L2+ADAS/AD传感器及系统架构设计
根据高工智能汽车研究院最新发布的《2022年度中国市场乘用车标配L2+NOA功能智驾域控制器芯片方案市场份额榜单》显示,地平线市场份额达49.05%,排名第一
随着地平线的大势,芯驰的X9也打着顺风车起量,部分域控制器还带着芯驰的E3
如上天准TADC域控制器即是基于地平线征程5和芯驰X9、E3系列产品的高阶自动驾驶域控制器方案;
东软睿驰也基于地平线征程5、芯驰科技X9U系列芯片,构建了国内首个全国产化自动驾驶域控制器平台,实现国产化芯片、算法、软件、硬件从研发到量产应用全方面全链条打通,该产品已获得某国内主流车型量产定点,即将于2023年下半年量产上市。
有意思的一点,自动驾驶域控制器中和地平线搭配的芯驰X9是一颗座舱芯片;
为什么会有这样的配合?在全国产的自动驾驶域控制器中,为什么会需要地平线NPU,芯驰CPU,和一颗功能安全MCU这样的组合?
带着这些疑问,小二和业内资深专家请教交流,结合部分公开资料,做个分享
1
L2+ADAS/AD传感器及系统架构概览
L2+ ADAS/AD配套的传感器方面,摄像头、毫米波雷达甚至激光雷达,都是有技术上的需求的,常见的视觉和雷达“满负荷”传感器架构如下图:
