ISSCC 2023:14篇清华、北大入选论文详解
近日,国际固态电路大会(ISSCC 2023)在美国旧金山举行。ISSCC (International Solid-State Circuits Conference) 国际固态电路会议始于 1953 年,是全球学术界和工业界公认的集成电路设计领域最高级别会议,被认为是「集成电路设计领域的奥林匹克大会」。
本文引用地址:2023 年 ISSCC 共录用同行评审论文 198 篇,来自中国大学的前沿研究论文的数量不容小觑,其中 49 篇来自中国的论文中,其中 13 篇来自清华大学,6 篇来自北京大学。
清华大学
清华大学集成电路学院作为第一署名单位在 ISSCC 2023 发表了 8 篇学术论文,所涉及研究内容包括存内计算视觉芯片、量子计算芯片、多模态 Transform 芯片、异步类脑芯片、可重构存内张量计算芯片、超宽带收发机、分频器、振荡器等。
存内计算视觉芯片 CV-CIM
代价匹配算法需要精确计算图像间的相似度,已经被广泛应用于自动驾驶,机器人,AR/VR 等领域,但由于其频繁的数据访存,导致其难以应用于低功耗场景中。集成电路学院魏少军、尹首一教授团队提出了采用存算一体范式的 CV-CIM,将计算单元与 SRAM 存储单元完成合并,减少数据搬移。利用异或逻辑的自反性,结合律等,可重构为乘法,加法,减法,比较等多种基本算子。进一步经过数模混合存算单元的配合,实现包括 L0/L1/L2 在内的多种距离计算算法;并利用图像相似度,动态扩充计算数据稀疏度,扩展计算噪声容限,提升计算精度;通过增加行方向细粒度地址控制,列方向读写并行模式,大幅提升存算系统的利用率。考虑到模拟单元受 PVT 影响,增加 Canary BIST 单元保证计算系统鲁棒性。CV-CIM 作为国际首款针对图像匹配的存算一体芯片,在 28nm 工艺上成功实现流片,峰值能效为 1158TOPs/W,面积为 0.387mm^2。
该工作以「CV-CIM: A 28nm XOR-derived Similarity-aware Computation-In-Memory For Cost Volume Construction」为题发表在 ISSCC2023。集成电路学院博士研究生岳志恒为论文第一作者,尹首一教授为通讯作者。
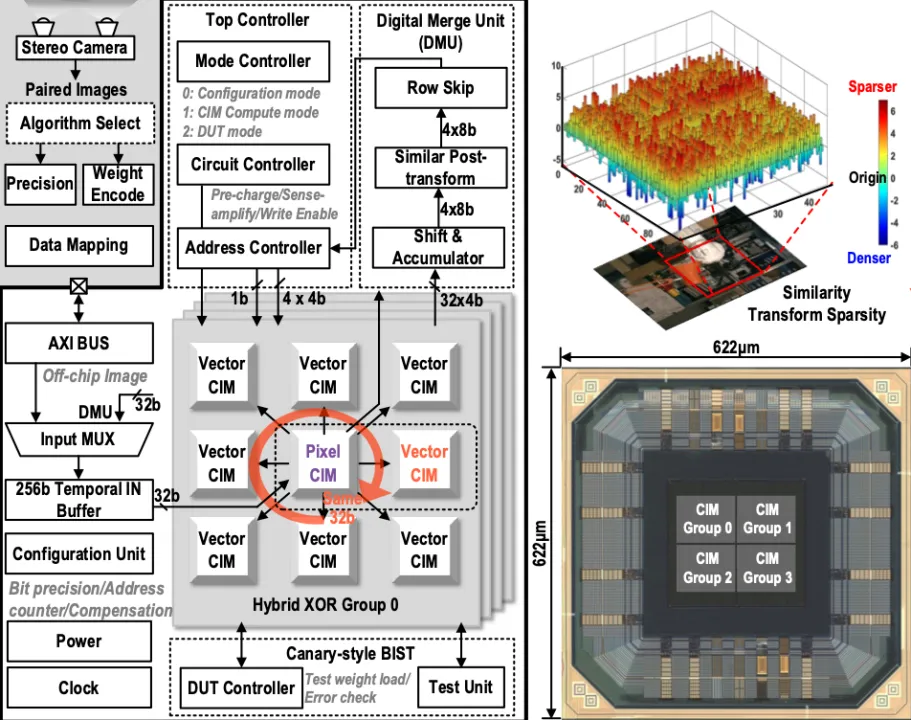
CV-CIM 架构设计优化实验及芯片照片
超导量子计算控制芯片
量子计算系统还有很遥远的距离。超低温 CMOS 芯片技术是解决这一瓶颈的有效途径之一。集成电路学院王志华、池保勇团队在前期大量 CMOS 元器件超低温特性建模研究的基础上,设计出目前具有最低功耗水平和最小芯片面积的双通道量子比特控制芯片。该芯片基于极化调制技术,在 3.5K 超低温环境下可以产生超导量子比特控制所需的 XY 通道任意包络脉冲信号和 Z 通道偏置信号,同时集成了片上本振、时钟、存储等电路,在国际上首次把单个量子比特控制能耗降低至 13.7mW。较 IBM、PSTECH 等最新研究,能耗水平降低 40% 以上。测试表明,该芯片可以在超低温环境下对超导量子比特实现有效控制。
该工作以「A Polar-Modulation Based Cryogenic Qubit State Controller in 28nm Bulk CMOS」为题发表在 ISSCC2023。该芯片是国内首个公开报道的集成化量子比特控制芯片,具有集成度高、功耗低、面积小等显著特点,对于推进量子计算系统自主可控的集成化、小型化有关键支撑作用。论文第一作者为集成电路学院毕业生郭衍束博士,姜汉钧副教授、李铁夫副研究员为该项研究工作的主要负责人。
