本文来自“2024车载SoC芯片产业分析报告”,随着汽车智能化水平的提升,整车EE架构已经由以前的分布式ECU架构升级到集中式域控制器架构,并继续向中央集成式架构方向演进。在分布式ECU架构阶段,MCU是计算和控制的核心;
在集中式域控制器架构阶段,传统MCU芯片已经无法满足大量异构数据的吞吐能力和更快的数据处理能力的需求,因此,数据传输效率更高、算力更大的SoC 芯片便成为域控制器主控芯片的必然选择。
1 车载 SoC 芯片定义
1)基础定义
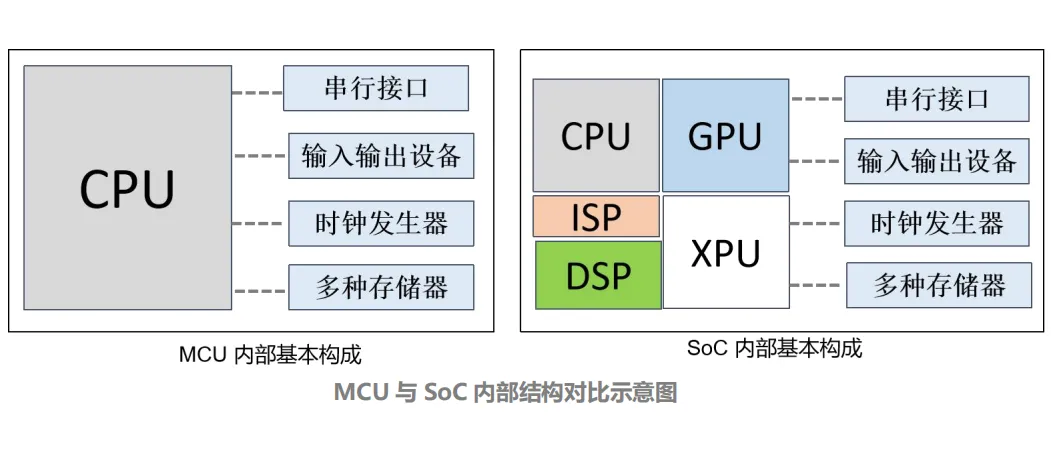
车规级计算芯片按集成规模可以分为MCU和SoC两类。其中,MCU也被称之为“单片机芯片”,内部集成有处理器、存储器、输入/输出接口和其他外设,常应用于控制任务简单、实时性较高的嵌入式系统。车载MCU常跑的操作系统有AUTOSAR CP和FreeRTOS,通常不支持运行高复杂度的操作系统。
SoC芯片为系统级芯片,相比MCU,内部集成更多的异构处理单元,结构设计更为复杂,处理和计算能力也更强,适用于多任务处理以及计算任务更复杂的应用场景。车载SoC可以跑更复杂的操作系统,包括QNX、Linux、Andriod和AUTOSAR AP等。
2)硬件构成
车载 SoC 芯片内部通常包括以下几大模块:处理器、存储器、外设 I/O 等。
A.处理器 —— 车载 SoC 芯片内部的处理器通常包括以下几种单元模块:
通用逻辑运算单元:通常基于 CPU 来实现,主要负责一些逻辑运算任务,用于管理软硬件资源,完成任务调度和外部资源访问等,实现系统层面的功能逻辑、诊断逻辑以及影子模式数据挖掘功能等。一些典型的应用包括:基于优化的决策规划算法、车辆控制算法等。
AI 加速单元:通常是基于 NPU 这类的神经网络处理器来实现,承担大规模浮点数并行计算需求;作为神经网络算法的加速器,主要负责处理 AI 方面的计算需求。
图像/视频处理单元:通常基于DSP、ISP、GPU等处理器来实现。ISP作为视觉处理芯片,其主要功能是对摄像头输出的图像信号做调校,包括 AE(自动曝光)、AF(自动对焦)、AWB(自动白平衡)、图像去噪等;DSP是一种具有特殊结构的微处理器,相比于通用CPU,它更适用于计算密集度高的处理工作,典型的应用包括:传统的CV图像处理、一些自定义算子的加速处理等;GPU具有较强的浮点运算能力,主要用于图像的 3D渲染和拼接等应用。