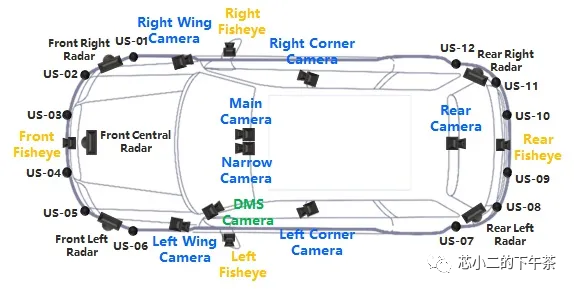
如果摄像头配置较多,可能方案如下
11V(12V) - 5R - 3L - 12USS - 1DMS
11V(12V) - 5R - 2L - 12USS - 1DMS
11V(12V) - 5R - 1L - 12USS - 1DMS
如果摄像头配置较少,可能方案如下
7V - 5R - 1L - 12USS - 1DMS
本文重点不做传感器架构的说明,有兴趣的可以参考这篇文章: https://mp.weixin.qq.com/s/Sh4ONJxrmvDbfWlcDnXYtQ
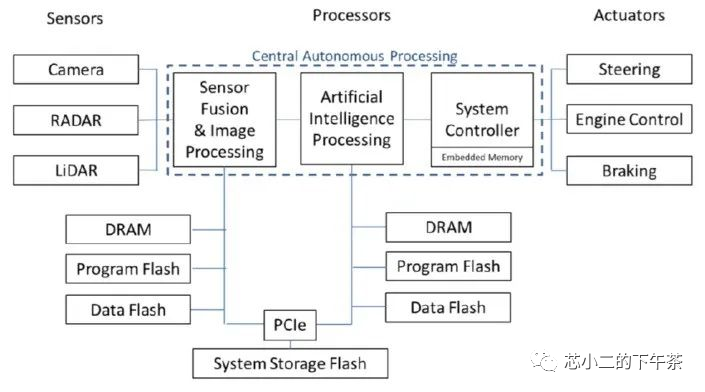
系统层面的ADAS域控制器系统如下,图中的Central Automomous Processing中的三个组成,即需要的三类不同的算力;
2
算力要求
如下,是从焉知汽车转载的一张传感器数据处理架构
据估算,假设 一辆自动驾驶汽车配置了GPS、声纳、 相机、雷达和激光雷达等传感器,则上述传感器每秒钟产生的数据将是:50kB(GPS)+10-100kB(声呐)+20-40MB(相机)+10-100kB(雷达)
