Particle Filter - Kidnapped vehicle project


1. Definition of Particle Filter
粒子滤波器是贝叶斯滤波器或马尔可夫定位滤波器的实现。粒子过滤器基于“适者生存的原理”主要用于解决定位问题。粒子滤波的优势在于易于编程并且灵活。 三种滤波器的性能对比:

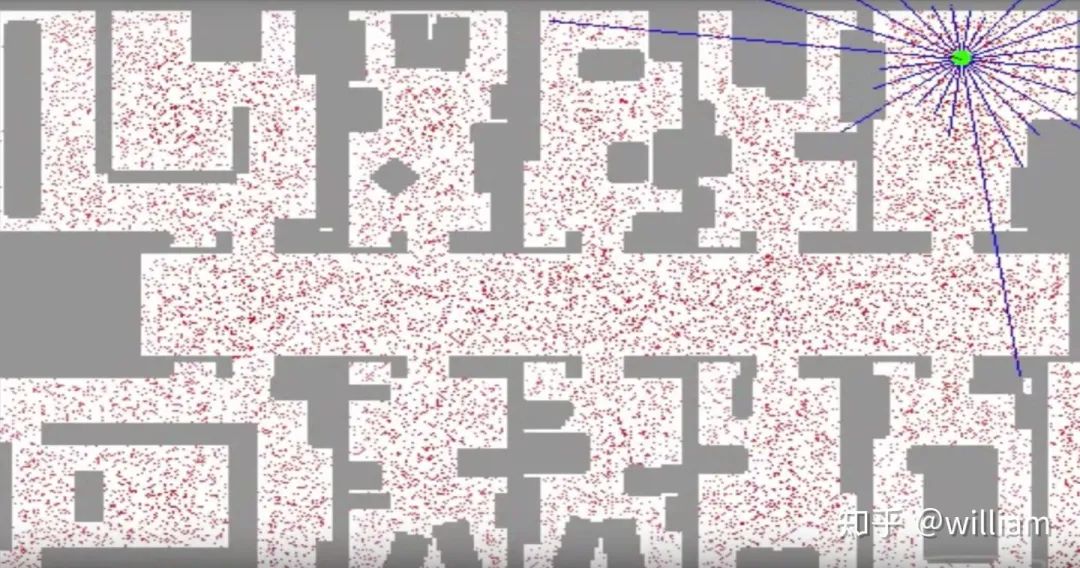
正如你在上面的图片中看到的,红点是对机器人可能位置的离散猜测。每个红点都有 x 坐标、 y 坐标和方向。粒子滤波器是由几千个这样的猜测组成的机器人后验信度表示。一开始,粒子是均匀分布的,但过滤器使他们生存的比例正比于粒子与传感器测量的一致性。
权重(Weights):

粒子滤波器通常携带离散数量的粒子。每个粒子都是一个包含 x 坐标、 y 坐标和方向的矢量。颗粒的存活取决于它们与传感器测量结果的一致性。一致性是基于实际测量和预测测量之间的匹配度来衡量的,这种匹配度称为权重。

权重意味着粒子的实际测量与预测测量的接近程度。在粒子滤波器中,粒子权重越大,生存概率越高。换句话说,每个粒子的生存概率与权重成正比。
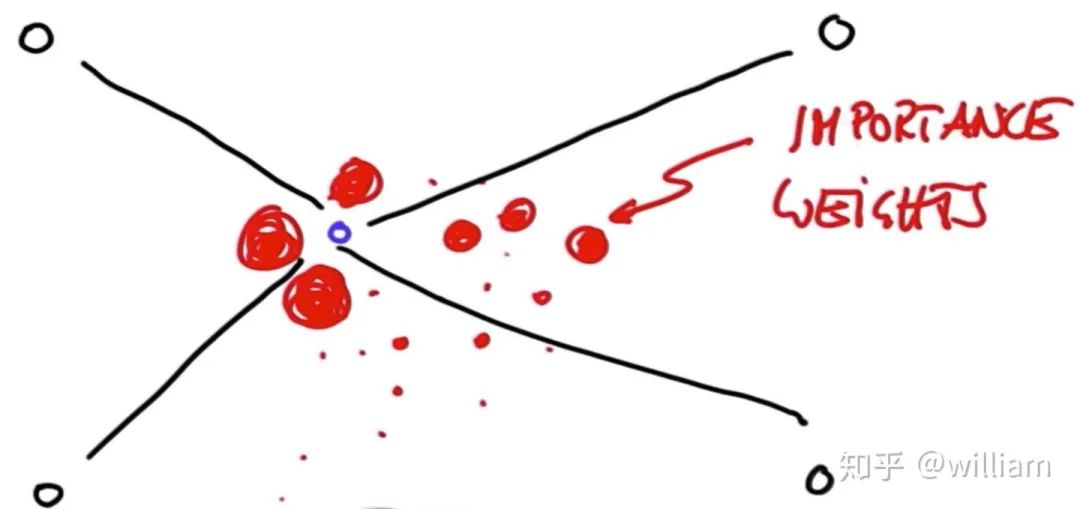
重采样(Resampling)
重采样技术是用于从旧粒子中随机抽取N个新粒子,并根据重要权重按比例进行置换。重采样后,权重较大的粒子可能会停留下来,其他粒子可能会消失。粒子聚集在后验概率比较高的区域。 为了进行重采样,采用了重采样轮技术.
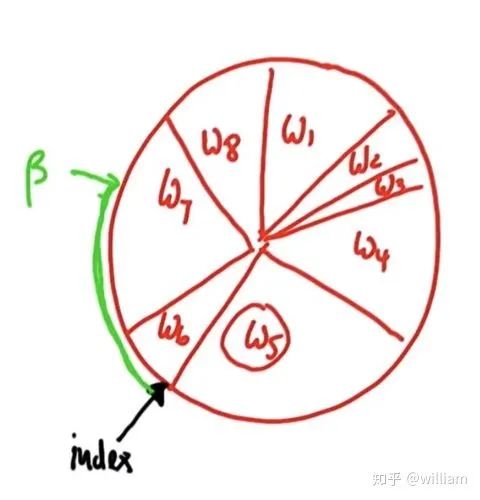
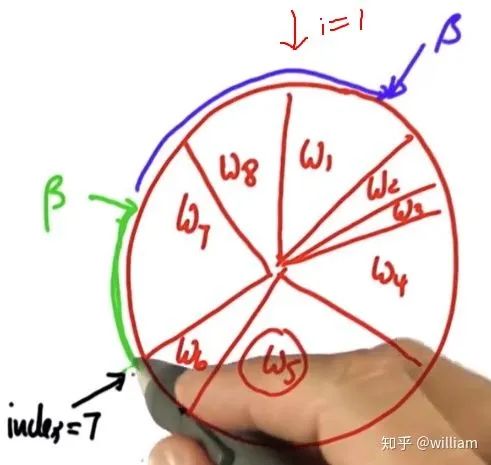
