如何利用动态车辆施加的运动约束改进视觉定位?
I. 摘要
大多数6自由度定位和SLAM系统使用静态地标,因为它们无法有效地将动态目标纳入典型的过程中,所以会选择忽略动态目标。在已经纳入动态目标的情况下,典型方法试图对这些目标进行相对复杂的识别和定位,从而限制鲁棒性或通用性。在这项研究中,我们提出了一种中间方案,并使用自动驾驶车辆,在动态车辆提供有限的姿态约束信息,应用于基于逐帧PnP-RANSAC的6自由度定位过程中。我们使用运动模型对初始姿态估计进行更新,并提出了一种计算未来姿态估计质量的预测方法,该方法根据自主车辆的运动是否受到环境中动态车辆帧对帧相对位置的约束而触发。与最先进的单图像PnP方法及其虚构姿态滤波相比,我们的方法可检测和识别合适的动态车辆,以定义这些姿态约束来修改姿态滤波,从而在0.25米至5米的定位公差范围内提高召回率。我们的约束检测系统在Ford AV数据集上约35%的时间内是活动的,当约束检测处于活动状态时,尤其是定位得到了改善。
II. 引言
为了使自动驾驶车辆安全有效地行驶,准确的定位至关重要,位置精度要求在10-20cm的数量级。行业目前的解决方案通常使用GPS(全球定位系统)、INS(惯性导航系统)和激光雷达的多传感器融合,使用扩展卡尔曼滤波器等技术进行处理。使用摄像头的6自由度视觉定位提供了一种替代方法,在自动驾驶场景中可以实现高精度定位,并具有减少对昂贵激光雷达传感器的依赖,并提供额外的定位冗余。目前最先进的基于特征的可视化定位方法按帧提供定位估计值,容易因三维重建或特征描述和关联不准确而出现故障。
在这项工作中,我们提出了一种使用触发约束运动模型来完善帧到帧姿态估计的方法,该模型考虑了环境中动态车辆的相对位置(只要可用)。我们建议利用动态车辆检测(通常已在AV自主堆栈中出于其他目的执行)作为定位流水线中有限但仍然有益的信息来源。为此,我们考虑对从单幅图像获得的6自由度姿态进行顺序过滤,基于PnP-RANSAC进行可视化定位,并通过提出的动态车辆运动约束改进过滤器的姿态预测。我们重新使用来自定位过程的局部特征和来自AV感知过程的语义分割掩码来生成车辆描述符,我们使用这些描述符来比较连续图像中的动态车辆,以确定它们相对于自主自我车辆的相对位置是否恒定。如果它们的相对位置随着时间的推移是恒定的,我们就近似认为自主车辆的速度和航向也是恒定的,因此是受约束的。然后,在扩展卡尔曼滤波传感器融合系统的基础上,只要有外部姿态约束信息,我们就使用这些信息来修改姿态估计值对滤波器逐帧定位状态的贡献。
我们在Ford AV数据集的42公里驾驶中实验性地验证了我们的方法,该数据集划分为247段长度为150米的不同段,涵盖各种交通条件、道路类型(高速公路、郊区)和时间。
III. 相关工作
在这一节中,我们回顾了最近有关使用语义目标检测、跟踪和姿态约束的6自由度视觉定位研究。
A. 6自由度视觉定位
6自由度视觉定位是在给定先验三维地图和查询图像的情况下估计相机绝对姿态的任务。这是一个具有挑战性的研究问题,特别是对于自动驾驶车辆的长期和连续运行,因为与数据库图像相比,查询图像可能会发生显著的外观和视角变化。近年来,研究人员探索了不同的方法来解决这些问题,其中包括学习健壮的局部特征、平面、匹配器和全局描述符,利用序列信息,改进2D-3D匹配,以及结合语义和几何。在场景坐标回归、鲁棒性姿态估计和直接图像/特征配准方面也开发了基于学习的方法。在这项工作中,我们使用Kapture和HLoc实现了基于特征的视觉定位过程,并利用场景中的动态车辆改进了定位--这是对上述该领域最新创新的补充。