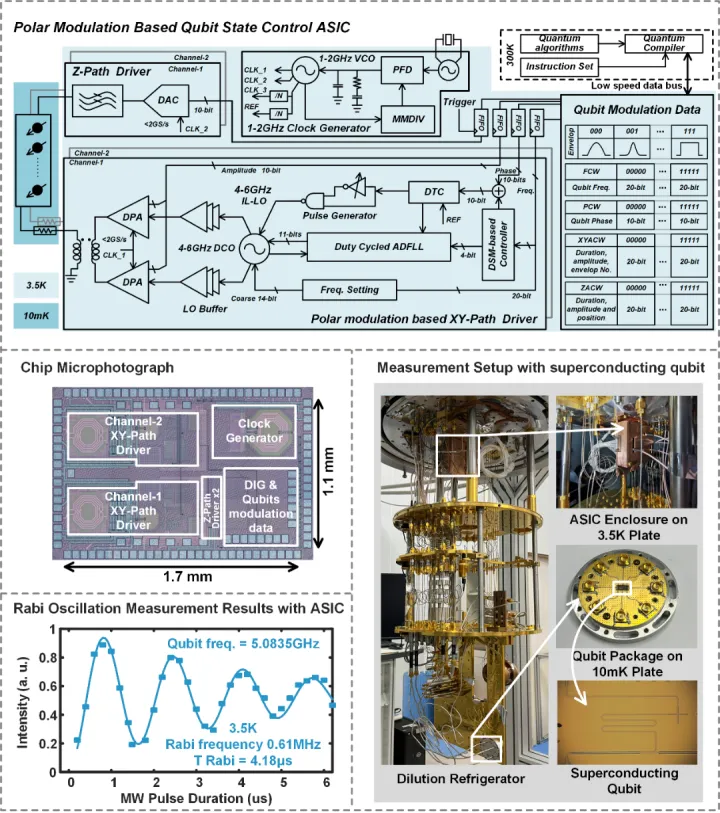
低温 CMOS 量子比特控制芯片结构及测试
多模态 Transform 芯片
多模态 Transformer 是当下最流行的处理多种模态信号(视觉、文字、语音等)的 AI 模型之一,已广泛应用于视频问答、多语言图像检索等任务中。这类模型巨大的计算量、频繁的数据访问、独特的跨模态注意力机制对 AI 芯片设计造成诸多挑战。集成电路学院魏少军、尹首一教授团队提出国际首款基于可重构数字存算一体架构的多模态 Transformer AI 芯片 MulTCIM。研究团队充分利用跨模态注意力机制中的计算冗余性,设计出综合利用 attention-token-bit 三个层次混合稀疏性的存算一体架构:1)使用注意力局部性调度器优化 attention 稀疏,提高存算单元利用率;2)采用模态自适应存算一体网络优化 token 稀疏,减少跨模态切换时的等待时间;3)利用位宽均衡存算一体单元优化 bit 稀疏,降低存算一体单元的计算延迟。MulTCIM 芯片使用 TSMC 28nm 工艺成功流片,在典型多模态 Transformer 模型 ViLBERT 上仅产生 2.24μJ/Token 的能耗,相比于 ISSCC2022 上发表的 Transformer 芯片可获得 5.91 倍的能效提升。
该工作以「MulTCIM: A 28nm 2.24μJ/Token Attention-Token-Bit Hybrid Sparse Digital CIM-based Accelerator for Multimodal Transformers」为题发表在 ISSCC2023。集成电路学院毕业生涂锋斌博士为论文第一作者,尹首一教授为论文通讯作者。
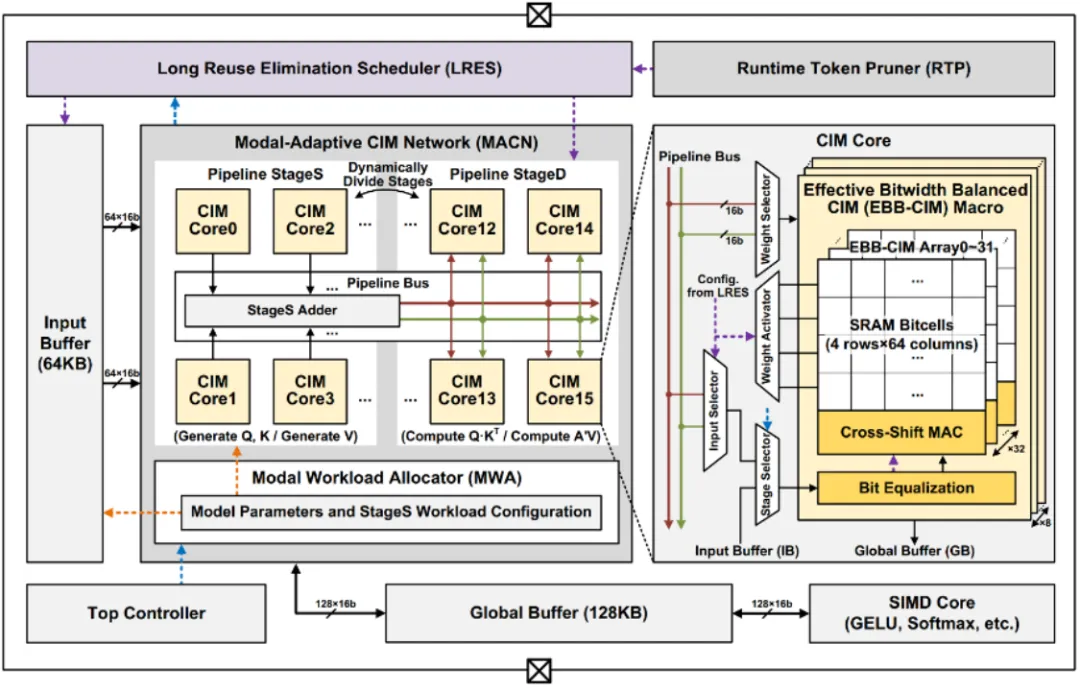
面向多模态 Transformer 模型的 MulTCIM 芯片架构图
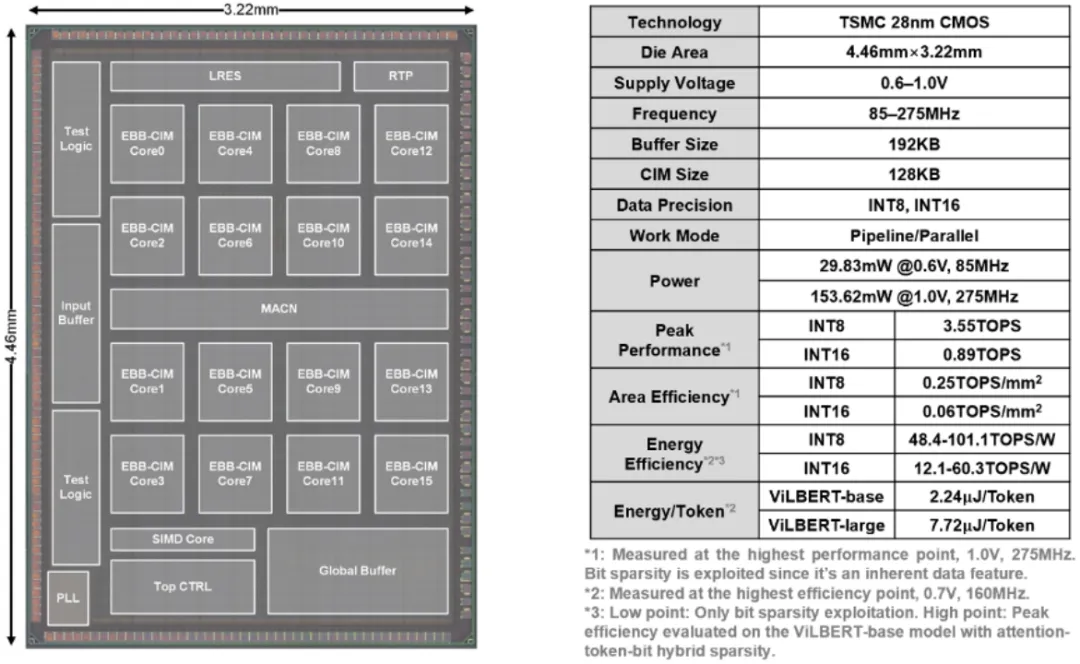
MulTCIM 芯片及硬件指标
片上学习异步类脑芯片
异步电路是设计大规模类脑芯片的重要技术,但由于缺乏成熟 EDA 工具的支持,异步电路设计存在较大挑战。集成电路学院王志华、池保勇团队研发出国内首款具备片上学习能力的异步类脑芯片 ANP-I,ANP-I 芯片采用全异步电路技术,设计了能实现手势识别、关键词检测、图像分类等多类型任务的片上学习类脑芯片。该芯片实现了三层全连接网络,片上集成了 522 个神经元,517K 个突触,每个突触的权重精度为 8/10-bit。ANP-I 芯片具有极低功耗的片上学习能力,针对不同的任务,芯片从随机权重开始进行训练,在保证 92% 以上准确率的前提下,每个样本的学习能耗低于 100nJ。该性能使得边缘端智能芯片同时具备识别和学习能力成为可能,可应用于万物智联的边缘端多模态信息的智能处理。传统应用于边缘计算的智能芯片,由于片上学习的能耗代价过高,往往只支持识别过程。ANP-I 芯片低能耗的片上学习能力可以很好的解决该问题,使得具有片上学习能力的边缘端智能芯片得到广泛的运用。例如在基于肌电臂环的手势识别展示中,通过片上学习,ANP-I 芯片能学习到不同使用者特有的肌电信号特征,并且消除肌电臂环电极偏移带来的影响,极大程度提高基于肌电臂环的手势识别准确率以及实用程度。