原理:每个粒子被选中的概率都和这个粒子轮所占的周长成正比,权重大的粒子有更多的机会被选中。 初始index为6,假设随机的beta= 0 + 随机权重> w6, 则index +1,beta=beta-w6. 此时beta < w7, 7号粒子被选中添加到仓库中。之后进行下一轮循环,此时beta 和 index 仍然保留前一轮循环的值, beta= beta + 随机权重 > w7 + w8, 因此index递增两次,到达index=1,此时w1 > beta, w1被选中放入仓库中, 随后进行下一轮循环。 重采样的代码:
p3 = [] index= int(random.random()*N) beta=0.0 mw=max(w) for i in range(N): beta +=random.random()*2.0*mw while beta>w[index]: beta-=w[index] index=(index+1)%N p3.append(p[index]) p=p3
2. Particle Filters implementation
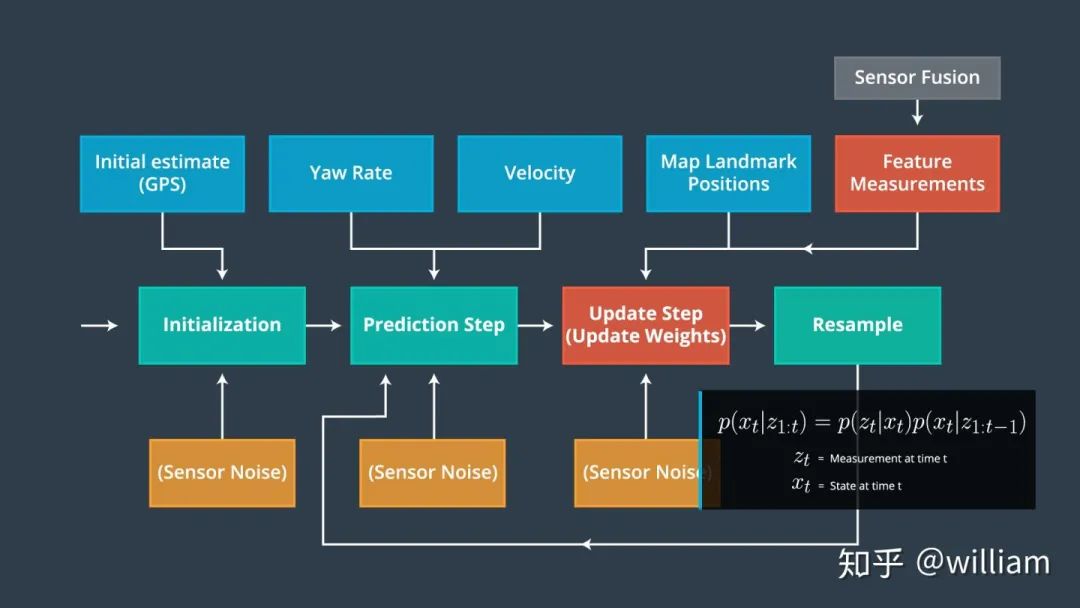
粒子过滤器有四个主要步骤:
初始化步骤: 我们从 GPS 输入估计我们的位置。在这个过程中的后续步骤将完善这个估计,以定位我们的车辆
预测步骤: 在预测步骤中,我们添加了所有粒子的控制输入(偏航速度和速度)
粒子权重更新步骤: 在更新步骤中,我们使用地图地标位置和特征的测量更新粒子权重
重采样步骤: 在重采样期间,我们将重采样 m 次(m 是0到 length_of_particleArray的范围)绘制粒子 i (i 是粒子index)与其权重成正比。这一步使用了重采样轮技术。
新的粒子代表了贝叶斯滤波后验概率。我们现在有一个基于输入证明的车辆位置的精确估计。
伪代码:

1. 初始化步骤:
粒子过滤器的第一件事就是初始化所有的粒子。在这一步,我们必须决定要使用多少粒子。一般来说,我们必须拿出一个好的数字,因为如果不会太小,将容易出错,如果太多会拖慢贝叶斯滤波器的速度。传统的粒子初始化方式是把状态空间划分成一个网格,并在每个单元格中放置一个粒子,但这种方式只能适合小状态空间,如果状态空间是地球,这是不合适的。因此用 GPS位置输入来初始估计我们的粒子分布是最实用的。值得注意的是,所有传感器的测量结果必然伴随着噪声,为了模拟真实的噪声不可控情况,应考虑给本项目的初始 GPS 位置和航向添加高斯噪声。 项目的最终初始化步骤代码:
void ParticleFilter::init(double x, double y, double theta, double std[]) {
/**
* TODO: Set the number of particles. Initialize all particles to
* first position (based on estimates of x, y, theta and their uncertainties
* from GPS) and all weights to 1.
* TODO: Add random Gaussian noise to each particle.
* NOTE: Consult particle_filter.h for more information about this method
* (and others in this file).
