从去年底到今年3月,与硅光芯片相关的报道又多了起来——从阿里巴巴达摩院将硅光芯片列入2022十大科技趋势、曦智科技(Lightelligence)发布高性能光子计算处理器PACE,到日前GlobalFoundries发布其硅光子工艺平台Fotonix、Marvell发布400G DR4硅光平台、AMD/Xilinx和Ranovus合作发布集成Versal ACAP和Ranovus Odin光通信模组的系统——那么,热闹的新闻背后,到底蕴藏着哪些新的市场商机?
突破摩尔定律限制
根据达摩院的趋势解读,硅光芯片的崛起、技术突破和快速迭代、以及高速增长的商业化需求,归因于云计算与人工智能的大爆发。大型分布式计算、大数据分析、云原生应用让数据中心内的数据通信密度大幅提升,数据移动成为性能瓶颈。传统光模块成本过高,难以大规模应用,硅光芯片则能够在低成本的前提下有效提高数据中心内集群之间、服务器之间、乃至于芯片之间的通信效率。
以超大型数据中心为例,根据Equnix的数据,2017年-2021年全球互联网带宽容量的年复合增长率达到了48%,2020年开始正式进入400G时代,并有望于2022年进入800G时代。届时,将有数百万个400GbE+的硅光子收发器与数十万台服务器互连,并将通过新型低延迟的DCI架构扩展AI的边缘,提升高性能计算的算力。
据Yole Development估计,硅光光模块市场将从2018年的约4.55亿美元增长到2024年的约40亿美元,复合年增长率达44.5%。而LightCouting的数据则显示,到2024年,硅光光模块市场市值将达65亿美金,占比高达60%,而在2020年,这一数字仅为3.3%。
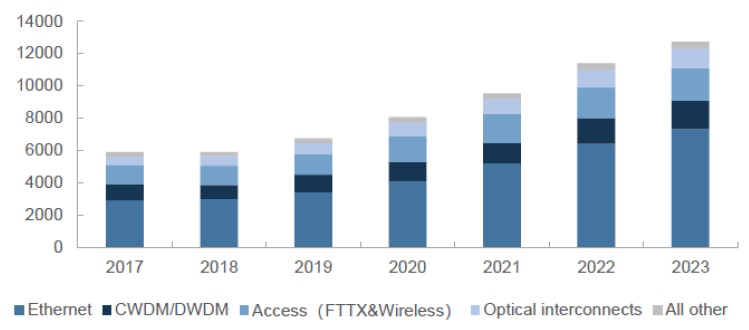
2017-2023年全球光模块市场规模及结构预测(资料来源:Lightcounting)
另一方面,据Open AI统计,自2012年,每3-4个月人工智能的算力需求就翻倍,当前电子芯片的发展逼近摩尔定律极限,难以满足高性能计算不断增长的数据吞吐需求,而硅光芯片具备的更高计算密度与更低能耗特性,正是极致算力场景下所需要的解决方案。
曦智科技创始人兼CEO沈亦晨博士此前在接受本刊采访时,将算力、数据传输和存储视作当前电子芯片在发展过程中遇到的三个主要瓶颈。以最具代表性的图像/语音识别类AI应用为例,数据显示,与2012年相比,当前最大的神经网络模型大约是当时的15-30万倍,且仍在持续增长。但与之形成鲜明对比的,是底层算力的增长远未达到这一幅度,制约了人工智能的进一步发展。
算力为什么难以跟上AI模型的演进速度?半导体制程微缩逐渐接近物理极限导致的摩尔定律放缓和晶体管功耗散热问题是两大主因。
“2015年以后,随着晶体管体积越来越小,隧穿现象日趋明显。这意味着,即使把单个晶体管做得再小,其在运算时的功耗也没办法进一步降低。但如果为了增强算力增加芯片面积,或是采用芯片级联的方式,功耗又会显著增长。”沈亦晨说,这就是为什么兼具高通量、高能效比、超低延迟特性的硅光技术能成为新兴技术方向之一的原因。