以上工作以「ANP-I: A 28nm 1.5pJ/SOP Asynchronous Spiking Neural Network Processor Enabling Sub-0.1μJ/Sample On-Chip Learning for Edge-AI Applications」为题发表在 ISSCC2023。集成电路学院博士研究生张吉霖为论文第一作者,陈虹研究员为通讯作者。
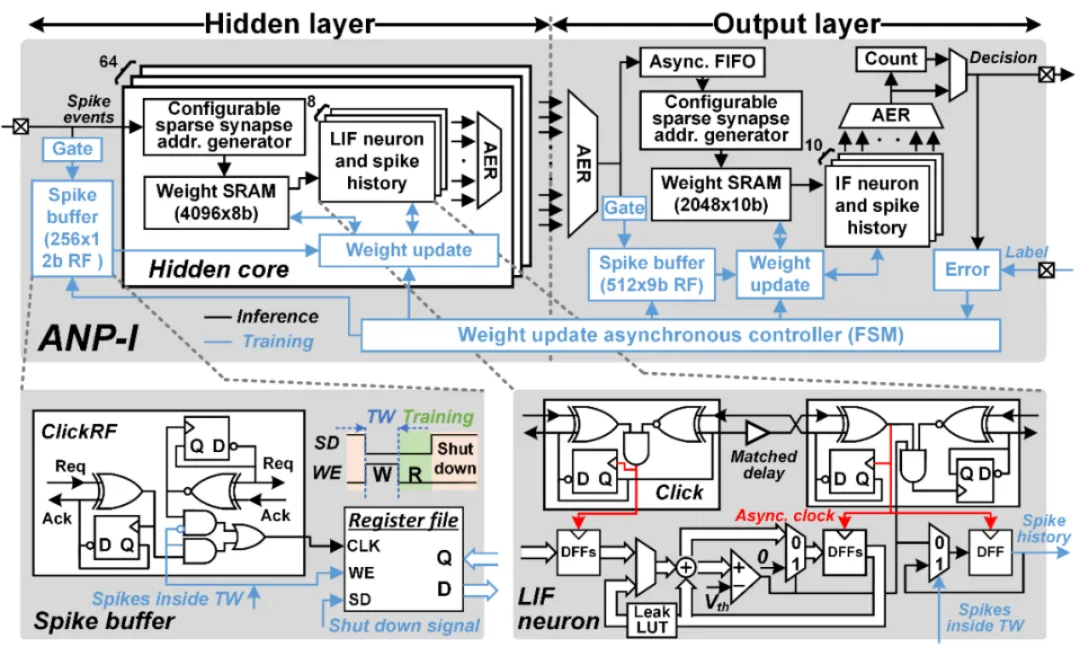
片上学习异步类脑芯片硬件架构
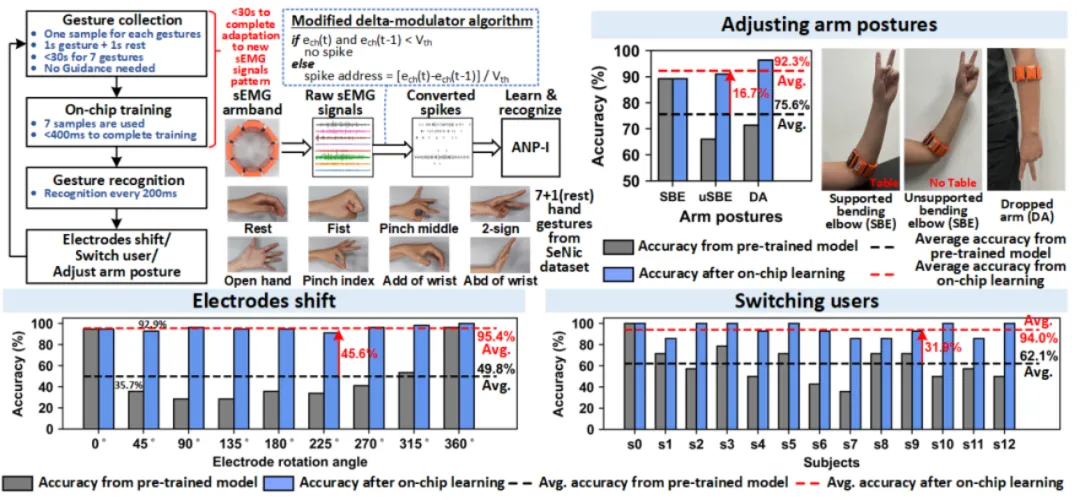
片上学习异步类脑芯片在基于肌电臂环的手势识别上的应用
可重构存内张量计算芯片 TensorCIM
Beyond-NN 计算是面向通用智能场景的新型计算类型。不同于传统的处理图像、语音等规则数据结构的神经网络,Beyond-NN 计算需要处理真实世界中的非规则数据结构,例如社交网络、知识图谱、推荐系统等。针对 Beyond-NN 在算力、访存、功能三方面的技术挑战,集成电路学院魏少军、尹首一教授团队提出国际首款基于可重构数字存算一体架构的多芯粒张量处理器 TensorCIM:1)TensorCIM 采用多芯粒系统对算力和存储容量进行扩展,在降低制造成本的同时,为不同规模的 Beyond-NN 场景提供可扩展的系统解决方案。2)TensorCIM 通过数字存算一体架构大幅减少数据搬运,并支持高精度的浮点计算以保证准确度。3)TensorCIM 将可重构技术与数字存算一体相结合,实现稀疏张量聚集和稀疏神经网络计算两种模式的动态切换,保持极高的计算资源利用率。TensorCIM 芯片使用 TSMC 28nm 工艺成功流片,在图神经网络、推荐系统等典型 Beyond-NN 应用上验证,取得 3.7nJ/Gather 的稀疏张量聚集效率和 8.3TFLOPS/W 的稀疏 FP32 张量代数能效,相比同期浮点存算一体 AI 芯片能效提升 5.6 倍。
该工作以「TensorCIM: A 28nm 3.7nJ/Gather and 8.3TFLOPS/W FP32 Digital-CIM Tensor Processor for MCM-CIM-Based Beyond-NN Acceleration」为题发表在 ISSCC2023。集成电路学院毕业生涂锋斌博士为论文第一作者,尹首一教授为论文通讯作者。
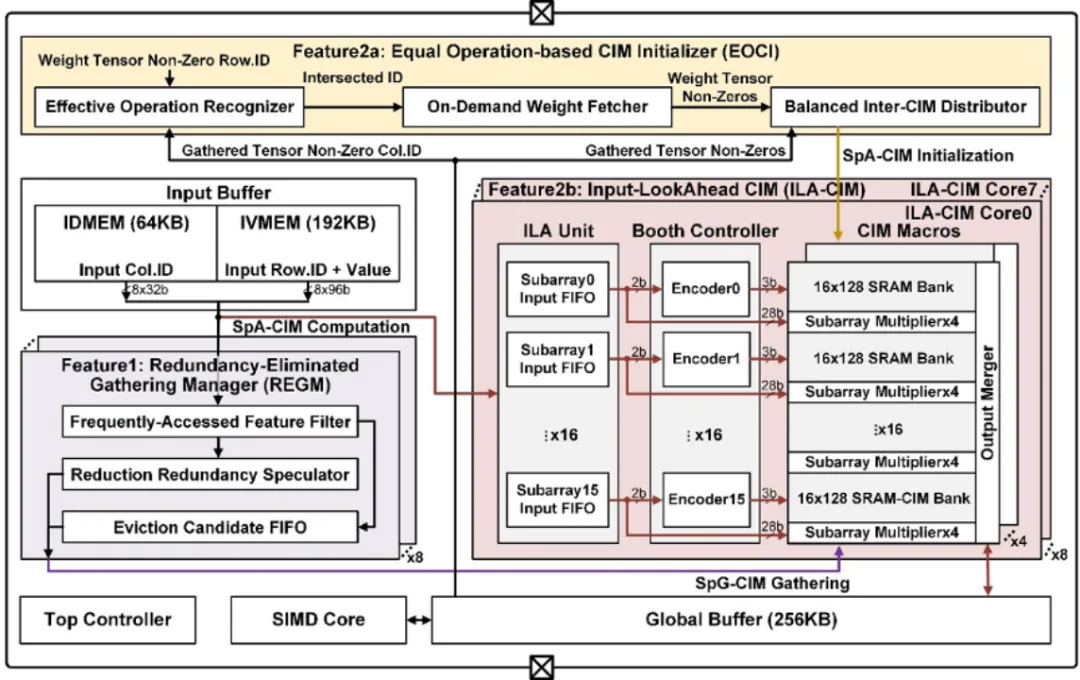
面向 Beyond-NN 计算的 TensorCIM 芯片(单芯粒)架构图
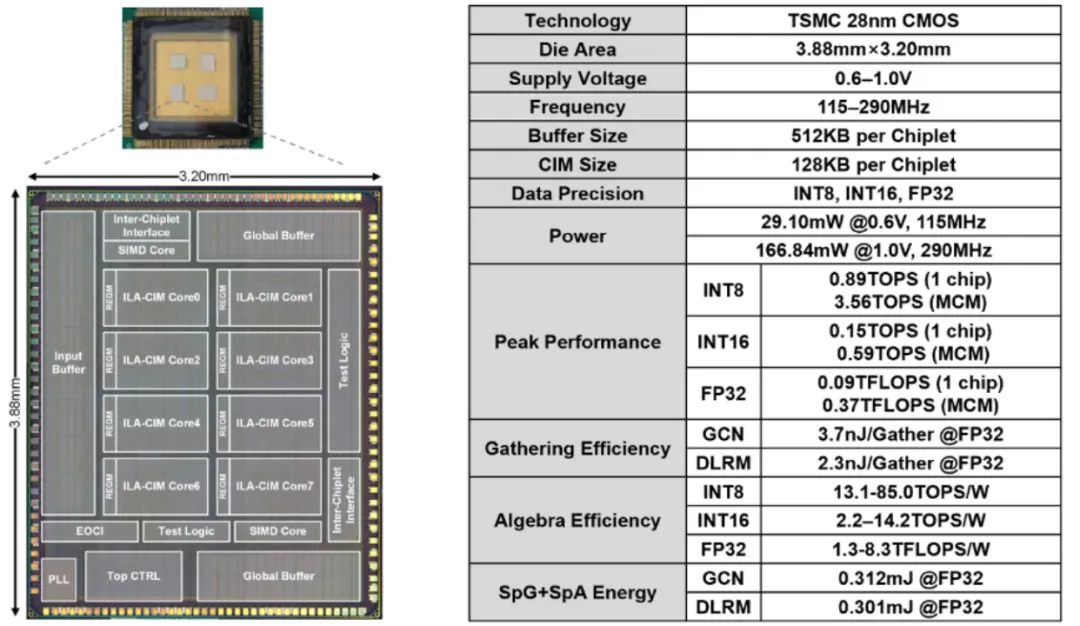
TensorCIM 芯片及硬件指标
脉冲超宽带收发机芯片
脉冲超宽带 (IR-UWB) 技术通过发送极窄脉冲序列实现低功耗信息传输和厘米级测距精度,逐渐成为短距通信的主流技术之一。但是,传统的脉冲超宽带收发机存在两大技术挑战:首先,极窄的脉冲宽度使得收发机在基带同步时面临困难。其次,脉冲超宽带接收机在系统功耗和解调性能之间存在着折中关系。针对以上问题,研究团队提出了一种全新的脉冲超宽带收发机架构,该收发机采用了两项关键技术。其一是双脉冲开关键控 (Twin-OOK) 的调制方法,该调制方法不仅有效解决了收发机基带同步的问题,而且通过跳频技术提高了发射信号的频谱利用效率。其二是正交不确定中频的接收机构架,该构架显著提升了脉冲超宽带接收机的抗窄带干扰性能和测距精度。采用 65nm CMOS 工艺实现的脉冲超宽带收发机具有-71dBm 的灵敏度、0.96 厘米的测距精度,同时能够容忍最大-22.4dBm 来自 6GHz 频率的窄带干扰信号。