*/
if (is_initialized) {
return;
}
num_particles = 100; // TODO: Set the number of particle
double std_x = std[0];
double std_y = std[1];
double std_theta = std[2];
// Normal distributions
normal_distributiondist_x(x, std_x);
normal_distributiondist_y(y, std_y);
normal_distributiondist_theta(theta, std_theta);
// Generate particles with normal distribution with mean on GPS values.
for (int i = 0; i 2. 预测步骤: 现在我们已经初始化了粒子,是时候预测车辆的位置了。在这里,我们将使用下面的公式来预测车辆将在下一个时间步骤,通过基于偏航速度和速度的更新,同时考虑高斯传感器噪声。
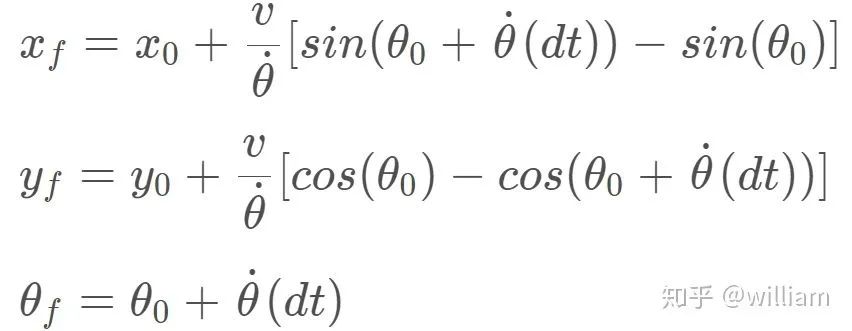
项目的最终预测步骤代码:
for (int i = 0; i < num_particles; i++) { if (fabs(yaw_rate) >= 0.00001) { particles[i].x += (velocity / yaw_rate) * (sin(particles[i].theta + yaw_rate * delta_t) - sin(particles[i].theta)); particles[i].y += (velocity / yaw_rate) * (cos(particles[i].theta) - cos(particles[i].theta + yaw_rate * delta_t)); particles[i].theta += yaw_rate * delta_t; } else { particles[i].x += velocity * delta_t * cos(particles[i].theta); particles[i].y += velocity * delta_t * sin(particles[i].theta); } // Add noise particles[i].x += disX(gen); particles[i].y += disY(gen); particles[i].theta += angle_theta(gen); }
3. 更新步骤:
现在,我们已经将速度和偏航率测量输入纳入到我们的过滤器中,我们必须更新基于激光雷达和雷达地标读数的粒子权重。 更新步骤有三个主要步骤:
Transformation
Association
Update Weights
转换 (Transformation) 我们首先需要将汽车的测量数据从当地的汽车坐标系转换为地图上的坐标系。

通过传递车辆观测坐标(xc 和 yc)、地图粒子坐标(xp 和 yp)和我们的旋转角度(- 90度) ,通过齐次变换矩阵,车辆坐标系中的观测值可以转换为地图坐标(xm 和 ym) 。这个齐次的变换矩阵,如下所示,执行旋转和平移。
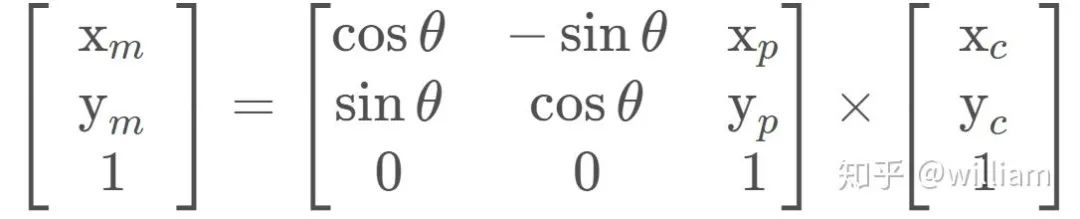
矩阵乘法的结果是:
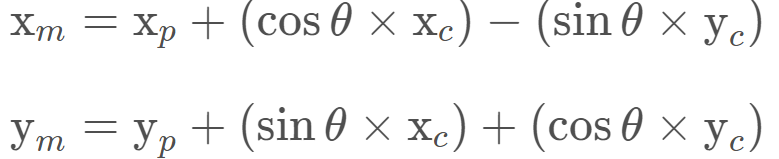
代码
double x_part, y_part, x_obs, y_obs, theta;
double x_map;