硬件安全模块HSM:用于为应用程序提供加解密服务,管理敏感信息和资产,保护加密密钥等。
Satety MCU:主要用于实时监控 SoC 内部各硬件模块的状态和通信,以及在其出现问题后能够及时报错,进而确保整个系统的功能安全性。
B. 内部存储器:包括易失性存储器和非易失性存储器两大类。
易失性存储器:存储器在断电的情况下(比如,系统正常关闭或意外关闭时),数据会丢失,即无法继续保留存储数据。它主要用于临时存储正在处理的程序和数据,车载 SoC 内部常用的存储器类型包括 SRAM 和 DRAM(DDR,LPDDR 等)等。
非易失性存储器:在断电情况下,依然能够保存存储数据。它主要是用来存放固定数据、固件程序等一般不需要经常改动的数据。车载 SoC 内部常用的存储器类型包括 NAND Flash(eMMC、UFS 等) 和 Nor Flash 等。
C 外设 I/O:包括通用数据接口、摄像头信号接口、音频接口和显示器接口等。
-
通用的数据接口:PCIe、LVDS、USB、SATA、CAN/CAN-FD、以太网等 -
摄像头信号接口:MIPI-CSI-2、GMSL、FPD Link等 -
音频接口:I2S、TDM、SPDIP等 -
显示器接口:DP、HDMI等
2 车载 SoC 芯片性能要求
1)重要参数指标
衡量车载 SoC 芯片的性能,需要从 AI 算力、CPU 算力、GPU 算力、存储带宽、功耗、制造工艺等多个维度进行综合考量。
a. AI 算力 : 通常是指 MAC 指令(乘积累加)的运算能力。MAC 指令操作本身与数据类型强相关,在不同数据精度条件下,测出的 AI 算力会存在比较大的差别。企业平时宣称的算力一般是指该芯片运算能力的理论峰值,单位用 TOPS 来表示,一般默认是以 Int8 作为算力量化标准。
但我们也不能只看表面的理论算力数值。在特定使用场景下,大家更关心的是芯片真正的有效算力是多少,即芯片的“算力利用率”。以智能驾驶应用为例,SoC 芯片的实际算力利用率会因为图片分辨率、网络结构差异等原因而有所不同。
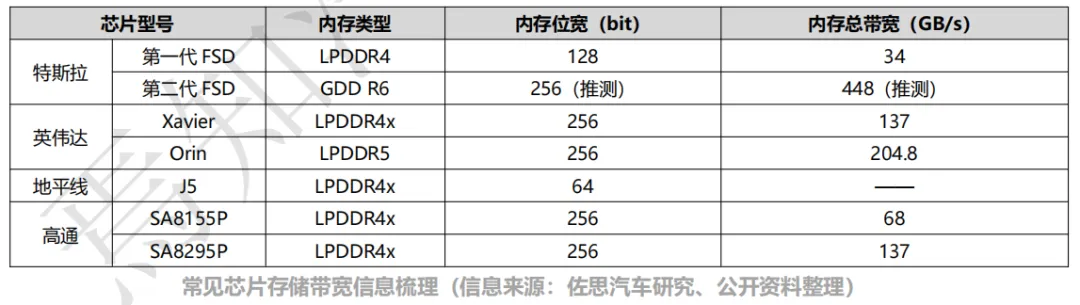