该工作以「A Quadrature Uncertain-IF IR-UWB Transceiver with Twin-OOK Modulation"为题发表在 ISSCC2023。集成电路学院博士研究生汪博闻为论文第一作者,李宇根教授为通讯作者。
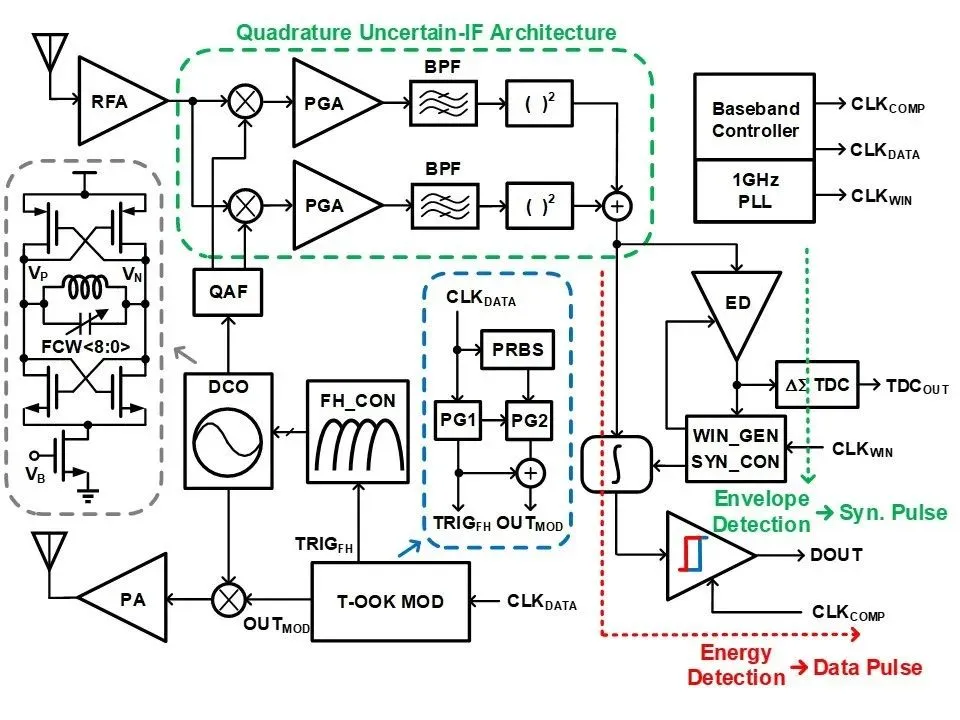
基于 Twin-OOK 调制的正交不确定中频 IR-UWB 收发机架构
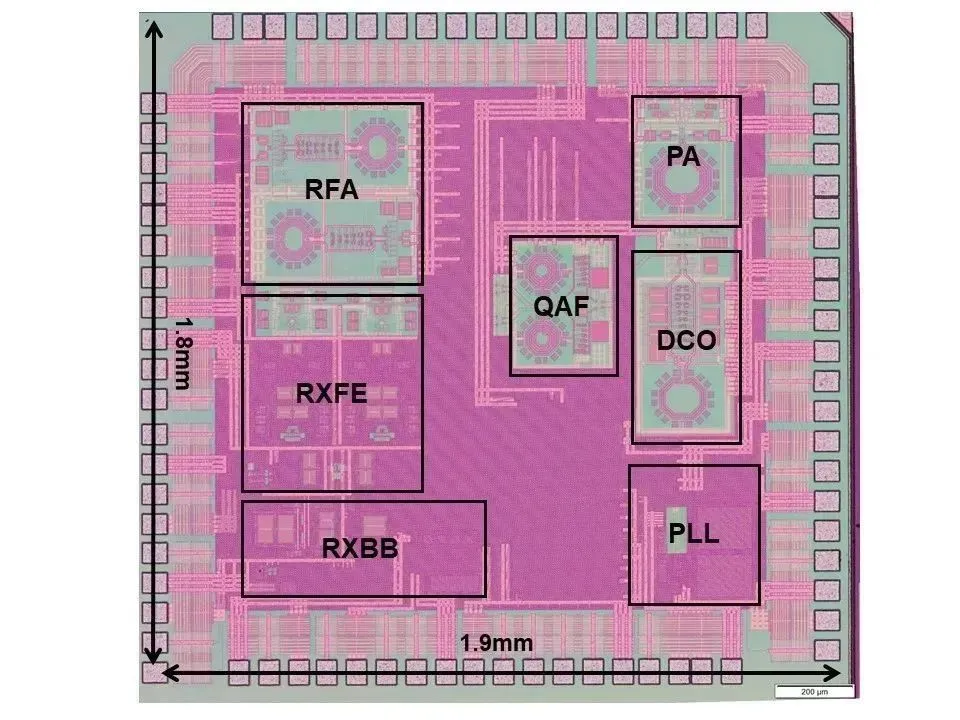
IR-UWB 收发机芯片显微照片
超低杂散真分数输出分频芯片
现代片上系统(SoC)集成了几个独立的片上时钟发生器,以满足不同模块的差异化设计需求,如微处理器、存储器、I/O 接口和电源管理等。传统方案通常在 SoC 中使用多个锁相环(PLL)来提供各种频率输出,然而,这种方法导致相当大的硅面积、功率、成本和整体系统复杂性。真分数输出分频器(FOD)由多模分频器(MMD)、数字时间转换器(DTC)和数字控制器组成,已被证明是产生多个独立时钟的有效方法。然而,DTC 特性对 PVT 敏感,任何增益失配/积分非线性(INL)都会产生较大的杂散,从而降低频谱纯度和时钟抖动。在 PLL 中广泛应用的传统 DTC 增益校准算法需要反馈路径来反映 DTC 增益失配,这禁止其在具有开环结构的 FOD 中使用。集成电路学院王志华、池保勇团队提出了一种具有辅助 PLL(aux-PLL)的 FOD,具备后台 0/1/2 阶 DTC INL 非线形校准能力。辅助 PLL 用作频域滤波器,自然跟踪输入时钟的载波频率。因此,不需要先验知识和前景校准。由于所提出的基于辅助 PLL 的 0/1/2 阶 DTC INL 校准算法,所提出的真分数输出分频器 FOD 实现了低于-80dBc 的最坏情况杂散性能。
该工作以「A 10-to-300MHz Fractional Output Divider with -80dBc Worst-Case Fractional Spurs Using Auxiliary PLL-Based Background 0/1st/2nd-Order DTC INL Calibration」为题发表在 ISSCC2023。集成电路学院博士研究生杨宇蒙为论文第一作者,邓伟副教授为通讯作者。
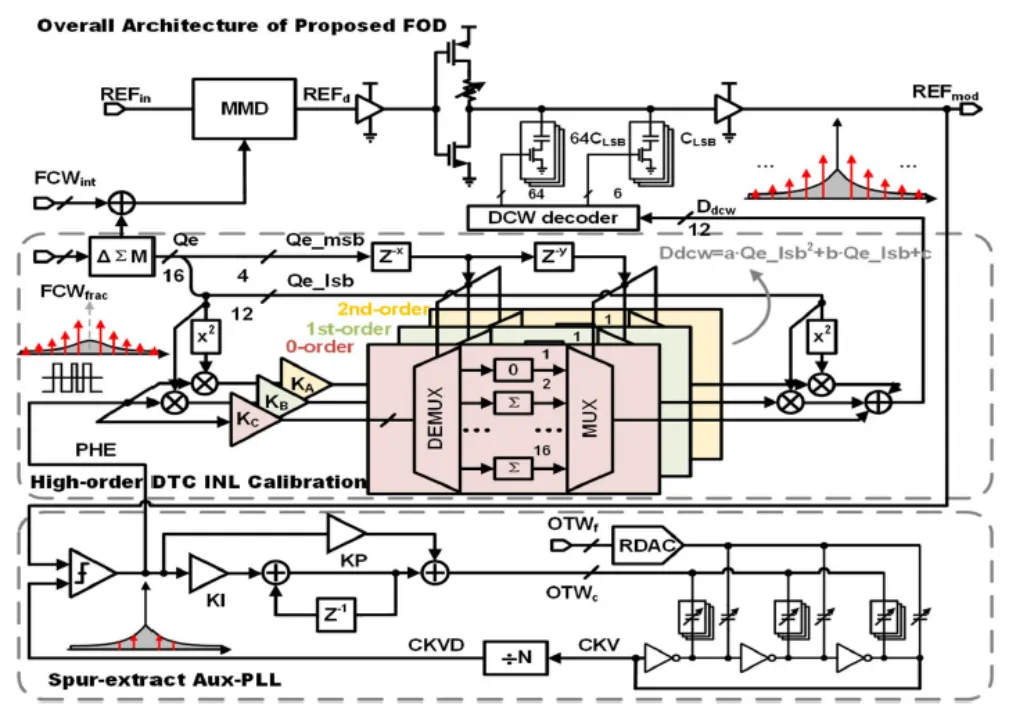
具备后台自适应补偿的超低杂散真分数输出分频芯片的总体架构
双核增强 F 类振荡器芯片
当前的 5G 和未来的 6G 高速移动互联网时代对移动和便携式设备中的本地振荡器(LO)的功耗、硅面积和相位噪声规范提出了更严格的要求,特别是在电池供电的移动电话、笔记本电脑和用于移动基站的无人机(UAV)中。在过去的几十年中,大量研究聚焦于提高 RF 和毫米波振荡器的功率效率,同时保持所需的相位噪声特性。集成电路学院王志华、池保勇团队提出了一种具有共模噪声自消除和隔离技术的 11.5-14.3GHz 双核 Class-F VCO。在不占用额外面积的情况下,VDD 和 GND 的注入噪声同时被固有地消除,并且从漏极到栅极的噪声路径被隔离。测量结果表明,所提出的共模噪声自消除和隔离 VCO 在与 11.8GHz 载波偏移 1MHz 时达到-119.2dBc/Hz 相位噪声,换算为 192.8dBc/Hz 的 FoM,该性能在已报道的工作频率范围相近的 VCO 研究中极具竞争力。