而针对如此大量的数据处理,可以分为前处理,机器学习处理,后处理三个主要步骤,如下图
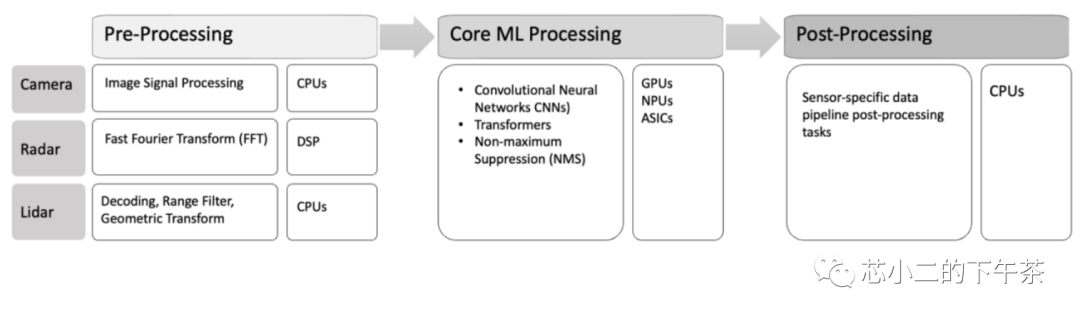
上图中,每个步骤右边白色小框的即是承担主要任务的算力类型,即CPU算力,GPU/NPU算力;
市场主流的智驾芯片即参数,如下图
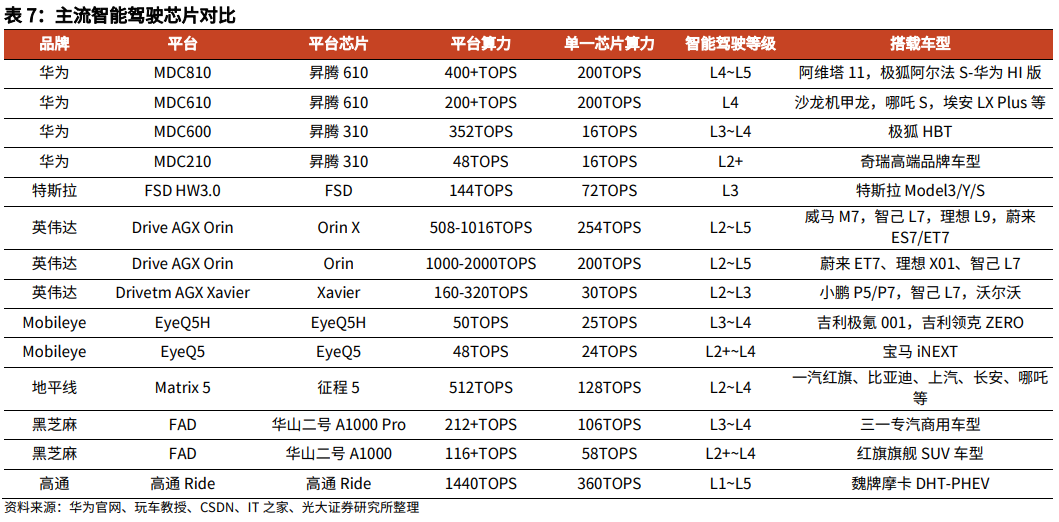
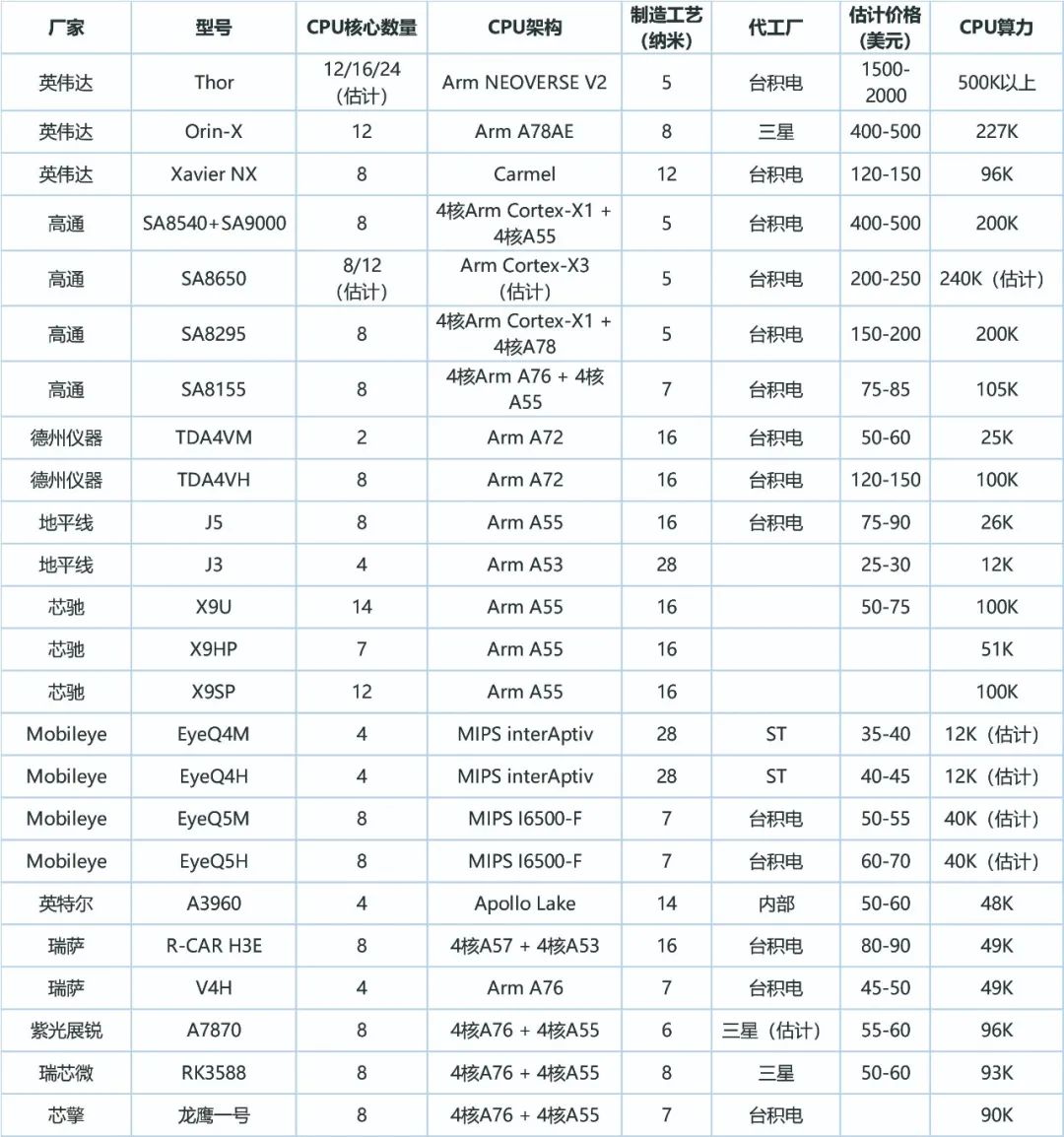
可以看到类似地平线的J5,提供了非常强悍的AI算力,如J5的单一芯片算力为128TOPS,但是其提供的CPU算力却非常有限,J5的CPU算力是26K
而芯驰的X9U,则能提供多达14个核(2颗X9HP合封,通过PCIe相连),高达100K的CPU算力
相信看了上述的数据,大家会有比较直观的认知;
3
不同算力区别
不同的算力的区别在哪里?我们通过单位来简单了解下:TOPS/DMIPS
TOPS是Tera Operation Per Second的缩写,表示每秒钟可以进行的操作数量,用于衡量自动驾驶的算力,