x_map = x_part + (cos(theta) * x_obs) - (sin(theta) * y_obs);
double y_map;
y_map = y_part + (sin(theta) * x_obs) + (cos(theta) * y_obs);
备注: 黑色方框是一个粒子,我们需要更新他的权重,(4,5) 是它在地图坐标中的位置,它的航向是(-90度),由于传感器对路标的测量结果是基于车辆本身坐标,因此我们要把车辆的观察数据转换为地图坐标。如L1路标的真实地图坐标是(5,3),车辆传感器测得的OBS2的车辆坐标为(2,2), 经过齐次矩阵转换后的地图坐标是(6,3), 现在我们就可以将测量结果与真实结果联系起来,匹配现实世界中的地标, 从而更新黑色方框粒子的权重。
联系 (Association )
联系问题是在现实世界中地标测量与物体匹配的问题,如地图地标. 我们的最终目标是为每个粒子找到一个权重参数,这个权重参数代表这个粒子与实际汽车在同一位置的匹配程度。
现在已经将观测值转换为地图的坐标空间,下一步是将每个转换后的观测值与一个地标识符关联起来。在上面的地图练习中,我们总共有5个地标,每个都被确定为 L1,L2,L3,L4,L5,每个都有一个已知的地图位置。我们需要将每个转换观察 TOBS1,TOBS2,TOBS3与这5个识别符之一联系起来。为了做到这一点,我们必须将最接近的地标与每一个转化的观察联系起来。
TOBS1 = (6,3), TOBS2 = (2,2) and TOBS3 = (0,5). OBS1匹配L1,OBS2匹配L2,OBS3匹配L2或者L5(距离相同)。
下面的例子来解释关于数据关联的问题。
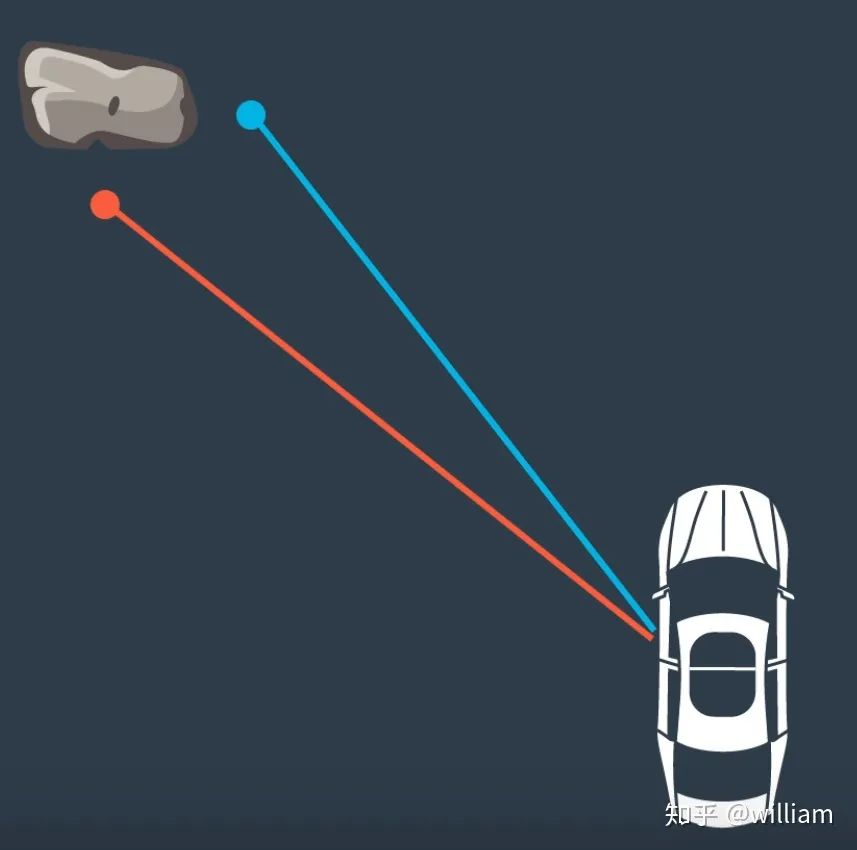