该工作以「A 11.5-to-14.3GHz 192.8dBc/Hz FoM at 1MHz offset Dual-core Enhanced Class-F VCO with Common-Mode-Noise Self-Cancellation and Isolation Technique」为题发表在 ISSCC2023。集成电路学院博士研究生吴奇修为论文第一作者,邓伟副教授为通讯作者。
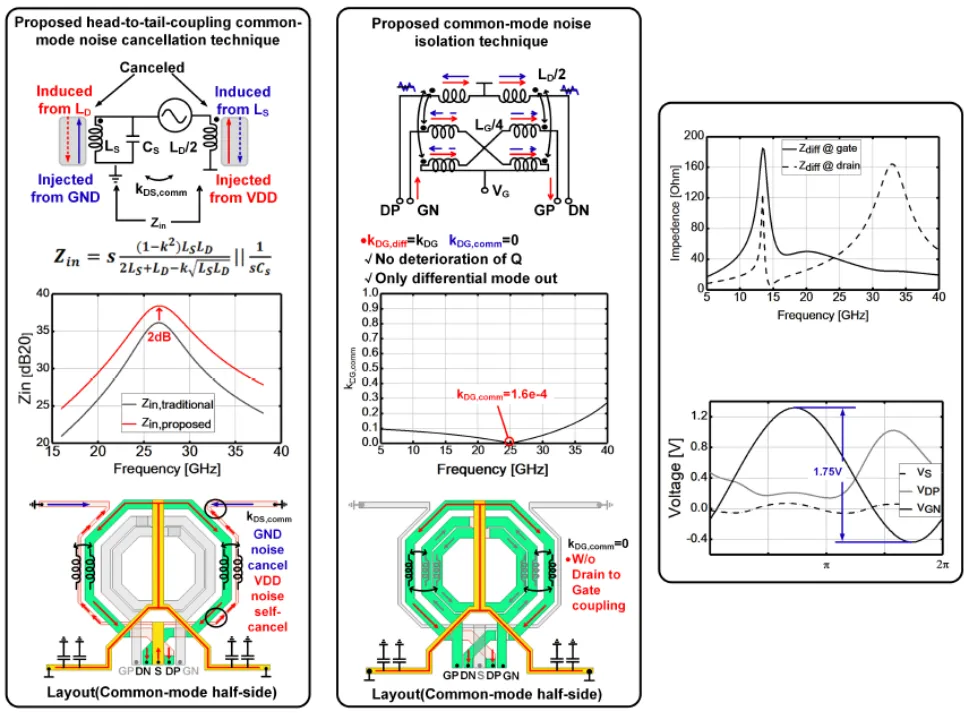
振荡器芯片共模噪声消除和隔离方案
北京大学
在本届 ISSCC 上,北京大学集成电路学院/集成电路高精尖创新中心共有 6 篇论文入选,研究成果覆盖「存算一体 AI 芯片、模拟与数字混合芯片、时钟芯片、高速互连芯片」等领域,涉及大会全部 12 大领域中的 4 个领域,论文数在国际高校里排名第 5,在国际高校和企业里排名第 9。
存算一体 AI 芯片
面向边缘 AI 场景,针对传统存内计算芯片冗余数据处理产生功耗浪费的问题,课题组提出了基于差值求和计算方式的模拟存内计算拓扑,利用边缘 AI 场景中输入特征值逐渐且偶然变化的特点,自适应的消除冗余数据处理产生的功耗,显著提升了神经网络计算能效。该创新通过处理输入变化量而非输入绝对值的方式,最大限度消除了不变数据处理所浪费的功耗,提升了计算效率。
北京大学黄如院士-叶乐教授团队,提出了差值输入技术和差值矩阵乘法技术,通过将输入特征值由绝对量变为变化量的方式,降低了存内计算阵列计算功耗,并实现自适应的输出分布集中;此外,还提出了低位优先模数转换器,通过减少较小数据模数转化次数的方式,在不损失计算精度的情况下,显著降低了模拟存内计算中的模数转换功耗。
基于上述创新技术,研制了差值求和模拟存内计算芯片,在 8-bit 输入/8-bit 权重/全精度输出的情况下,实现了 21.38 TOPS/W 的峰值能效,1.44 TOPS/mm2 的峰值单位面积算力;在综合评估指标(=能量效率×面积效率)下,达到了 26.72 TOPS/W×TOPS/mm2,是世界最好的存内计算芯片的 1.25 倍。该创新具有高能效、高算力、高通用性三大特性,可应用于边缘端 AI 计算场景,如:图像识别、语音识别、安防监控等。该创新有望与图像传感器相结合,实现针对边缘端 AI 的感存算一体高效智能处理。
该工作以《面向边缘 AI 处理的基于差值求和方式的 21.38 TOPS/W 的 SRAM 存内计算芯片》(A 22nm Delta-Sigma Computing-In-Memory (ΔΣCIM) SRAM Macro with Near-Zero-Mean Outputs and LSB-First ADCs Achieving 21.38 TOPS/W for 8b-MAC Edge AI Processing)为题,发表于今年 ISSCC,文章第一作者北京大学集成电路学院博士生陈沛毓进行宣讲,北京大学集成电路学院博士生武蒙为共同一作,文章的通讯作者是马宇飞研究员和叶乐教授。
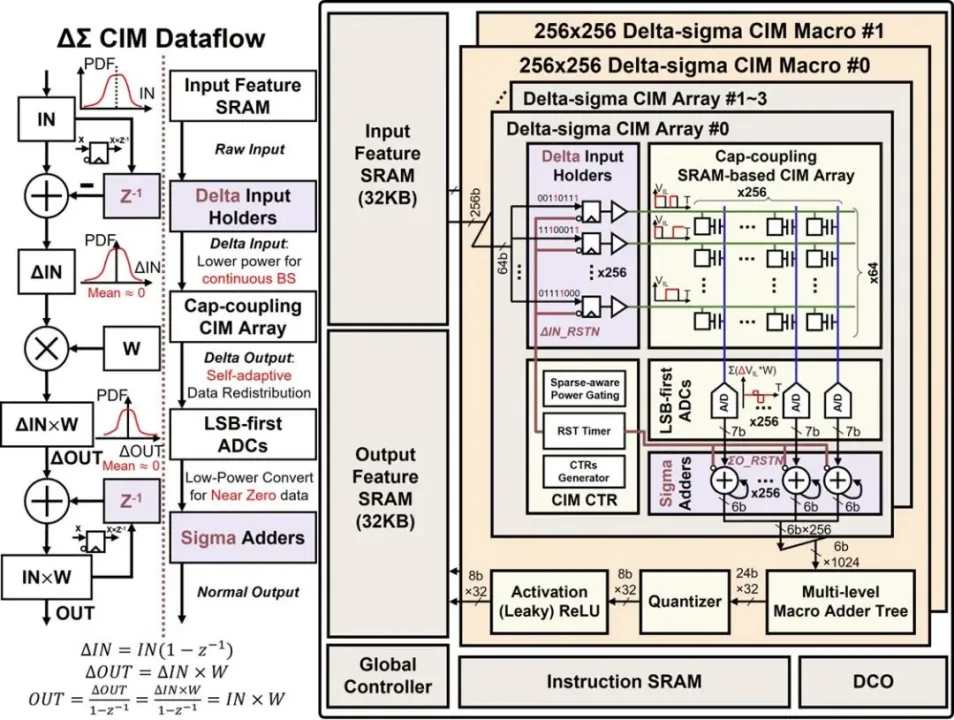
(a) 差值求和存内计算芯片数据流与架构图

(b)存内计算芯片显微照片
高能效电容型感知芯片
该工作面向物联网传感器应用,针对不断上升的高速高精度电容数字转换器需求,实现了一款高性能电容传感器,解决了传统高精度电容传感器的架构不利于高速转换的问题,突破了传统电容采样过程中采样热噪声造成的性能瓶颈。