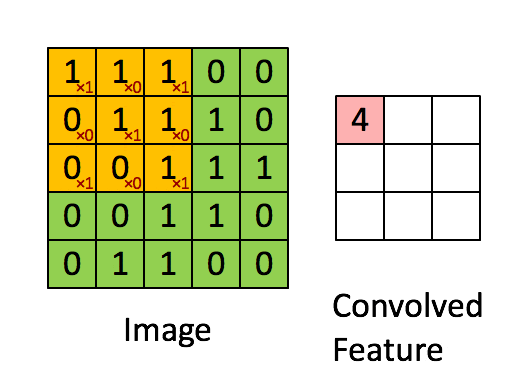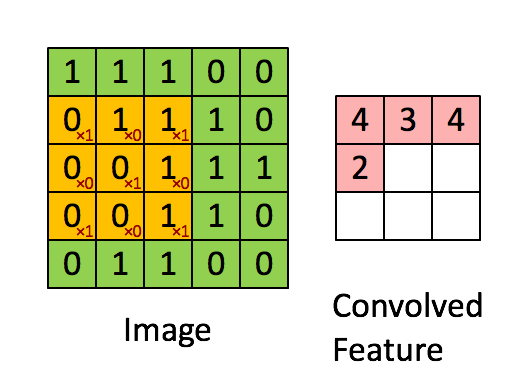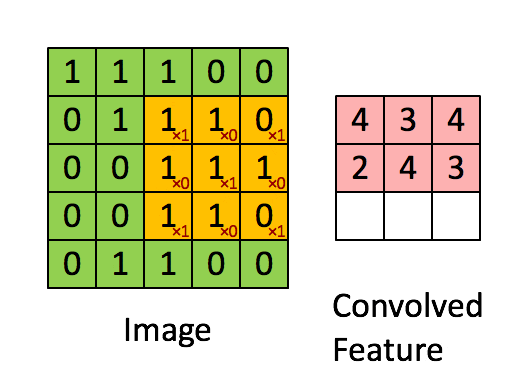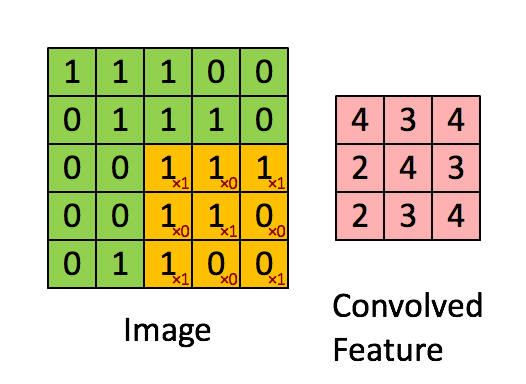
计算机视觉(Computer Vision)算法会消耗很大一部分自动驾驶芯片的算力,那么视觉处理能力为什么用TOPS评估呢?通常计算机视觉算法是基于卷积神经网络的,而卷积神经网络的本质是累积累加算法(Multiply Accumulate)
转自:知乎,泛亚汽车技术中心 Wayne
转自:知乎,泛亚汽车技术中心 Wayne
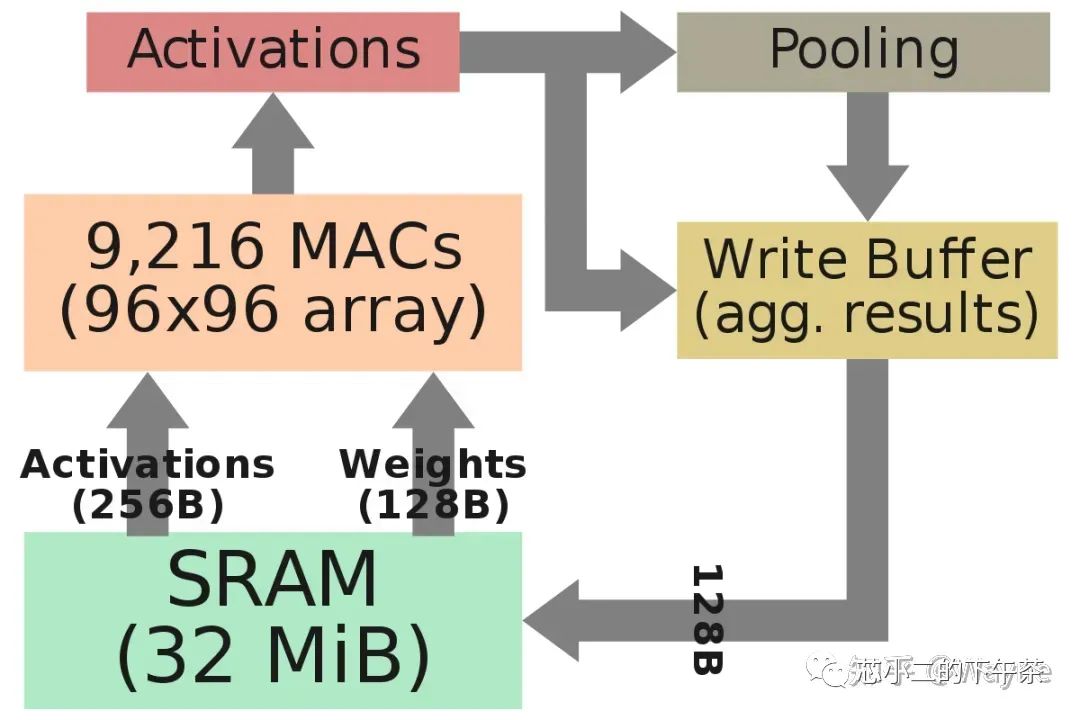
在每个周期中,将在整个MAC阵列中广播输入数据的底行和权重的最右列。每个单元独立执行适当的乘法累加运算。
在下一个循环中,将输入数据向下推一行,而将权重网格向右推一行。在整个数组中广播输入数据的最底行和权重的最右列,重复此过程。单元继续独立执行其操作。