b. 存储带宽:数据在处理过程中需要不断地从存储器单元“读”数据到处理器单元中,处理完之后再将结果“写”回存储器单元。数据在存储器与处理器之间的频繁迁移将带来严重的传输功耗问题。有业内人士提出,AI 运算 90%的功耗和延迟都是由于数据搬运产生的。
芯片的存储带宽由两方面决定,一是存储器本身,二是芯片的内存通道数。存储带宽的大小决定数据搬运速度的快慢和搬运次数的多少。因此,存储系统带宽的大小在一定程度上也决定了芯片真实算力的大小。
c. 功耗: 包括动态功耗和静态功耗。动态功耗是因为信号值改变带来的功耗损失,由两部分组成:开关功耗和内部功耗。静态功耗是设备还在上电状态但是没有信号值改变时消耗的功率。
芯片的功耗与硬件架构、布局布线、工艺制程、算力大小等因素都有关系。其它条件相同的情况下,采用的工艺制程越先进,芯片的功耗就越低;同理,算力越大的芯片,功耗也会越大。功耗过大意味着会产生更大的散热,可能必需安装水冷系统,从而增加整体 BOM 成本。
2)车规级要求
按照日常生活中的应用场景进行划分,芯片大致可分为消费级、工业级、车规级三大类。应用场景不同,芯片在设计、生产、认证等环节的目标设定和实现手段上都会存在区别。相比于消费级和工业级,车规级芯片的工作环境更恶劣、出错容忍率更低、使用寿命要求更长、供货生命周期更久等等。
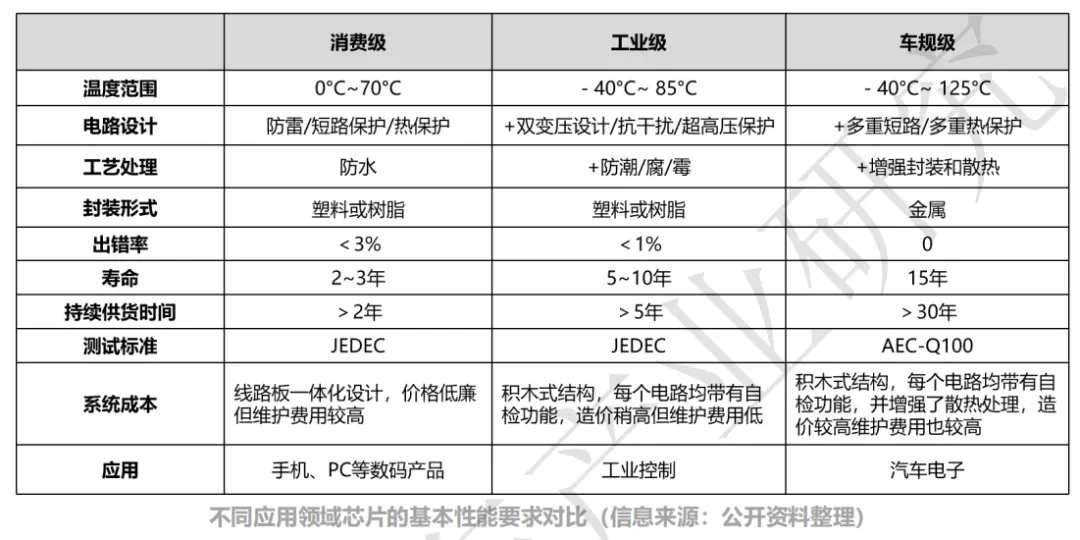
整体来看,车规级芯片具有高可靠性、高安全性和高稳定性的特点。车载芯片需要经过一系列严格的测试认证,确保其达到车规级的相关要求,方可投入到量产。芯片车规认证标准通常包括以下三个维度的管控:质量管理体系认证 IATF16949、可靠性标准 AEC-Q100 和功能安全标准 ISO 26262。
目前,主流车载 SoC 芯片的架构仍然沿用了传统的冯·诺依曼模型。在冯·诺依曼架构中,数据存储单元与数据处理单元两者相互分离。数据在处理过程将会在处理器与存储器之间不断地进行“搬运”。
据相关数据显示,处理器性能以每 2 年 3.1 倍的速度增长,而内存性能以每 2 年 1.4 倍的速度提升。计算能力与带宽能力之间的差距将会越拉越大,这就导致芯片的内存容量和数据传输速度难以跟上芯片的计算速度。因此,车载 SoC 的性能与效率的发挥将受到严重制约,进而出现“存储墙”问题。