针对以上问题,北京大学黄如院士-叶乐教授团队,从架构和电路两个层面提出解决方案。架构层面,本工作创新性地将流水线型逐次逼近型寄存器转换架构引入电容传感器领域,突破传统架构面临的转换精度、能效和转换速度之间的折衷关系。电路层面,该工作首次提出了可应用于电容传感中的 kT/C 采样噪声消除技术,解决了小电容传感中的精度上限问题,突破了采样热噪声的精度瓶颈。此外,还首次提出了基于不完全建立的相关电平抬升技术,缩短了传统增益提升技术的粗放大阶段,减少了额外功耗,并将等效开环增益大幅提升,提供了极高的增益稳定性,提高了级间放大器的能量效率和精度。在提高转换速率的同时,实现了高精度(1fFrms 噪声水平)电容传感器的能量效率世界纪录,相较现有工作将能效提升了一倍。
基于上述架构和电路层面的创新,课题组研制了一款基于 22nm CMOS 工艺的紧凑型高能效电容传感器芯片,该电路在 22nm 工艺下实现了对 0-5.16pF 电容值测量,精度达到了 37.12aF,在所有高精度(1fFrms 噪声水平)电容传感器中具有最高的能效(7.9fJ/conv.-step),且达到了 71.3dB 的信噪比,相较前人的工作将能效提升了一倍。该电路具有高能效、高精度、小面积、高转换速度等特点,可广泛应用于面向电容传感的各类物联网传感器和前端应用中,并且为电容传感芯片的小型化提供了全新的解决方案。
该工作以《基于采样热噪声消除和非完全建立相关电平抬升技术的 7.9fJ/Conversion-Step,37.12aFrms 噪声的流水线逐次逼近型寄存器架构电容-数字转换器芯片》(A 7.9 fJ/Conversion-Step and 37.12 aFrms Pipelined-SAR Capacitance-to-Digital Converter with kT/C noise cancellation and Incomplete-Settling based Correlated Level Shifting) 为题,发表于今年 ISSCC 的模拟传感器前端领域(Session23 Analog Sensor Interface)分会场,由文章第一作者北京大学集成电路学院博士生高继航进行宣讲,文章的通讯作者是沈林晓研究员和叶乐教授。
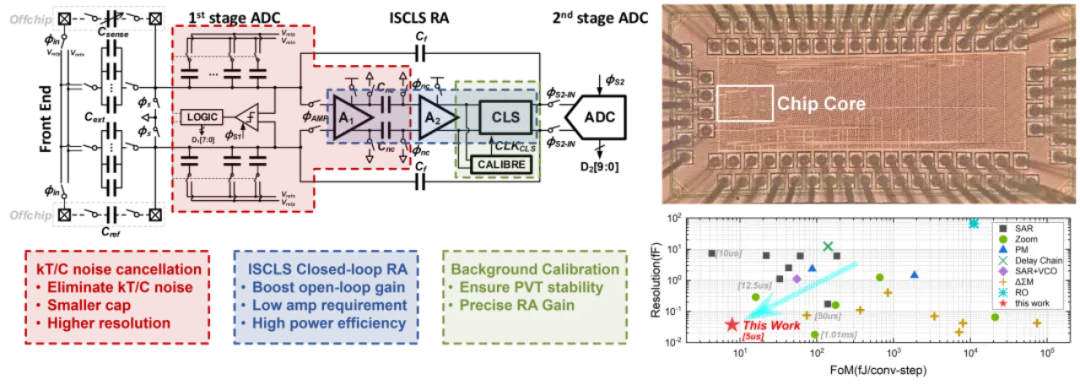
(a) 电容传感器架构图和创新技术 (b) 电容传感器芯片显微照片和性能对比图
极低功耗振荡器芯片
该工作面向智能物联网 AIoT 芯片应用,针对需要周期唤醒的 AIoT 芯片,设计并实现了一款超低功耗晶体振荡器电路,并实现了综合条件下国际领先的低功耗与计时精度。
北京大学黄如院士-叶乐教授团队,提出了基于 Gm-C 的电流注入时间控制电路与振幅检测电路:该技术创新性地利用了 Gm-C 这一基础模拟电路模块,解决了电荷注入式晶体振荡器的电流注入时间与大小控制的挑战,使得基于此技术的 32kHz 实时时钟(RTC)电路能够在实现高精度计时的同时,在应用环境温度范围内仅消耗最多不到 2nW 的功耗;与此同时,由于模拟电路功耗主要取决于其偏置电流,在内置电流源的情况下,该电路较已发表的同类工作相比,实现了功耗对温度最低的敏感性。
基于上述创新理念与技术,课题组研制了一款基于 22nm CMOS 工艺的超低功耗 32kHz 晶体振荡器芯片。该电路在使用 ECS-2X6X 音叉型 32kHz 晶体下,在 25˚C 室温下的平均功耗仅为 0.954nW,取得了已发表过的基于 32kHz 电流注入晶体振荡器中功耗最低的世界纪录。其在 80˚C 下的功耗仅为 1.90nW,为低功耗晶体振荡器中的世界纪录。该晶体振荡器在长时工作下表现出了低至 6ppb 的 Allan 误差(Allan Deviation),取得了单电源晶体振荡器电路的长时稳定性世界纪录。该电路可广泛应用于面向环境应用的 IoT 芯片中,作为其中低功耗高精度实时时钟模块的核心。
