集成显卡前尘往事:从只能点亮屏幕,到玩3A游戏
PC/服务器领域过去的“集成显卡”,现在的“核心显卡”,一度被戏称为“亮机卡”——因为相比于“独立显卡”,其图形计算性能不值一提,能满足操作系统图形界面的最基础性能要求就不错的,不要说用来玩游戏、做设计。
不过这两年,处理器厂商的核显竞争似乎内卷了起来。Intel的11代酷睿处理器96EU规模的Xe核显,在图形计算跑分上已经赶超笔记本上的入门级GPU(英伟达GeForce MX350);今年AMD这边的Ryzen 6000系列处理器RDNA 2核显(Radeon 680M)性能都超越10年前的GPU卡皇(Radeon HD 7970)了...实在是不得不让人惊叹时代发展之迅猛。

现在的AMD Ryzen 6000系列移动处理器,靠核显跑1080p高画质的《艾尔登法环》,游戏帧率就能上40fps;更不用说应付常规的网游和竞技类游戏。Intel很快要发布的13、14代酷睿预计还会在核显规格上持续内卷,让核显性能再上台阶。
抛开苹果M1 Max/Ultra这种芯片不谈,虽说集显和真正的高性能独显比起来,性能仍然是不值一提的;但以前的“亮机卡”现在都能玩3A游戏了。这核显的发展究竟经历了怎样的过程?作为EE历史课系列,本文尝试回顾过去这几十年,“集成显卡”的发展史。
“集成显卡”的定义问题
按照我们分析历史事物的常规,首先还是要来定义一下究竟什么是“集显”。中文称其为“集成显卡”,实际英文是Integrated Graphics Processor(或iGPU)。在中文语境里,“显卡”一词似乎已经转义为指代GPU,而不再特指板卡形态的硬件。“集成显卡”原本就不是板卡,而是一颗芯片、一片die或者die上的一部分。本文也沿用这种约定俗成的说法。
而“核显”(核心显卡)可以认为是集显的某种进化形态。更早以前的集显虽然说是“集成”的,但它主要是和北桥芯片集成在一起,和CPU离得还是比较远的;而从2010年开始,Intel将GPU和CPU放到了同一颗芯片上,“核显”这个说法就出现了——也就进化成了真正的“集显”。
这是我们探讨集显进化史的基础。实际上,和CPU放在一起的GPU,无论如何都没有了板卡形态,但中文仍然亲切地称呼它为“核心显卡”。Intel官方也沿用了“集成显卡”“核心显卡”这样的说法,我们也就不再做严格区分了。
前“集显”时代
早在1995年(或之前)就已经有集成的图形控制器问世了。Weitek、矽统(SiS)都有这样的芯片产品。比如说矽统的SiS6204,应当就是第一颗针对Intel处理器、应用于PC的集成图形控制器,与北桥芯片是集成到了一起的;而再略早一点的Weitek则面向SPARC平台推出过对应的产品。
可见自古以来,“集显”最早就在于表达,从事图形计算工作的处理单元与其他处理器放在一起;虽然这里的“显”究竟是graphcis controller还是graphics processor还是可以做区分的。当时GPU这个词都还没有出现,且图形单元的构成也还远不像现在这么复杂。
矽统当年发布的集显包含最高分辨率支持到1280x1024 1680万色的集成VGA,以及带视频解码器接口(Philips SAA 7110)的64位BitBLT引擎,支持色彩空间转换、视频缩放、色键视频覆盖等。最初似乎只有矽统、ALi(扬智科技)两家公司获得了面向Intel奔腾处理器生产芯片组的第三方授权。