光计算成为新看点
自20世纪70年代末以来,光纤基础设施一直被用于长距离的通信信号传输,因为相比铜基电缆,光纤的带宽容量更大、数据速率更高,且延迟更低。从那时起,高能效光互连就不断渗入重要的电信网络,直至进入数据中心环境中的机架到机架数据链路。但随后越来越多的研究表明,硅光芯片不仅可以用于光通信,以神经网络计算和量子计算为代表的计算领域,也正成为其释放魅力的舞台。
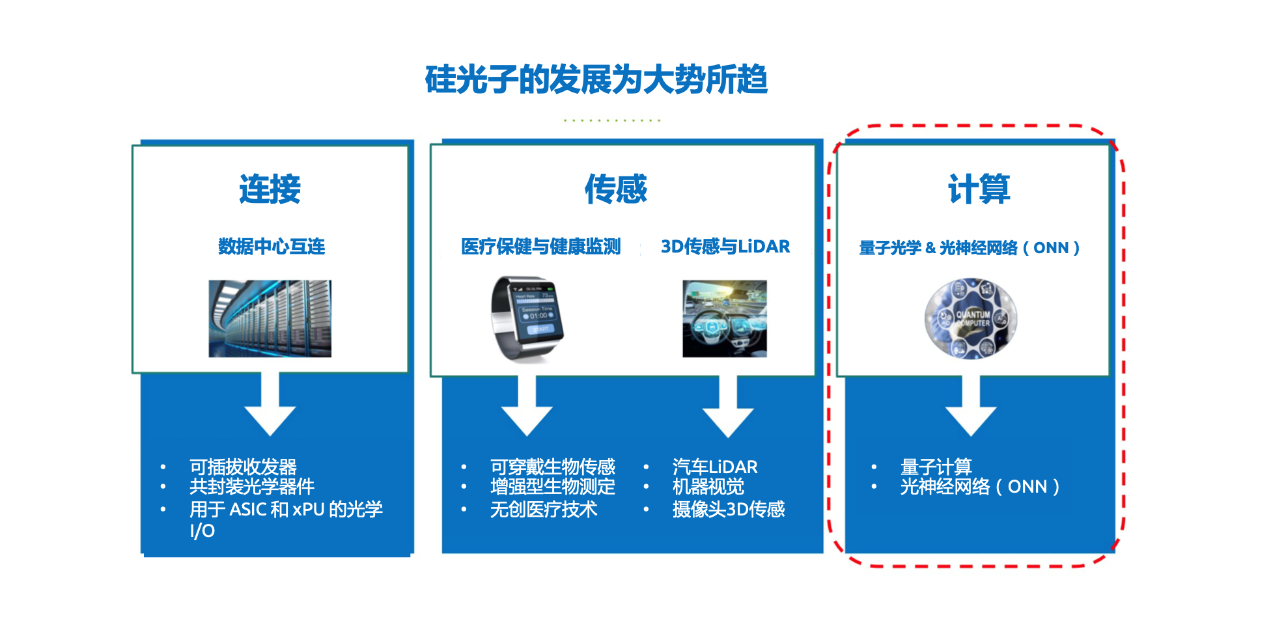
终端应用领域及市场趋势推动硅光子的技术发展 图源:soitec
Soitec全球业务部光子材料专家Corrado Sciancalepore在日前撰写的一篇文章中,详细介绍了硅光子是如何赋能量子计算和光神经网络市场的。
硅光子用于神经网络
与硅光用于通信传输领域极为相似的是,全光计算(all-optical computing)还可以用来实现更快的计算,而其功率预算仅为传统数字电子计算架构的一小部分。
众所周知,现在的数字计算机是基于晶体管的,它通过打开和关闭电子信号构成基本的逻辑门电路。但通过光来传输数据与计算数据则完全不同,因为光子器件线性度极高,通过级联不同级别的线性集成光子器件,就能够组成光神经网络(Optical Neural Network,ONN)的相应层。通过这种方式,仅仅依赖从ONN一端流向另一端的光,即可完成顺序矩阵的乘法或转置。
两家初创企业——Lightmatter和曦智科技都是光神经网络加速器领域的佼佼者。其中,曦智科技已经在2021年底发布了最新的高性能光子计算处理器——PACE(Photonic Arithmetic Computing Engine,光子计算引擎),其在单个光子芯片中集成了超过10,000个光子器件,运行1GHz系统时钟,算力是上一代处理器的100万倍以上,运行特定循环神经网络速度可达目前高端GPU的数百倍。

曦智科技最新光子计算处理器PACE
硅光子用于量子信息处理
量子技术现在已发展成为一个崭新的应用领域,通过在量子力学系统中对信息进行编码,继而处理、存储和传输的可能性,将为不同的技术领域带来巨大突破,例如计算、通信、计量、传感,甚至制造技术。与此同时,数量众多的量子解决方案初创公司,以及谷歌、IBM、英特尔、微软和东芝等行业巨头们无不齐头并进地大力投资于量子技术。
在所有技术中,硅光子被公认为一项关键技术,三点特质让它非常的与众不同:一是硅光子可以利用成熟的CMOS制造工艺,以低成本和高吞吐量实现复杂光电路和系统的商用;其二,它在本质上能与CMOS逻辑和数字电路共集成,能够为光电路提供片上电子驱动器和数据处理功能;其三,硅光子还能够集成其他光子材料,如SiN和III-V半导体。
协同封装与芯片整合
既然将硅光和CMOS的优势整合在一起,是一件“非常自然的事情”。沈亦晨也说他相信硅光子芯片“极有可能成为我们这个时代最重要的技术创新之一”,高能效、低延时和高通量也是光学矩阵运算能够超越摩尔定律,继续提升算力的关键所在,那么,这一刻会很快到来么?