该工作以《一款 22nm CMOS 工艺下利用基于 Gm-C 的电流注入控制电路实现的 0.954nW 32kHz 晶体振荡器》(A 0.954nW 32kHz Crystal Oscillator in 22nm CMOS with Gm-C-Based Current Injection Control)为题,发表于今年 ISSCC,文章的第一作者是北京大学集成电路学院博士后张奕涵,文章的通讯作者为叶乐教授。

(a)电流注入型晶振结构与电路图

(b)晶振芯片显微照片
超高速发送机芯片
不断增长的通信需求持续推动有线通信链路向更高的数据速率演进,目前超高速有线收发机的数据速率已达到 100+Gb/s 量级。为了提高频谱利用率,四电平脉冲幅度调制(PAM-4)在超高速链路中被广泛采用。然而 PAM-4 调制方式面临眼宽、眼高减小的挑战。
北京大学盖伟新教授团队从电路设计和均衡机制方面入手,提出了可编程宽度的脉冲发生器,依靠脉冲宽度调节驱动器增益,从而实现最快信号翻转速度,减小信号边沿在码元宽度中占据的比例,改善眼宽;提出了基于码型的预加重均衡机制,通过检测电路对待发送的信号码型实时监测,在特定信号处以注入电流的方式加强信号,消除码间干扰的同时避免输出摆幅衰减。
基于上述创新设计,课题组研制了一款基于 28nm CMOS 工艺的超高速有线发送机芯片,并对芯片进行了性能测试与汇报。该发送机芯片实现了高达 128Gb/s PAM-4 的数据速率,并且取得了 1.4pJ/b 的能量效率。提出的可编程宽度脉冲发生器实现了 13% 的眼宽增长,且没有额外的功耗代价;相比传统前馈均衡,基于码型的预加重均衡机制使得眼图张开面积提高了约 25%。该电路可广泛应用于数据中心、高性能计算等高通信需求的场景,为其提供高速率、高可靠的数据传输。
该工作以《A 128Gb/s PAM-4 Transmitter with Programmable-Width Pulse Generator and Pattern-Dependent Pre-Emphasis in 28nm CMOS》为题,发表于今年 ISSCC,文章的第一作者是北京大学集成电路学院博士生盛凯,文章的通讯作者是盖伟新教授。
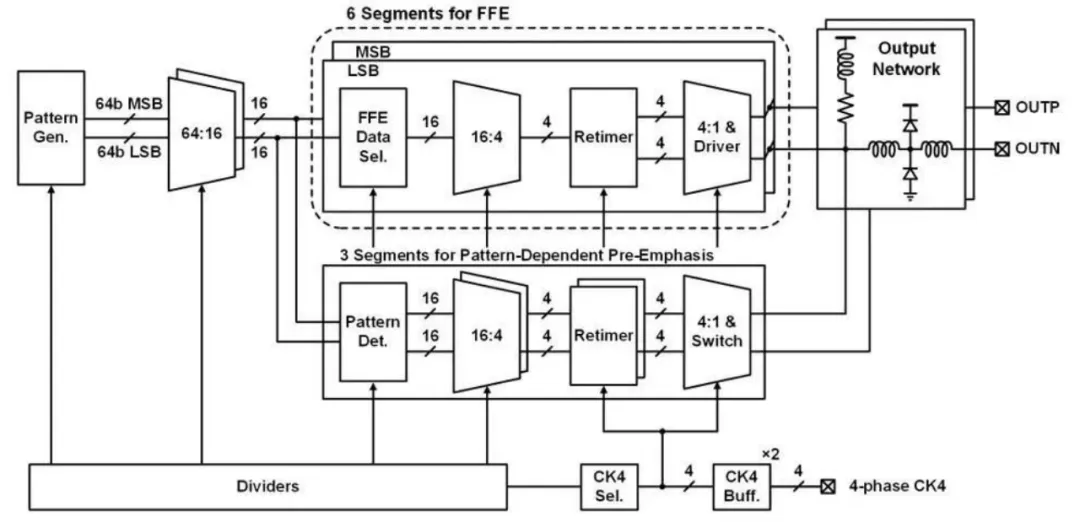
(a)发送机架构图

(b)发送机芯片显微照片
超高速接收机前馈均衡器芯片
该工作面向超高速串行传输应用,针对传统判决反馈均衡器时序难以满足、前馈均衡器采样保持功耗较大的问题,设计并实现了一款超高速接收机前馈均衡器芯片,传输速率、均衡能力与能效比均为同类芯片最优水平。
北京大学盖伟新-何燕冬教授团队提出了基于延迟线与分布式抽头的前馈均衡技术:该技术利用无源延迟线在超高速场景下损耗小的天然优势,解决了对模拟信号延时的功耗与噪声较大的问题,在实现 200Gb/s 超高速率均衡的同时,利用分布式结构降低了抽头负载电容引入的信号反射;此外,通过在抽头放大器中采用源极 RC 退化技术,赋予前馈均衡器灵活的低频均衡能力,避免仅靠增加抽头数量来消除长尾码间干扰,大幅降低了电路功耗。
基于上述创新技术,课题组研制了一款基于延迟线的 200Gb/s 接收机前馈均衡器芯片。该芯片实现了对 200Gb/s 数据的均衡,可提供高达 17.2dB 的均衡能力,且能效比仅 0.43pJ/b,均为接收机连续时间前馈均衡器的最优水平。该均衡器芯片具有高带宽、低功耗、低噪声的优势,可广泛用于数据中心、Chiplet 等串行数据传输应用中,为未来短距 200Gb/s 接收机提供了全新的低功耗解决方案。