1999年SGI(硅图,Silicon Graphics Inc)发布两款工作站产品,采用Intel奔腾处理器,以及自己设计的Cobalt集显——据说这颗芯片的成本比一般的CPU还好高。SGI首款集显的价值在于采用UMA统一内存架构,即图形处理器和CPU共享系统内存,虽然当时的UMA和现在我们常说的UMA(如苹果M1芯片的UMA)差异还是比较大的。
同年,Intel自己发布了代号为Whitney的i810芯片组——其中就包含Intel自己发布的首颗集显——位于北桥芯片内部(代号为i752),集显时代大概应该是从这个时候正式拉开序幕的。
Intel在独显市场的失利
从PC GPU的市场份额来看,现在市占率最高的并不是英伟达,而是Intel——从Jon Peddie Research今年一季度的数据来看,Intel在PC GPU市场的份额达到了60%,相对的英伟达是21%,AMD为19%(这份数据也需要考虑到AMD的集显)。这当然主要归功于Intel这么多年都在推自家的集显或核显产品。毕竟大部分PC用户并不需要高算力的独立GPU。
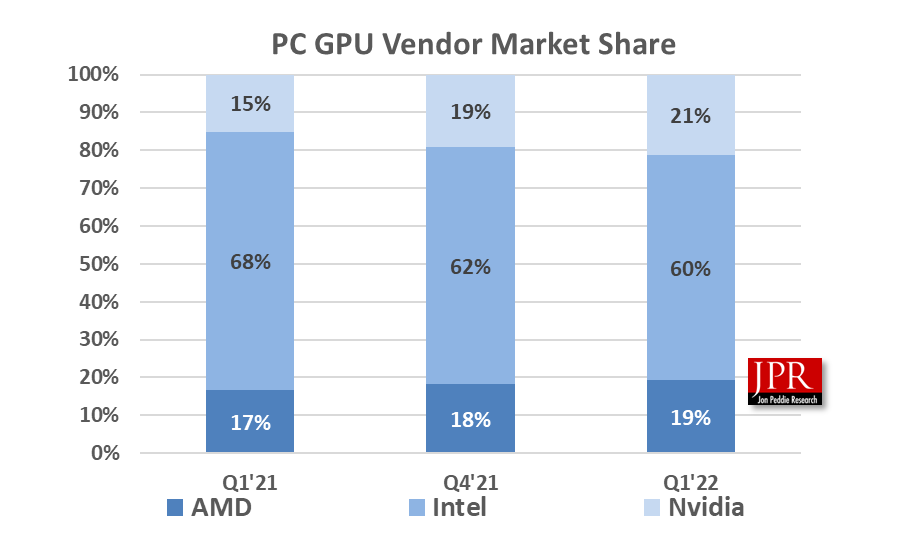
来源:Jon Peddie Research
现在我们知道,Intel前不久,打算和英伟达、AMD一较高下。不过这可不是Intel进驻GPU或独立显卡的开端。这家公司在其发展历程中,始终与图形计算处理器、加速卡有着千丝万缕的联系。
早在上世纪80年代,Intel看到NEC、日立等公司的独立图形控制器产品生意挺红火,也打算进驻这一市场。1986年Intel发布82786图形协处理器(并且在此之前就和NEC有过图形技术授权合作)。后来持续有多家公司(AIB显卡厂商)基于这颗芯片推出了板卡产品。不过其实Intel和同期的竞争对手比起来是没有技术优势的。
1998年,相对更知名的i740独显问世——这是一颗主频220MHz、2-8MB VRAM显存的独立显卡,支持DirectX 5.0和OpenGL 1.1。Intel其实很清楚其显存容量相比同期竞争对手过小的问题。Intel的想法是充分利用彼时AGP接口的一大特性:板卡可以去用主内存。i740上的小显存只用作frame buffer帧缓冲,而所有的图形纹理都放在系统主内存里。这样一来i740的成本也就比较低了。
不过这么做的弊端也很明显:内存读取速度缓慢,成为性能的巨大瓶颈;而且还和CPU争抢带宽资源。加上Intel糟糕的驱动,i740算是相当失败的产品。即便Intel后续要求主板厂商捆绑销售,也未能挽回其颓势。
i740产品开发同期,还是有些行业八卦可以聊的。1995年,大名鼎鼎的洛克希德马丁(Lockheed Martin)开设了一个新的部门叫Real3D(据说是因为模拟器图形技术比较花钱,洛克希德马丁决定回点血)。Real3D的首个客户就是世嘉。凭借世嘉在街机市场的巨大成功,Real3D的图形加速器产品出货量相当之大。

同期Intel正准备在这一领域一展拳脚。所以协同当时的另一家公司(Chips and Technologies),一起和Real3D展开合作。这就是后来i740诞生的背景。与此同时Intel也购入了Real3D的部分股权。
如前所述,i740失败了。Intel就把Real3D从洛克希德马丁那里买了下来。之后有一段Real3D遗产的八卦故事,包括ATI抢了一部分人、3dfx和Real3D打专利官司、Intel把Real3D的全部IP都卖给了3dfx(后来自然成为了英伟达的一部分),后续又有ATI参与的专利官司等...
