翻开市面大部分编程教程,最早能够接触到的条件语句基本都是if-else。
作为高级编程语言都有的必备功能,if-else在嵌入式编程过程中几乎是必用。但任何东西都有限度,滥用它,只会让代码逐渐抽象、离谱,最后成为“屎山”。
接手项目的程序员叫苦不迭;忍无可忍的CTO对着满屏的if-else终于下定决心,下次逮着谁再写if-else,罚款1000块。
那么,为什么if-else这么不受待见,怎么干掉它,不滥用它?
if-else的两宗罪
实际上,我们并不是杜绝if-else,而是建议少用。
究其原因,一共有两点:一是影响程序的运行效率;二是影响代码的可读性,增大运维难度。
目前,大部分人的观点是if-else的分支预测(Branch Prediction)会降低执行效率。
CPU执行一条指令分为IF、ID、EX、WB四个阶段。分阶段执行(也就是pipeline流水线执行)会先给出一个预测结果,让流水线直接执行,执行对了则继续;执行错了,则退回去重新执行,直到对为止。

比如说,在这样的代码中:
int a = 0;
a += 1;
a += 2;
a += 3;
CPU并非运行完a=0后执行a +=1,而是在运行a=0读执行后,马上运行a +=1的读执行。
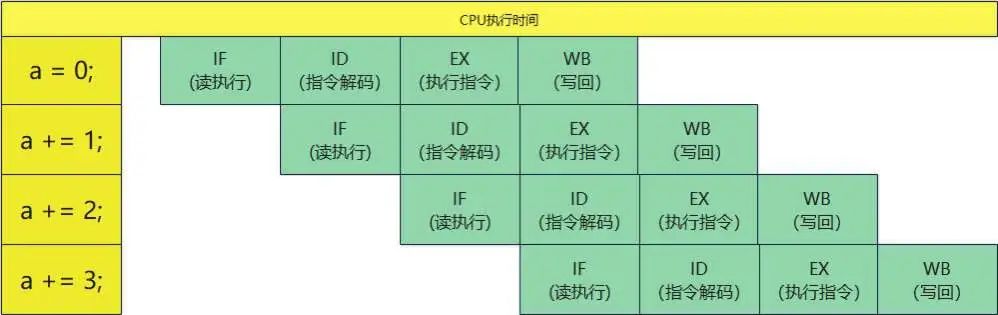
流水线执行的好处很多,但对if语句来说,就会开启分支预测,如果预测失败,就会影响执行时间。但未对数组排序前提下,分支预测大概率会失败,从而导致指令执行结束后重新读取下一条指令,无法发挥流水线效果。说白了,只有分支预测一直成功,CPU执行效率才会大幅提升。

不过,需要强调的是,所有带有跳转结构的语句比如if、switch、for都会出现这种情况。而且,现代CPU性能远超过去,只有存在巨大量if-else情况才会影响性能,即便出现性能问题,也得在一个结构清洗的架构上分析性能是不是才能更好的定位,实在不行也可以把这段替换成汇编。
所以相比来说,导致程序运行效率下降并非if-else的最大原罪,而是影响可读性。
代码本质是给人看的,人得能看懂,从上到下扫一下大概就明白设计意图、思路就是好代码,这样的代码也是基本没有if-else的,如果还需要反复从上看到下,再从下看到上,这样的代码及时这次看懂隔一段时间也会忘记的。也就是“高内聚,低耦合”。
许多工程师在接手老项目时,时常会收到扑面而来的是,代码中可能会充斥着大量的 if/else ,嵌套 6、7 层,一个函数几百行,多层判断让人无从下手,绝望、愤怒、无奈喷涌而出,而且这样的惨案已经不止发生过一次。总结成一句话就是,看死人。
这种代码风格早在几十年前就被国外所批判,并被称之为"箭头代码"(Arrow-code)。