Maybe Yes, maybe No
之所以会这么说,是因为当前硅光芯片的核心挑战主要来自产业链和工艺水平。例如,硅光芯片的设计、量产、封装等未形成标准化和规模化,进而导致其在产能、成本、良率上的优势还未显现;光计算领域的挑战是精度低于电子芯片,进而限制其应用场景,集成度也需要提高来提升算力,使得整体的商业化过程比较漫长。
如果要尽快突破上述瓶颈,硅光器件的未来将呈现两大趋势:协同封装与芯片整合。前者是通过TSV封装的形式,将CMOS芯片与光学芯片整合在一起;后者则是完全形成单芯片解决方案,不再需要任何铜线连接,主要应用于光学的输入和输出。
作为目前对硅光子技术投入力度最高的主流晶圆代工厂,格芯(GLOBALFOUNDRIES)近期推出的新一代颠覆性的硅光平台GF Fotonix为此做出了新的尝试。GF Fotonix是一个单芯片平台,在业界首先将差异化300mm光子功能和300GHz级别RF-CMOS结合在单个硅晶圆上,从而提供出色的性能。GF Fotonix通过在单个硅芯片上组合光子系统、射频(RF)元件、CMOS逻辑电路,将以前分布在多个芯片上的复杂工艺整合到了单个芯片上。
从性能指标来看,Fotonix的单位光纤数据传输速率达到了0.5Tbps/光纤,这样可以构建1.6-3.2Tbps的光学小芯片,从而提供更快速高效的数据传输,并带来更好的信号完整性。此外,由于系统误码率降低到了万分之一,它还能够支持下一代人工智能(AI)。
另一家积极布局硅光子技术的公司也不容小觑,那就是英特尔。英特尔研究院在2021年12月成立了面向数据中心互连的集成光电研究中心,该中心的使命是加速光互连输入/输出(I/O)技术在性能扩展和集成方面的创新,硅光子的晶圆级光学封装、无热且节能的可扩展大容量硅光子收发器等前沿项目赫然在列。
当然,并非每家企业都具有“一步到位将硅光子和CMOS整合在同一块芯片上”的实力,于是,利用协同封装光子(co-packaged optics,CPO)技术,将硅光模块和CMOS芯片集成在一起,成为了更多人的选择。
业内专家指出,在CPO技术兴起之前,目前的传统技术是把硅光模块和CMOS芯片独立成两个单独模块,然后在PCB板上连到一起。这么做的好处设计较为模块化,CMOS芯片或者硅光模块单独出问题的化都可以单独更换,但是在功耗、尺寸和成本上都较为不利,而CPO正好解决了上述问题。目前,Nvidia、AMD、英特尔、Ranovus、Broadcom、Marvell等公司都在大力布局CPO技术。
结语
光通信与光计算是相辅相成的,光通信中的光电转换技术会在光计算中得到应用,光计算中要求的低损耗、高密度光子集成也会进一步促进光通信的发展,将来数据计算和传输有可能都在光域完成。
光电融合是未来芯片的发展趋势,硅光子和硅电子芯片取长补短,充分发挥二者优势,促使算力的持续提升。预计未来3年,硅光芯片将支撑大型数据中心的高速信息传输;未来5-10年,以硅光芯片为基础的光计算将逐步取代电子芯片的部分计算场景。