该工作以《一款 28nm 工艺下, 基于延迟线技术并支持低频均衡的 0.43pJ/b, 200Gb/s,5 抽头接收机前馈均衡器》(A 0.43pJ/b 200Gb/s 5-Tap Delay-Line-Based Receiver FFE with Low-Frequency Equalization in 28nm CMOS)为题,发表于今年 ISSCC 先进有线互连技术(Session 6: Advanced Wireline Links and Techniques)分会场,文章的第一作者为北京大学集成电路学院博士生叶秉奕,文章的通讯作者为盖伟新教授。
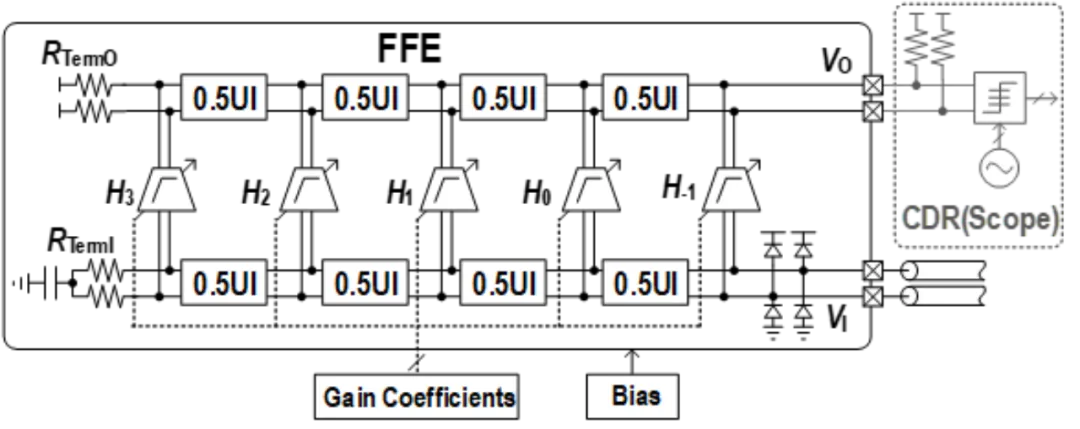
(a) 接收机前馈均衡器架构图

(b)均衡器芯片显微照片
高能效模数转换器芯片
面向语音识别、智慧医疗等多种物联网应用,针对其对中等带宽信号实现高精度、高能效采集的需求,本工作实现了一种在性能上国际领先且易于驱动和系统集成的增量型缩放式模数转换器,相比于其他同类型的缩放式模数转换器设计取得了最高的带宽和最低的驱动需求。
本工作在缩放式模数转换器的架构和电路方面提出了新的设计方法:在架构方面,首次采用噪声整形逐次逼近型量化器进行缩放式模数转换器中的细量化,并提出了一次采样多次量化的量化方法,大幅降低了对采样电路的要求,提升了系统的带宽;在电路方面,提出了一种新型的环路滤波器电路设计方法,该方法仅需要一个动态缓冲器即可实现高阶、高鲁棒性的环路滤波器,显著降低了系统硬件开销和功耗。
基于上述创新技术,课题组研制了一款基于 28nm CMOS 工艺的增量型缩放式模数转换器芯片。该款芯片一次模数转换仅需要 8 次采样,在低频 2.5kHz 和中频 20kHz 的输入信号下分别达到了 92.5dB 和 92.2dB 的信噪失真比,系统功耗为 160μW,在同类的缩放式模数转换器中具有最高的输入带宽(150kHz),且易于驱动,单次转换所需的输入驱动开销最小,整个系统达到了国际领先的模数转换器能效水平(182.2dB FoM)。该电路可广泛应用于多种物联网应用场景,并且为如缩放式模数转换器的多步模数转换器提供了新的实现和量化方法。
该工作以《A 150kHz-BW 15-ENOB Incremental Zoom ADC with Skipped Sampling and Single Buffer Embedded Noise-Shaping SAR Quantizer》为题,发表于今年 ISSCC,文章的第一作者是北京大学集成电路学院博士生王宗楠,文章的通讯作者是唐希源研究员。
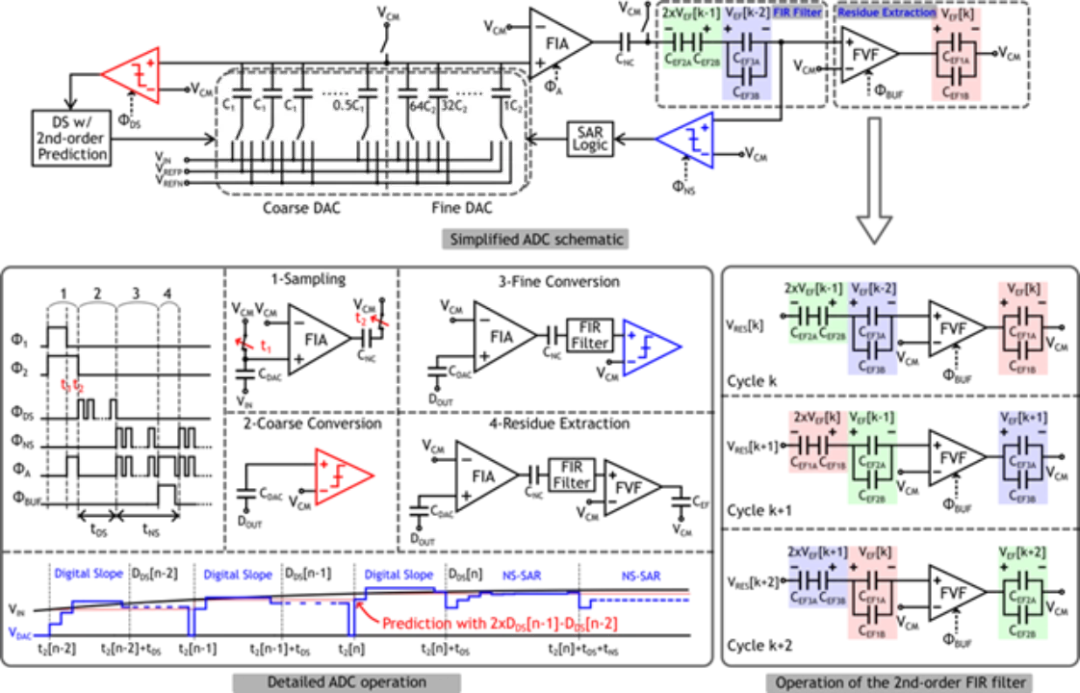
(a) 缩放式模数转换器电路及原理图
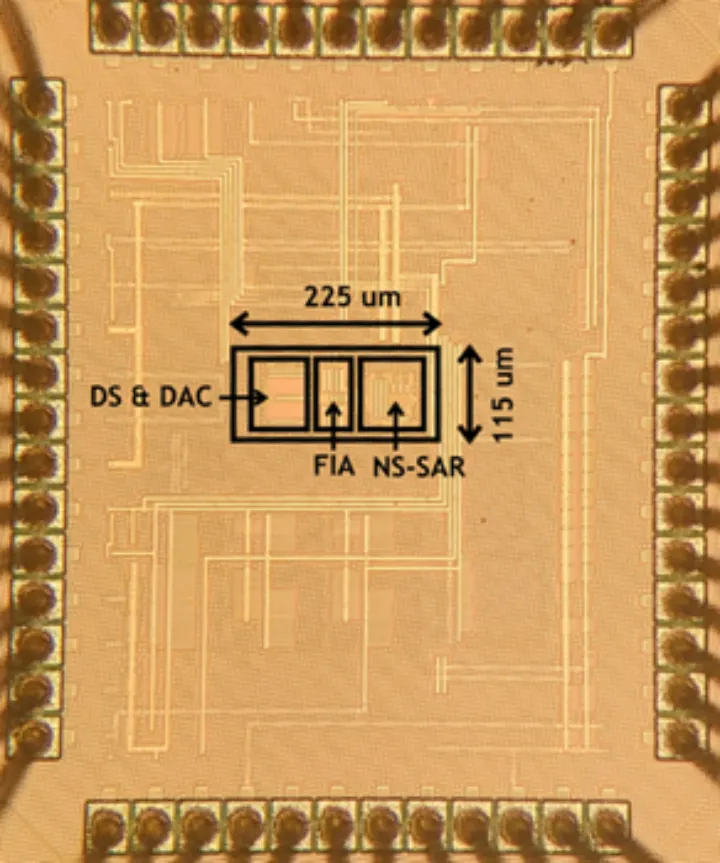
(b)缩放式模数转换器芯片显微照片
以上北京大学论文的相关研究工作得到了国家重点研发计划、国家自然科学基金、北京市科委、浙江省重点研发计划等项目的资助,以及国家集成电路产教融合创新平台、微纳电子器件与集成技术全国重点实验室、微电子器件与电路教育部重点实验室、集成电路高精尖创新中心、集成电路科学与未来技术北京实验室等基地平台和浙江省北大信息技术高等研究院、杭州微纳核芯电子科技有限公司的支持。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。