智能座舱中新技术、新场景、新模式不断涌现,设计师需要考虑如何让驾驶员在驾驶车辆时有安全、高效、舒适的人机交互体验,多模态交互将会成为未来人机交互的主流。
什么是智能座舱与多模态交互
跟传统座舱相比,智能座舱的“智能”主要体现在以下几个方面: 智能化:App远程控制、智能形象+语音欢迎语等; 科技性:高精地图、智能导航、疲劳监测、驾驶坐姿调整等; 易用性:多屏互联(中控屏、仪表盘)等; 安全感:底盘操控、驾乘品质感等; 人性化:自动泊车、寻找充电桩、自动充电等; 第三空间:沉浸式座舱、智能游戏等。
什么是多模态交互
“多模态交互”就是融合了人的视觉、听觉、触觉、嗅觉等多种感官,计算机利用多种通信通道响应输入,并充分模拟人与人之间的交互方式。
智能座舱中常见的模态有哪些?
目前智能座舱的模态包括视觉、听觉、触觉、嗅觉,对应的模态在智能座舱的体现:
视觉:HUD+仪表盘+中控+后视镜+氛围灯
听觉:音乐+语音交互+警示音
触觉:方向盘+按键+中控+挡位+座椅+安全带更多用于提示场景
手势:隔空控制音量、切换歌曲、控制车窗等场景
嗅觉:不同气味用于不同场景,疲劳场景可提神
智能座舱常见模态的优缺点
智能座舱的大部分的信息都放在视觉通道里面,这无疑会增加驾驶员的认知负荷,单模态交互难以满足复杂的驾驶场景,各模块彼此间的关联性不强,大大降低了信息感知的价值。
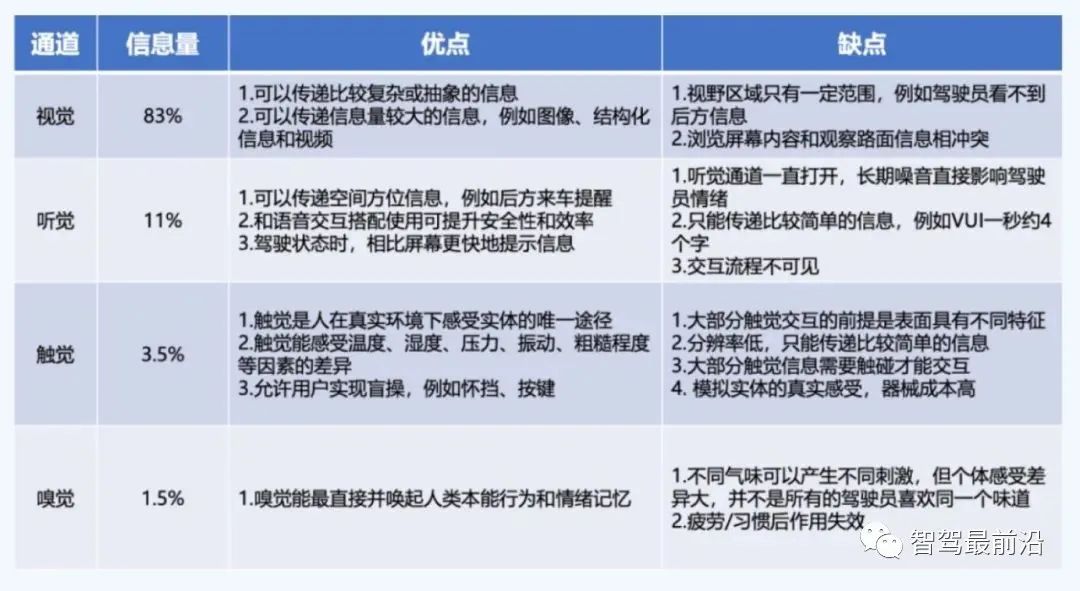
如何实现高效、安全、易用的人机交互,避免驾驶员注意力分散,降低交互认知和改善人车交互体验是值得思考的问题。
多模态的交互如何改善驾驶过程的安全与效率?
智能座舱为什么需要多模态交互
研究表明,人更习惯多模态交互,尤其高优先级消息以多模态的冗余增益可以加快处理时间,例如视觉+听觉或视觉+振动触觉警告比单模警告拥有更快响应。
通过【多重资源理论】和【态势感知】两个模型来进行分析
多重资源理论:一个通道接收的信息是有上限的,当信息过载时,会导致人的认知负荷,从而降低效率。为避免视觉通道超负荷,可以将部分信息通过听觉通道呈现,这能有效降低司机的工作负荷。
态势感知:态势感知是一种感受者根据环境因素而动态、整体地理解当前情境的能力,由此可以提升对安全风险的发现识别、理解分析及响应能力,以便于做出最终的决策与行动。 比如,对新手司机来说在驾驶中,会比较关注路面,这时候如果在视觉上弹出信息,就很容易分散注意力,这就是态势感知的丧失。而通过语音或者触觉的通道去反馈,可以提高了安全性和效率。

智能座舱多模态交互的重要性对驾驶员行为和状态进行多模监测
通过对方向盘的转向,行驶轨迹,油门的加减速,以及视觉摄像头的分析,可以判断驾驶员是否在开启ADAS系统后,处于瞌睡、疲劳、分心等脱离驾驶状态中。
多模提示让驾驶员保持良好的态势感知
当车辆开启ACC(AdapTIve Cruise Control)功能时,车辆监测车外环境,包括其他车辆的运动状态、特定工况等,结合车内动态信息显示在AR-HUD上,比如当下时速、车距、基本车辆信息,帮助驾驶员判断前车运动轨迹,增强态势感知,降低驾驶员工作负荷,及时作出有效判断及行动。
智能座舱多模态交互的应用
1. 语音+视觉
语音交互在实际应用中是不可见的,如果不与其他模态进行融合,很难预判出他们发出的指令处于哪个状态。比如在进行语音命令时,它产生的状态有:唤醒-聆听-识别-播报-持续倾听,通过中控屏幕上的语音虚拟形象状态属性来区别不同阶段,可以提高驾驶员的安全感。

2. 视觉+触觉
小鹏P7打开车道辅助时,为了减少驾驶员在开车时低头看仪表盘,方向盘会通过抖动的方式来提示目前车辆压线的状态;另外,还可以通过方向盘的物理按键唤醒语音,语音虚拟形象的状态变化显示在中控屏上。
除了常规的多模态交互以外,在广义的模态交互还包括了什么?
通过面部特征识别分析当前驾驶者的坐姿设置,自动调节座椅和方向盘高度换而言之,通过眼动追踪、心电、呼吸特征监测驾驶者是否疲劳、身体异常、分神等异常情况,进行多模态警示,来保障驾驶者的安全。