全点积卷积结束时,MAC阵列一次向下移动一行96个元素,这也是SIMD单元的吞吐量。
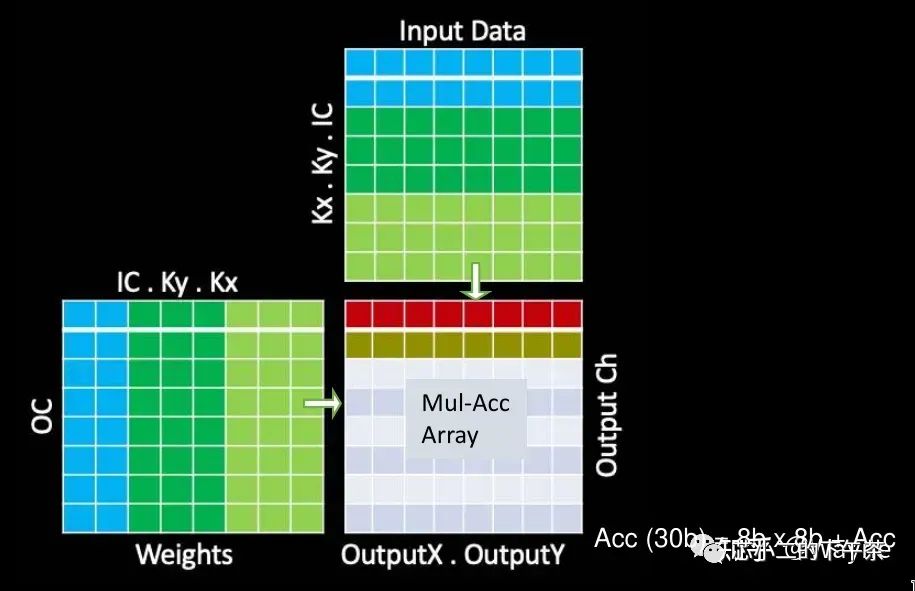
转自:知乎,泛亚汽车技术中心 Wayne
TOPS是MAC在1秒内操作的数,计算公式为: TOPS = MAC矩阵行 * MAC矩阵列 * 2 * 主频
MIPS是Million Instructions Per Second的缩写,每秒处理的百万级的机器语言指令数
为了排除不同的CPU指令集不同、硬件加速器不同、CPU架构不同带来的影响,业内出了一个跑分算法叫Dhrystone:程序用来测试CPU整数计算性能
其输出结果为每秒钟运行Dhrystone的次数,即每秒钟迭代主循环的次数是衡量CPU的整数计算性能的
DMIPS(DhrystoneMIPS),其含义为每秒钟执行Dhrystone的次数除以1757(这一数值来自于VAX 11/780机器,此机器在名义上为1MIPS机器,它每秒运行Dhrystone次数为1757次)
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。