B. 定位和语义场景理解
目前已有几种方法将语义分割和物体检测纳入视觉地点识别和6自由度度量定位流水线。这包括使用Faster-RCNN构建对象图或对象匹配;分割特定对象/实体(如建筑物、车道和天际线)以提高识别率;或预选多个对象类别。特别是对于6-自由度定位,在粒子过滤器或P3P-RANSAC循环中采用了三维点及其在查询图像上的投影之间的语义标签一致性,以改进姿态估计。在所有这些方法中,要么假定动态物体在定位过程中无用并因此被移除,要么此类物体在SfM重建过程中不构成三维地图的一部分。在这项工作中,我们将探索如何利用这些动态物体来改进度量定位。
C. 定位和目标跟踪
物体跟踪在增强现实、动作识别和自动驾驶车辆的路径规划等多个相关领域都有应用。研究人员还将(自我-车辆)定位和动态物体跟踪结合起来,前者为后者提供信息; 后者为前者提供信息; 或者两者共同建模以完成映射任务。
D. 基于约束的相机姿态估计
目前有几种方法利用额外信息约束相机姿态估计。这包括语义组件和三维点云之间的距离约束、利用重力方向和摄像头高度、点和线的组合约束、使用地理参考交通标志、基于环境-物体距离的约束和镜面反射。然而,这些研究的具体方法因应用环境和附加信息的假设而存在很大差异。与这些方法不同,考虑到自动驾驶应用,我们提出使用基于动态车辆相对于自我车辆运动的速度约束来改进自我车辆定位。
IV. 方法
本节首先描述我们方法的关键思想,然后描述系统中使用的概念。之后,我们介绍了提出的算法,该算法使用动态车辆施加的运动约束改进姿态滤波。我们方法的流程如下图所示:
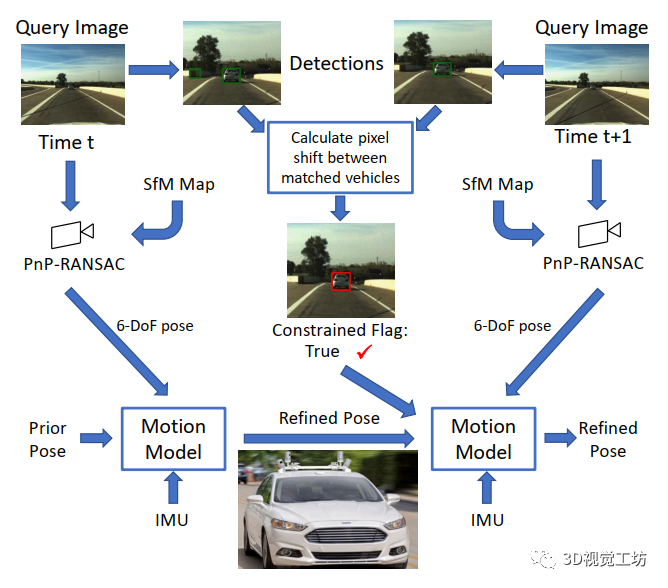
在这项工作中,我们思索是否可以通过考虑在自我车辆前方移动的外部动态车辆的运动来提高自主车辆的定位性能,将这些车辆作为姿态约束。我们提出了以下简单的约束定义:如果动态车辆的二维像素位置在连续两幅图像之间没有变化,那么我们假设自我车辆和动态车辆的相对位置是恒定的。此外,我们还可以近似认为速度和航向在这段时间内也是恒定的。这使我们能够创建一个条件算法,以检测动态车辆在图像平面中的位置是否静止,并根据该条件调整非符合人体工程学的运动约束;在没有约束的情况下,姿态滤波器按原样运行。这种约束定义虽然简单,但其优点是不需要其他方法所需的复杂检测、物体姿态估计和跟踪机制:而且我们能够在真实世界的视听相关实验中评估其实际效果。
A. SfM视觉定位过程
我们提出的运动约束姿态滤波方法与单幅图像6自由度姿态的确切来源无关,因此可以使用任何现有的单幅图像视觉定位方法。我们选择了使用局部特征的视觉定位过程HLoc 与R2D2 局部特征,因为我们重新使用这些特征进行运动约束检测。HLoc使用PyCOLMAP 进行SfM重建和PnP-RANSAC估计单幅图像的3D姿态,我们在顺序滤波器中使用它,如下后文所述。
B. 使用IMU的EKF姿态优化-基线系统