实际工作中,我们能见到一个方法包含10个、20个甚至更多的逻辑分支的情况。而更为致命的情况就是if-else的多层嵌套。
代码的多层嵌套拥有很大隐患,也给代码库增加了很多不必要的复杂性。
人脑一次只能处理几件不同的事情,因此当面临需要深入分析多个代码层级时,很容易忘记上一层的关键逻辑,导致一些不必要的错误。
还是那句话,代码是给人看的,我们的业务流程已经足够复杂了,多层嵌套还会进一步增加了其复杂度。
if (someConditionIsMet) {
// ...
// ...
// ...
// 接下来是 100 行代码
// ...
// ...
// ...
// 还有 100 行
if (someOtherConditionIsMet) {
// ...
// ...
// ...
// 接下来是 100 行代码
// ...
// ...
// ...
if (yetAnotherConditionIsMet) {
// ...
// ...
// ...
// 接下来是 100 行代码
// ...
// ...
// ...
} else {
// 现在,处理边缘情况
}
// ...
// ...
// ...
} else {
// 现在,处理边缘情况
return someOtherResult;
}
// ...
// ...
// ...
} else {
// 现在,处理边缘情况
}
return someResult;
遇到这种情况怎么办,不要慌,直接干掉if-else。
怎么干掉if-else
第一种方法:排非策略
优化前
if (user && password) {
// 逻辑处理
} else {
throw('用户名和密码不能为空!')
}
优化后
if (!user || !password) return throw('用户名和密码不能为空!')
// 逻辑处理
第二种方法:三元运算符
三元运算符相比if-else来说,只需一行语句,代码简练精炼。
示例一
let allow = nullif(age >= 18){allow = '通过';} else {allow = '拒绝';}// 优化后let allow = age >= 18 ? '通过' : '拒绝'
示例二
if (flag) {
success();
} else {
fail();
}
//优化后
flag ? success() : fail();
第三种方法:使用switch、key-value和Map
if (this.type === 'A') {
this.handleA();
} else if (this.type === 'B') {
this.handleB();
} else if (this.type === 'C') {
this.handleC();
} else if (this.type === 'D') {
this.handleD();
} else {
this.handleE();
}
Switch显然更简单,而且,不同的条件分支之间没有嵌套,并且它们彼此独立,逻辑很清楚。不过,代码本身也会有点多。
switch(val){
case 'A':
handleA()
break
case 'B':
handleB()
break
case 'C':
handleC()
break
case 'D':
handleD()
break
}
此时key- value和Map就是很好的方法。
let enums = {
'A': handleA,
'B': handleB,
'C': handleC,
'D': handleD,
'E': handleE
}
function action(val){
let handleType = enums[val]
handleType()
}
let enums = new Map([
['A', handleA],
['B', handleB],
['C', handleC],
['D', handleD],
['E', handleE]
])
function action(val){
let handleType = enums(val)
handleType()
}
第四种方法:逻辑与运算符
有些时候我们可以使用逻辑与运算符来简化代码。
if( falg ){someMethod()}修改成:falg && someMethod();
第五种方法:使用 includes 处理多重条件
if( code === '202' || code === '203' || code === '204' ){someMethod()}修改成if( ['202','203','204'].includes(code) ){someMethod()}
第六种方法:责任链模式和策略模式
责任链模式是实现了类似“流水线”结构的逐级处理,通常是一条链式结构,将“抽象处理者”的不同实现串联起来。策略模式的目的是将算法的使用与定义解耦,能够实现根据规则路由到不同策略类进行处理。
当然,并不是说用if-else就很low,用设计模式就高大上,二者擅长场景不同,if-else足以满足大部分日常需求的开发,且简单、灵活、可靠,而设计模式则是为了更简洁、拓展性好、性能更优、可读性更好等。
抛弃else吧,你会打开新世界
当然,无论哪种重构方法,都只是优化。归结起来,最简单的方法就是在写代码之处,抛弃else。抛弃 else 就可以减少嵌套层数,有效降低代码复杂度。让代码更简单,结构更清晰,更容易维护。
如果我们抛弃 if-else 块中的 else 并优先处理这块逻辑。先处理小的边界情况,如果必要的话提前返回;否则,将主流程保留在函数的最外层。
if (!someConditionIsMet) {// 首先处理那个边缘情况return someResultOrNothing;}// 主流程可以继续,不需要额外的保护块// ...// ...// ...// 再加 100 行代码// ...// ...// ...// 还有 100 行return someResult;
同样的思路也可以应用于处理多个边缘情况:
if (!someConditionIsMet) {// 首先处理那个边缘情况return someResultOrNothing;}if (!someOtherConditionIsMet) {// 首先处理那个边缘情况return someResultOrNothing;}if (!yetAnotherConditionIsMet) {// 首先处理那个边缘情况return someResultOrNothing;}// 主流程可以继续,不需要额外的保护块// ...// ...// ...// 再加 100 行代码// ...// ...本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。