然后Intel就退出了独立显卡市场,毕竟i740销量不怎么样,还闹出一大堆的破事。在此之后,Intel主攻方向就变成了集显...若说Intel在独显市场的尝试,后续还有个Larrabee项目——但产品以胎死腹中告终,这些将来我们可以在单独探讨Intel的GPU历史话题中再做分享。
据说i740的失败,以及Real3D的一系列变故,给Intel造成了不小的打击。当时Intel内部甚至传出不会再涉足独显的传言。不过2007年Larrabee项目、2012年的Xeon Phi,以及现如今的Arc独显,都说明Intel和GPU藕断丝连的关系始终在持续。跑题了,我们继续回到集显这个话题;起码在i740以后,Intel的图形计算主战场都转向了集显与核显。只不过这些应该也是集显得以发展的必要条件。
Intel集显上半场发展简史
1999年的i810芯片组,及其中的i752集显,可以说是i740的迭代——可见技术仍然是有延续性的。受限于篇幅,我们不打算细致介绍Intel自1999年发布首颗集显以后都经过了怎样的迭代路径。不过其中仍有一些标志性事件值得单独拿出来谈一谈。
2001年有几个重要事件。第一是矽统针对其集显产品加入了T&L(Transform, Clipping, and Lighting)支持——这是图形计算领域的一项重要特性,包括3D场景的2D化、只保留场景中可见的部分、基于光照信息转化场景中各个面的色彩信息。从这个时候开始,“集成显卡”称谓才真正变得名正言顺;至少它在功能上完整了不少。
第二件事情是英伟达针对AMD处理器平台,推出了nForce 220集显,当然也是集成到主板芯片组里面的。不久后英伟达就和在技术转向后的Intel发生矛盾,两家公司打起了旷日持久的官司。英伟达后来于2012年退出了集显市场,致彼时该市场只剩下AMD、Intel和威盛。
第三件事则是2001年,Intel建立Extreme Graphics集显家族——这个系列的集显名称沿用到了2004年。初代Extreme Graphics集成在i830芯片组内部,配套的处理器是奔腾III-M。二代Extreme Graphics出现了笔记本平台版,配套奔腾M处理器。这时期的集显基本就是亮机卡,顶多可以玩一些老游戏。其实即便是2004年的GMA 900集显(i915芯片组),内部都还没有顶点着色器(vertex shader),需要依靠CPU来做这部分工作;且主内存带宽低,性能自然不需要太多指望。
从2002年开始,ATI也开始造集显,初代IGP 320(ATI A3)。如果以Intel的集显产品型号为依据,则PC市场的集显后续经历了GMA系列(2004年起)、HD Graphics系列(2010年起)、Iris系列(锐炬,2013年起)。从2010年的HD Graphics开始,集显开始有了“核显”基因。

从集显走向“核显”
早在2006年AMD收购ATI之际,AMD就期望要造所谓“真正的集成GPU”,就是将CPU和GPU放到同一颗芯片,甚至同一片die上(虽然感觉这在移动领域似乎一点也不新鲜)。但以当时的技术来看,AMD和ATI不同的fab厂、不同的设计工具,还有企业文化方面的差异,都让这样的工作充满挑战。
2010年,Intel率先把32nm工艺的CPU die,和45nm工艺的GPU die放到了同一个封装内,CPU和GPU算是正式会师了,这对于降低延迟还是有相当价值的。而且HD Graphics在性能上相比更老的GMA有了不小的提升:23个EU(执行单元),最高900MHz 43.2GFLOPS算力,能够以最高40fps速率解码H.264 1080p视频。
当时Intel已经开始宣称核显要面向休闲和主流PC游戏。似乎对于这颗Westmere架构处理器,很多人才承认它作为iGPU的名副其实;这才算是“integrated”集成。
2011年,Sandy Bridge架构处理器(2代酷睿)问世,随之而来的是第二代HD Graphics核显。而且这次的核显更进了一步,GPU和CPU真正放到了同一颗die上。AMD也是在这一年将APU理念付诸实践。从架构来看,Sandy Bridge处理器上的GPU已经可以和CPU共享L3 cache,我们在此前的,详细介绍过这种架构。
翌年HD Graphics 4000核显伴随Ivy Bridge处理器(3代酷睿)出现的时候,有关Intel核显性能的宣传就全面开启了——当时的不少媒体口径都在说“堪比独显”(感觉和现在上演的是同一个剧本)。不过即便HD 4000性能的确大幅攀升,还能以低画质畅玩《英雄联盟》,但也仅限于此了。即便这在当时也称得上惊艳了,集显的风是从这个时候全面吹起来的。

左边那片小die就是Broadwell的eDRAM
在Xe核显(11代酷睿)之前,近代Intel核显发展相对激进的应该是Broadwell(5代酷睿,2014年)——这一代的Iris Pro锐炬核显基于GT3e架构,片上特别配了128MB的集成eDRAM,核显规格称得上豪华。据说其性能达到了GeForce GT 730的水平——虽然现在听起来不算什么。
值得一提的是,除了API方面的支持迭代、架构变化、规模增大,历代核显也在多媒体支持上有显著提升,包括各类格式的编解码硬件加速——这好像也是当代集显乃至独显内卷的重要组成部分。谁让苹果在这方面那么爱堆料呢。
集显发展史上的其他故事
Intel集显发展史上有一款十分有趣的处理器,代号Kaby Lake-G(8代酷睿,2018年)。这颗芯片的有趣之处在于,同时集成在一个封装内的核显,乃是AMD的Radeon RX Vega M。Intel官方推出了一款搭载AMD核显的Intel处理器,听起来有没有很新奇?
