏主要仰赖对象是索喜。
SOCIONEXT(索喜)成立于2015年,是富士通半导体与松下半导体影像成像及光网络部门合并而成,预计2024财年收入达2170亿日元,营业利润率大约14.5%。索喜收入主要有两类,一类是传统的产品销售收入,另一类就是non-recurring engineering简称NRE,即一次性项目开发收费,也叫一次性工程费用,也就是为小鹏这样的公司提供芯片开发服务的收入,NRE收入大约占索喜总收入的1/6-1/5。索喜的客户应该也包括Waymo和Cruise。
索喜最近11季度收入业务分布与营业利润
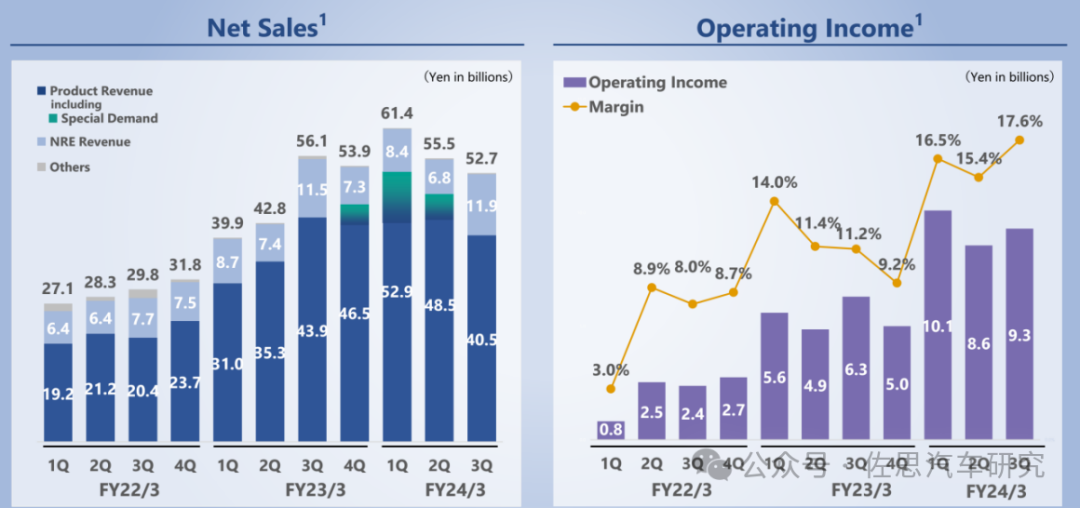
图片来源:索喜
索喜最近7季度NRE收入下游分布比例(汽车业务飞速增加)

图片来源:索喜
索喜最近7季度NRE收入客户地域分布
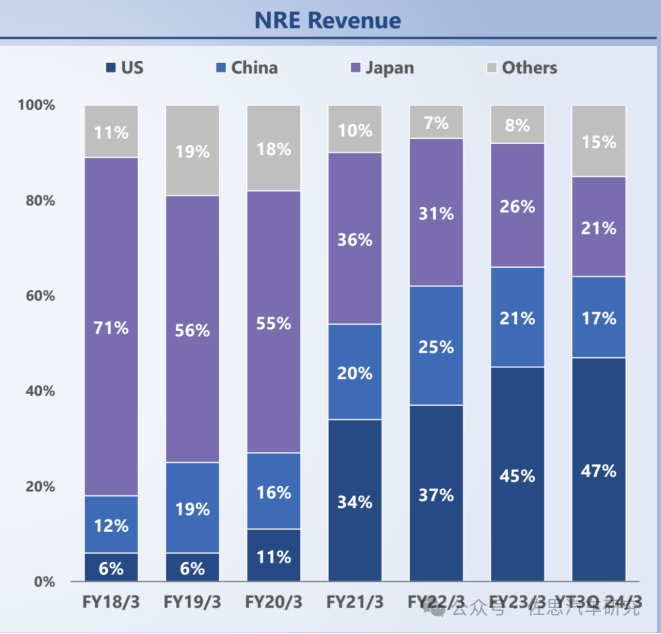
图片来源:索喜
上图中,中国客户占其收入的1/5左右,美国客户所占比例最高。
索喜7季度NRE收入制造工艺分布