以 Transformer 架构为基础的 AI 大模型导致了模型参数量激增,短短两年间模型大小扩大了惊人的 410 倍,运算量更是激增了高达 750 倍。虽然现阶段基于 Transformer 架构的真正大模型还很难“上车”,但是,相比 CNN 模型,已经上车的 Transformer 模型参数也要更多,算子复杂度更高,需要的运算量更大。因此,Transformer 网络对于车载 SoC 芯片内部 SRAM 的利用率,以及内部总线突发大带宽访问等方面提出了更高的要求。
地平线 J6 内部采用全新的存储系统设计,片上包括 L0M、L1M、L2M,共三级存储系统,用于数据缓冲和交换。同时,先进的总线架构配合高带宽的 DDR,可有效缓解内存墙的问题。
在 AI 加速器的架构设计上,安霸的 CV3 系列芯片推出了第三代 CVflow 架构。与传统的缓存系统不同,CVflow 架构采取了一种创新的策略,将片上内存(On-chip Memory)分割成多个不同大小的内存块,这些内存块被称为 Partial Buffers(PB)。这些 PB 的主要用途是存储计算过程中的中间结果,从而显著减少对外部 DRAM 的访问次数。
再往后发展,智能座舱将进一步整合 L2 级别的行车 ADAS 功能,甚至是更高阶的自动驾驶功能,即所谓的“舱驾一体”。从“舱驾一体”的实现形式上来看,主要有三种:One Box、One Board 和One Chip。特斯拉采用了 One Box 的方案,并在 2019 年实现量产。One Board 和 One Chip 的方案也有相关企业正在规划,据透露,One Chip 的方案可能将会在 2025 年左右量产。
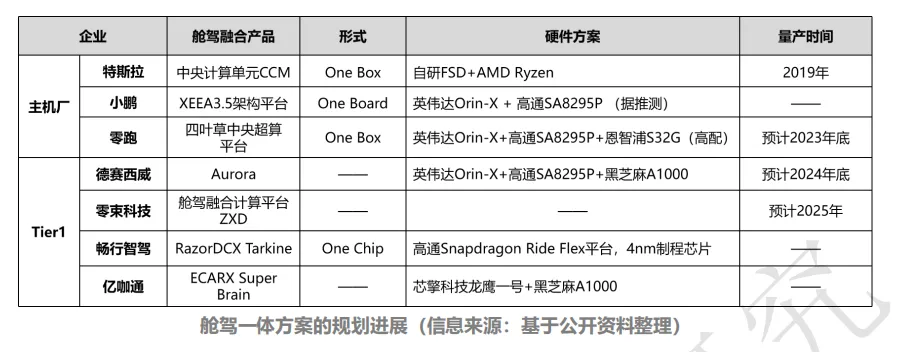
多数业内人士一致认为,One Chip 方案才是真正的“舱驾一体”,能够帮助企业实现降本增效。整体来看,舱驾一体的主要优势表现在:
系统成本更优:在硬件层面,相比于多 SoC 方案,单 SoC 芯片方案集成度更高,使用物料更少,在一定程度上节省了 BOM 成本;在软件层面,所有软件都在统一的软件架构下,能够节约开发验证和功能扩展成本。
系统响应更快:相比板间的 Switch 通讯或芯片间的 PCIE 互联,在芯片内部直接使用内存共享的片内通讯方式,通讯时延会更短,系统响应更快。
OTA 升级更容易:舱驾融合后,平台的集成度更高,软件合理分层分区,有利于新功能的部署和更新。