从Kaby Lake-G的外形来看,这代芯片总共有3片die,一片是Intel CPU,一片是AMD GPU,还有一片是4GB HBM2显存,有没有感觉十分高级?这款处理器同时也是Intel比较早期的2.5D高级封装(EMIB)试水产品。从堆料来看,核显性能应该是同一代酷睿核显的2.5倍。

采用AMD核显的Intel处理器Kaby Lake-G
从当年的实测性能来看,Kaby Lake-G图形算力应该和笔记本GeForce GTX 1050差不多,有些测试还超过了1050——现在的大部分核显都还做不到这样的程度,应该算是核显方面彼时最有诚意之作了吧;只是这样的合作在历史上都是不可多得的。
不过集显的发展故事也不仅限于PC设备。随便举几个例子,2004年高通发布MSM6150/6550,其中就有ATI的Imageon“集显”(也就是后来的Adreno GPU);2005年德州仪器的OMAP2420“集显”是来自Imagination的PowerVR GPU,应用于诺基亚N95手机;扩展开去,现在的手机AP SoC都应该说是集成了“显卡”的芯片。
游戏主机、掌机市场的核显就更为常见了:比如任天堂的Switch游戏机基于英伟达的Tegra处理器;2013年,PS4和Xbox One X都采用AMD的APU;那么实际在更多市场都有类似的应用,比如奥迪2008年就把英伟达的Tegra芯片加到了汽车的信息娱乐系统中。
这方面的基因造就了现在苹果Mac所用的M系列芯片都是“核显”,且核显性能按照苹果的说法是媲美GeForce RTX 3090这种民用市场的独显最高配的,当属“集显”或“核显”的究极形态了吧。不过苹果封闭生态的特殊性,以及其盈利方式与传统芯片公司的差异决定了他可以这么做;但其他芯片公司大概率是无法发展这种程度的“核显”的。
AMD的APU理念,与苹果的篇章续写
我们没有以AMD处理器为线索,来写这段集显发展史可能是不对的。AMD收购ATI以后,就在努力打造APU芯片——也就是将CPU和GPU放到同一颗die上,并构建UMA统一内存架构为基础的HSA联盟。这段历史我们,也挺有意思。
2011年AMD推出的首款APU代号Llano,结合了4颗K10 CPU,以及Radeon HD 6000系列GPU,放在同一颗die上。这颗芯片基于GlobalFoundries的32nm工艺。
当时AMD的理念是期望GPU日常能够频繁参与到通用计算工作中来,随时把有高度并行需求的密集型数值计算任务交给GPU去做,让CPU和GPU真正作为同一颗芯片来用。只不过AMD的号召力不足以支撑起这样的生态,除了在游戏主机领域得到普及,PC平台的APU生态是事实上失败的。
不过APU客观上促成了集显性能的内卷。所以AMD都是基于强核显性能这一理念来推APU芯片的,Intel也对应地在每一代做核显性能加强。所以我们才能在这两年看到PC处理器核显性能的持续飞跃。

今年的RDNA 2核显勉强都能玩3A游戏了;12CU规格的Radeon 680M,算力单元规模相当于Radeon RX 6400(虽然存储系统还是差远了)。虽说和历史上出现过的一些核显怪胎不同,但还是让英伟达的入门级独显首次感到了白色恐怖。
另外比较有趣的是,AMD虽然未能在APU with HSA的理念上真正有所斩获,但苹果续写了这个故事。苹果在M1芯片发布之际就在宣传UMA统一内存架构——这不是什么新东西;只不过以苹果的半封闭生态,及苹果的生态号召力,苹果GPU参与更多通用计算工作加速显得更为寻常。
而且苹果芯片发家于手机AP SoC,基因里有着天然的“核显”属性,GPU就是和CPU放在同一片SoC芯片上的。这么算来,M1 Max/Ultra也都属于“核显”范畴,以其规模堆砌程度,应当还没有核心芯片可与之在绝对性能上相提并论。或许苹果的M1 Ultra正是AMD当年APU理念缔造之初的终极目标,包括统一内存架构,以及接近高端独显显存带宽的内存带宽(800GB/s)水平。虽说苹果的GPU究竟能干嘛,那又是另一个话题了。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。