我们使用自行车模型对自动驾驶车辆建模,并实现了6自由度误差状态EKF滤波器与运动模型相结合来滤波估计的逐帧姿态。我们还假设自动驾驶平台具有IMU(惯性测量单元),并将IMU读数集成到EKF中。IMU数据包括线加速度(Ia)和角速度(Iv),其状态向量为:

EKF的预测更新如下:
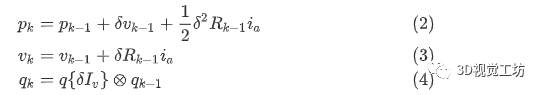
其中,δ是滤波器连续迭代之间的时间差异;是车辆当前取向的旋转矩阵;,, 是我们滤波器的三个状态变量,分别表示x,y,z位置,速度和四元数。滤波器相对于图像时间戳运行,并且IMU向量是通过在捕获图像的时间戳处数值积分原始IMU数据来计算的。按照,我们使用符号⊗表示四元数乘法,q{}表示从旋转向量到四元数表示的变换。
我们计算过程雅可比矩阵如下:
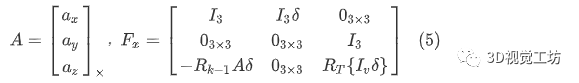
其中,表示角轴表示的旋转矩阵表示,表示作为反对称矩阵的向量。过程噪声雅可比矩阵通过过程方差定义:
协方差和卡尔曼增益更新如下:
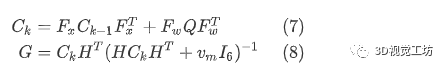
其中,和分别表示运动模型噪声和测量模型的雅可白矩阵:
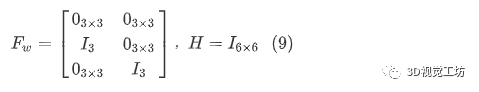
从这里开始,我们将状态变量,,表示为,以简化表示。现在我们定义测量更新方程。首先计算状态误差δ-这是我们估计的状态变量与传入的测量状态变量之间的差异:
然后我们通过更新计算校正状态变量,更新的表示为:
注意,在实践中,这可能是位置分量的简单线性加法和旋转分量的四元数乘法。然后我们更新滤波器协方差:
注意,为了数值稳定性,可以改用Joseph形式。然后我们处理ESKF重置,这进一步更新:
其中是一个DEFINED为以下形式的雅可比矩阵:
其中是状态误差的角分量。
使用单图像基于PnP姿态估计作为测量,我们遵循标准方法,校正,,,,其中状态变量的后验估计是通过添加先验估计和对残差(即先验估计与当前测量之间的差异)的增益加权来获得的。在我们的实验结果中,此设置称为基线EKF。
C. 动态车辆约束姿态滤波
现在我们考虑运动模型,即AV的运动将被限制在一个恒定的速度和方向上。每当检测到约束时(如后续章节所述),对于给定的测量姿态,我们可以期望随后的测量姿态位于当前测量姿态的位置加上距离向量()。因此,我们可以根据实际测量与预期测量之间的距离调整对下一个测量的信任程度。这是通过根据实际测量与预期测量之间的轴位移(仅限平移分量)应用径向基函数(RBF)核来动态调整测量噪声方差实现的。我们也可以估计很可能接近; 然而,如果EKF发生漂移,这可能导致未来测量被不充分信任的情况。也可能会漂移,但漂移幅度会更小,因为速度是位置的导数。
在实践中,我们观察到单个姿态测量的偏差对滤波姿态估计是有害的。为了缓解这一问题,我们决定使用径向基函数(RBF)核来惩罚预期姿势测量值和实际姿势测量值之间的巨大偏差。我们还观察到,使用非线性RBF核比使用欧氏距离度量提供了更精确的定位。
现在我们通过将RBF核应用于实际测量与预测测量之间的轴位移(仅转换分量),定义我们的动态测量方差:
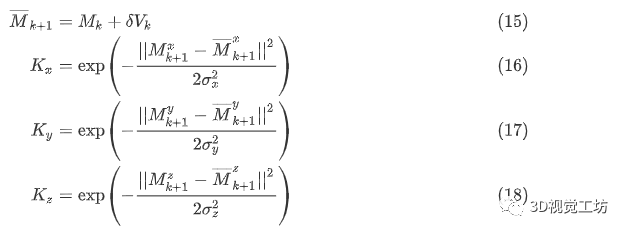