注:制造工艺都非常先进,至少是7纳米,图片来源:索喜
索喜目前在手订单额分布

图片来源:索喜
目前汽车领域在手订单大约3000亿日元,主要是自动驾驶和HPC还有激光雷达、毫米波雷达、摄像头(应该是ISP)传感器芯片。
索喜定制SoC流程

图片来源:索喜
索喜定制汽车自动驾驶SoC框架图
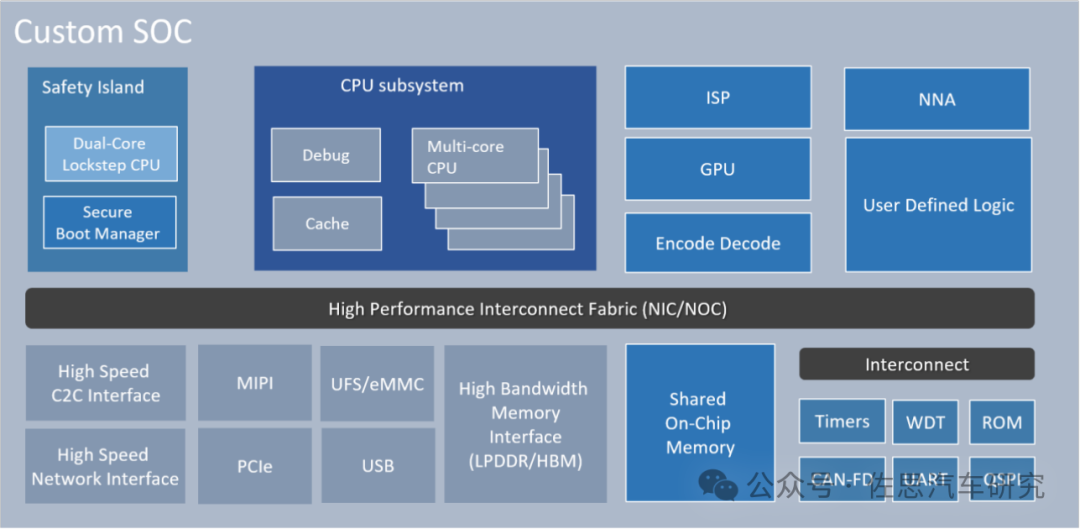
图片来源:索喜
目前,小鹏自动驾驶芯片没有任何公开信息,我们只能做一番推测。首先,制造工艺至少是5纳米或4纳米,3纳米则不大可能,一个是不够成熟,另一个是成本太高。CPU方面应该还是常见的ARM Cortex-A78AE,12核心或16核心,略微超过英伟达Orin。

图片来源:索喜
小鹏定制芯片应该近似于舱驾一体芯片,因为纯智能驾驶和座舱应用的界限非常模糊,所以GPU肯定有。GPU应该还是ARM,最大可能是MALI G77,11核心的G77,FP32算力是1130GFLOPs,也就是1.13TFLOPs,做8位整数AI运算时算力是4.52TFLOPS。ISP方面索喜自己就有足够的IP,相信不逊于蔚来的ISP。
接口方面,有汽车以太网霸主Marvell的参与,那以太网带宽应该达到10Gbps,PCIe至少是四代或5代,最高至少是32GB/s,会全面支持汽车以太网,包括SDV时代的10Base-T1。存储接口方面,最低应该也是LPDDR5X,也有可能是和特斯拉一样先进的GDDR6,索喜的合作伙伴CADENCE能够提供GDDR6的物理层和控制器IP。
HBM不大可能,虽然性能优秀,但价格太高了。存储带宽最低应该也与英伟达Orin的204GB/s看齐。
大家最关注的自然是AI部分,这部分小鹏可以自研,也可以直接购买第三者的IP。AI算力就是个文字游戏,统计口径差别巨大,没有统一的测试标准,基本上完全取决于厂家的宣传,因为无法证伪。
Transformer时代,AI算力数字意义不大,汽车领域的算力通常是整数8位精度下的算力,这种算力也只是针对传统CNN当中计算量最大的卷积运算,这种算力的取得不需要任何技术门槛,简单堆砌MAC(乘积累加)阵列即可获得,第三方IP都不需要。不计成本的话,任何厂家都可以取得数千TOPS的算力,但每个厂家有自己的市场定位,有成本考量, 自然就有了算力的高低。
AI芯片严格地说AI加速器和GPU都是针对并行计算设计的,在CNN时代非常合适,但在后CNN时代,出现了很多串行计算,对AI加速器非常不友好,对CPU和DSP非常友好,例如非极大值抑制(NMS)。Transformer就是如此,它不仅需要串行计算算力,还需要足够的存储带宽支持,单纯的AI算力数值在Transformer面前毫无意义。实际不仅Transformer,很多CNN的变种亦是如此,如目前主流的YOLOV4、YOLOV5、RESNET50。
我们把AI算子分为串行型和并行型,其中串行型通常都是逐点元素型element-wise,矢量与矩阵之间的运算,它有两个特点,一是通常是串行运算,二是有大量的存储数据动作,非常消耗存储带宽。它们对AI算力需求很低,但对存储速度和CPU算力要求很高,最适合此类运算的是DSP,因为DSP是哈佛架构,数据和指令总线分开,效率高。但DSP编译器非常难搞,只能用在汽车这种封闭体系内。针对并行计算的GPU和AI芯片不适合此类逐点运算,遇到此类计算,通常都是退回到CPU中运算,这也是为何英伟达和微软都要费尽心机自研CPU的主要原因。
Transformer的计算过程
在这个计算过程中,矩阵乘法是典型的计算密集型算子,也叫GEMM,即通用矩阵乘法。存储密集型算子分两种:一种是矢量或张量的神经激活,多非线性运算,也叫GEMV,即通用矩阵矢量乘法;另一种是上面说的逐点元素型element-wise。
推测小鹏自动驾驶芯片的AI部分架构如上图,当然FP16的阵列可以去掉,这种设计既有标量运算单元,也有矢量运算单元,保证了足够的灵活性,能够适应算法的大幅度变化。SRAM的容量可能只有1MiB,8MiB的成本太高。INT8阵列16384个MAC,算力大约800TOPS,频率高点可以做到近1000TOPS。
自己开发芯片因为量比较低,成本肯定远高于英伟达的Orin,而独立开发芯片主要是为了整个自动驾驶闭环,完全掌控自动驾驶灵魂,提高科技含量,推高市值,加快产品迭代。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。