关于STM32库函数的代码性能对比
ST 已经推出了三种库函数,用以方便客户快速开发STM32系列的 MCU。从最早的标准外设驱动库,到后来的 Cube HAL , 再到 Cube LL,还有直接写寄存器。这几种库的代码效率到底如何呢?本文将针对这个问题进行分析和对比,最后提供对比数据供大家参考。
问题分析
我们以 GPIO 翻转、tiM PWM 输出、ADC DMA数据采集和 DMA M2M 这四个常用功能,通过不同的库函数来实现,最终来对比各个库函数的性能。四个工程代码的内容简述如下:
GPIO 翻转:切换 GPIO 的输出电平,其中包含了系统时钟初始化和 GPIO 翻转的代码。
TIM PWM 输出:通过 TIM1 的通道 1 输出频率是 36KHz 的 PWM,循环修改其占空比从 25%到 50%,其中包含了系统时钟初始化、TIM1 的初始化和切换占空比的代码。
ADC DMA 数据采集:通过 ADC 的模拟通道 1,采集 100 次 ADC 的结果,并使用 DMA 传输到到用户缓冲区,其中包含了系统时钟初始化、ADC 初始化和 DMA 的初始化的代码。
DMA M2M:使用 DMA1 的通道 1,从 Flash 中传输 100 字节的数据到片内的 SRAM 中。其中包含了系统时钟的初始化和 DMA的初始化代码。
主要对比三个参数:Flash 占用量、SRAM 占用量和执行代码的效率。
Flash 和 SRAM 的占用量可以通过查看 IAR 生成的*.map 文件了解到。

在*.map 文件中,会有如上图的内容,其中的 readonly code memory 加上 readonly data memory 的和,就是 Flash 的占用量。而 Readwrite data memory 的大小即为 SRAM 的占用量。那么上图所示的 Flash 占用量即为 3204=3174+30,SRAM 占用量即为 1032。因用户堆(Cstack)我们设置的为 1024,所以真正应用代码所占用的 SRAM 量为 8=1032-1024.
代码的运行效率部分,我们是通过 IAR 提供的内核运行周期数(CYCLECONTER)来计算的。在功能函数的开始处和结束处分别设置断点,两次内核运行周期数的差值,就是此处代码的运行周期。

测试硬件选用了 Nucleo-F302 评估板。软件环境和库函数详情如下:
• IAR V7.60
• Optimizations Level High (Size)
• STM32CubeMX V4.17
• Create Project with Copy the necessary library files
• STM32CubeF3 V1.60
• STM32F30x_DSP_StdPeriph_Lib_V1.2.3
• STM32F3xx CMSIS V2.3.0
测试结果如下:
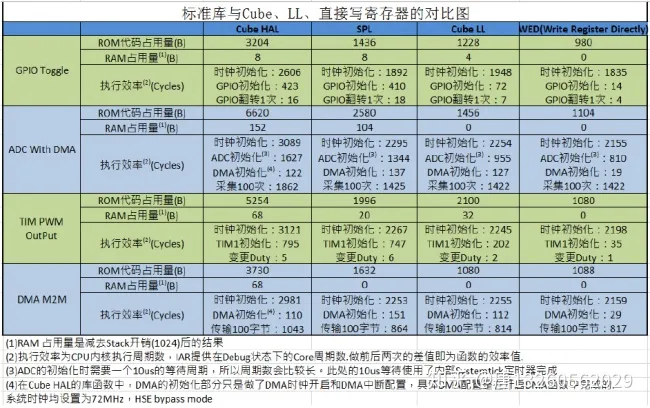
总结:
总体来看,代码效率与移植性成反比的规律是明显的。但与 Cube HAL 相比, Cube LL 的效率优势还是很明显的,几乎和直接写寄存器的效率相差无几。而且目前 STM32cubeMX 已经开始支持直接生成使用 Cube LL 的工程,对于以后追求效率的开发应用人员来说,非常值得推荐给大家使用。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。