其中是SfM坐标框架的三个平移轴。,,表示内核的带宽。如果自动驾驶车辆不受约束,我们仍然可以期望运动是可预测的,因为自动驾驶车辆的速度和航向不会立即改变。当约束检测为真时,我们通过因子减小 和(始终受路面约束)来减小RBF误差,这反过来增加动态测量方差,定义如下:
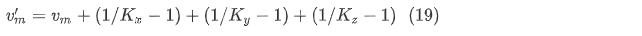
当自动驾驶车辆受到约束时,更小的值导致RBF的带宽更小,这又导致预期测量中的偏差导致的值更小。的值更小然后导致更大,这意味着滤波器将通过新的测量进行调整的幅度更小。直观地,当约束检测处于活动状态时,滤波器只会考虑与自动驾驶车辆当前运动模式一致的新测量。
D. 车辆检测
我们的约束算法首先需要在每幅图像中以像素级掩码的形式检测车辆。我们使用高密度语义分割网络PanopticDeeplab-v3来获得车辆标签像素。为了将感知噪声(导致假阳性检测)的影响与所提方法的定位性能相分离,我们将语义分割输出与物体检测器网络YOLO-P相结合,以模拟AV的高精度车辆检测系统。利用YOLO-P,我们提取图像中所有被分类为车辆的物体的边界框。然后,我们将Panoptic-Deeplab的分割结果(轿车、卡车和公共汽车类别)与YOLO-P为每辆检测到的车辆提取的边界框区域进行掩码相乘。这样得到的每像素分割结果只考虑车辆本身,而不考虑背景像素。我们还检查了每个像素车辆掩码的大小,并删除了像素面积小于0.04%的掩码--这是为了删除非常小的检测结果,因为这些检测结果的大小不足以准确计算约束检测。
E. 约束检测
在这最后一小节中,我们描述了一种根据对环境中动态车辆的检测和分析来计算自动驾驶车辆是否处于受限状态的方法。我们的目标是识别场景中任何动态车辆在两帧连续图像之间是否静止,因为在图像平面中看似静止的动态车辆与自动驾驶车辆之间的相对位置大致保持不变。此外,我们可以合理地假设在这段时间内车辆的速度和航向也保持恒定。这使我们能够设计一个条件算法,检测动态车辆在图像平面中的位置是否固定,并根据检测结果调整非完全受限运动模型;如果没有检测到受限,姿态滤波器保持原样运行。尽管这个受限定义非常简单,但其优势在于几乎不需要采用其他方法中的复杂检测和目标姿态估计与跟踪机制:我们能够在真实世界的自动驾驶相关实验中评估其可行性。
V. 结论
在本文中,我们介绍了一种新颖、轻量级的方法,将从动态车辆检测中获得的有限姿态约束信息纳入定位系统。通过检测和跟踪动态车辆,我们可以利用动态车辆相对于自主车辆的相对位置,为PnP-RANSAC的姿态估计添加帧到帧的运动约束。我们的研究表明,与现有的PnP+IMU融合方法相比,添加这些约束后的定位性能几乎在所有相关指标上都得到了改善,特别是在操作关键的最坏情况下的定位性能方面。
该领域的进一步工作潜力巨大,主要是围绕使用动态车辆作为定位辅助工具这一概念。未来的工作将研究是否可以将这些约束条件纳入因子图SLAM算法(如GTSAM ),从而实现对测量和约束条件的最大后验估计。未来的工作还包括为我们的系统添加视觉里程测量,以应对无法获得IMU数据的情况。最后,我们希望将这项工作扩展到极端视觉外观条件(夜间/雨天)、突然的速度变化以及机器人、无人机和自主系统围绕移动物体(从服务机器人到无人机)运行的动态领域。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。