在这种情况下,我们有两个激光雷达测量岩石。我们需要找出这两个测量值中,哪一个与岩石相对应。如果我们估计,任何测量是真实的,汽车的位置将根据我们选择的测量是不同的。也就是说,根据路标选择的不同, 最终确定的车辆位置也会不同。
由于我们有多个测量的地标,我们可以使用最近邻技术找到正确的一个。
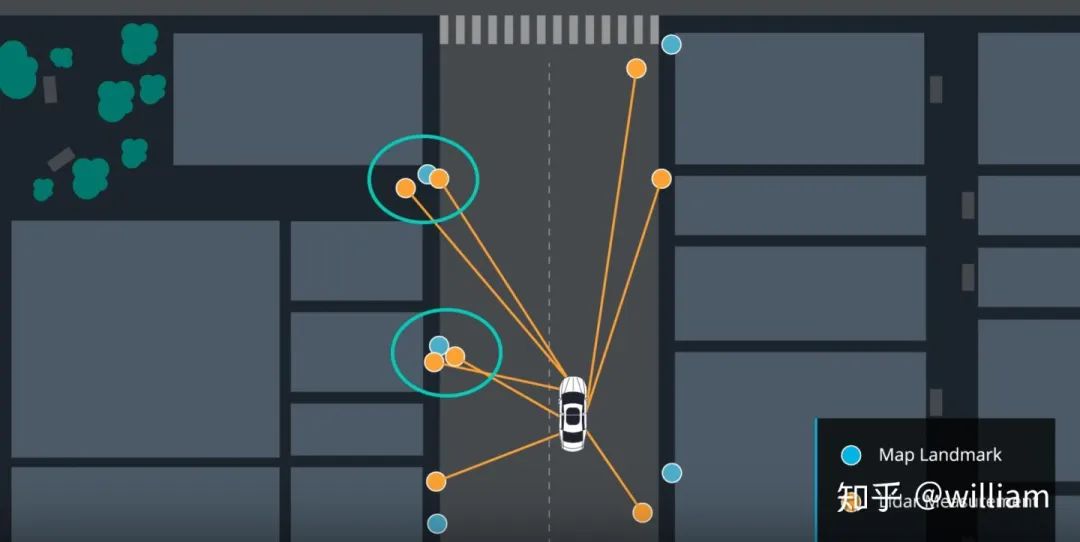
在这种方法中,我们将最接近的测量作为正确的测量。

最紧邻法的优缺点:

更新权重 (update weights)
现在我们已经完成了测量转换和关联,我们有了计算粒子最终权重所需的所有部分。粒子的最终权重将计算为每个测量的多元-高斯概率密度的乘积。
多元-高斯概率密度有两个维度,x 和 y。多元高斯分布的均值是测量的相关地标位置,多元高斯分布的标准差是由我们在 x 和 y 范围内的初始不确定度来描述的。多元-高斯的评估基于转换后的测量位置。多元高斯分布的公式如下。
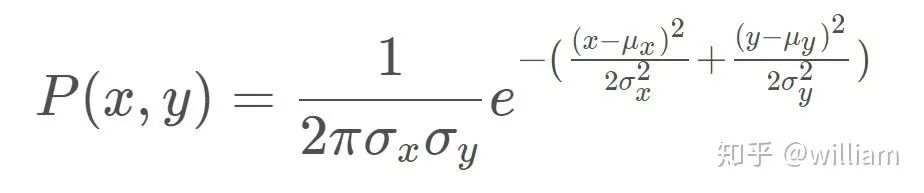
备注:x, y 是地图坐标系的观测值,μx, μy是最近的路标的地图坐标。如对于OBS2 (x,y) =(2,2), (μx, μy)= (2,1)
误差计算公式:

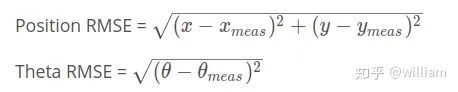
其中x, y, theta代表最好的粒子位置,xmeas, ymeas, thetameas代表真实值
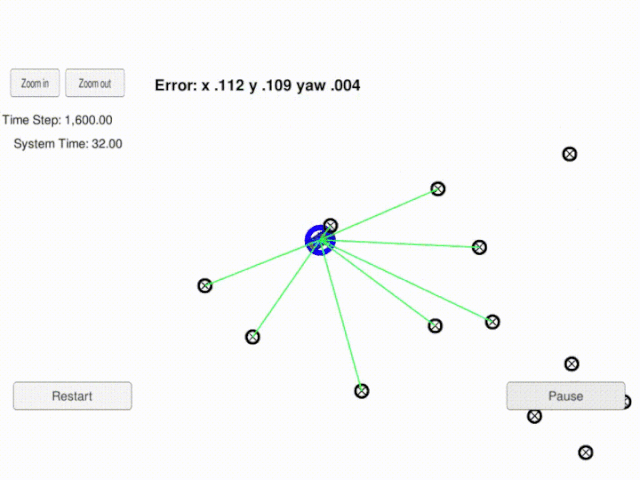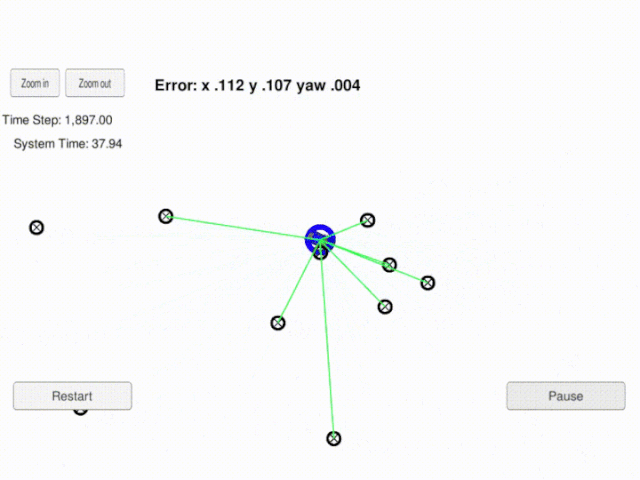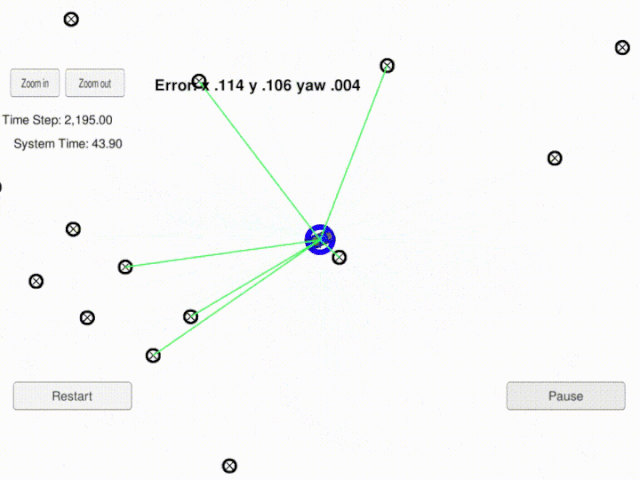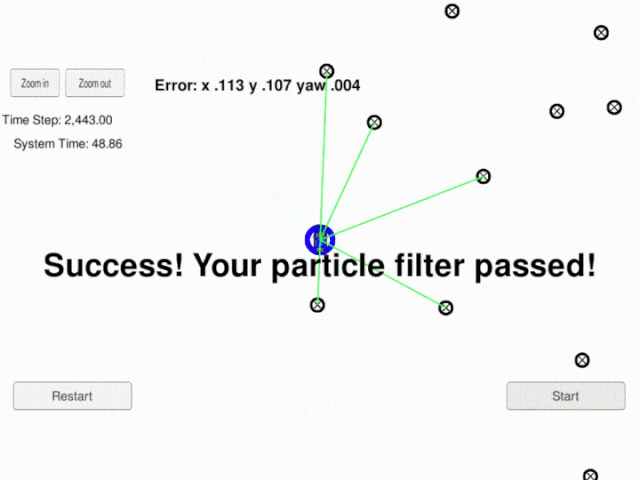
3. Project Demo