Linux内核代码中常用的数据结构
来源: 单片机与嵌入式
微信公众号资讯
链表
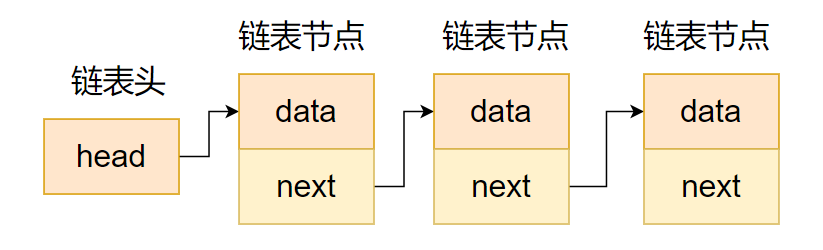
struct list {int data; /*有效数据*/struct list *next; /*指向下一个元素的指针*/};
struct list {int data; /*有效数据*/struct list *next; /*指向下一个元素的指针*/struct list *prev; /*指向上一个元素的指针*/};
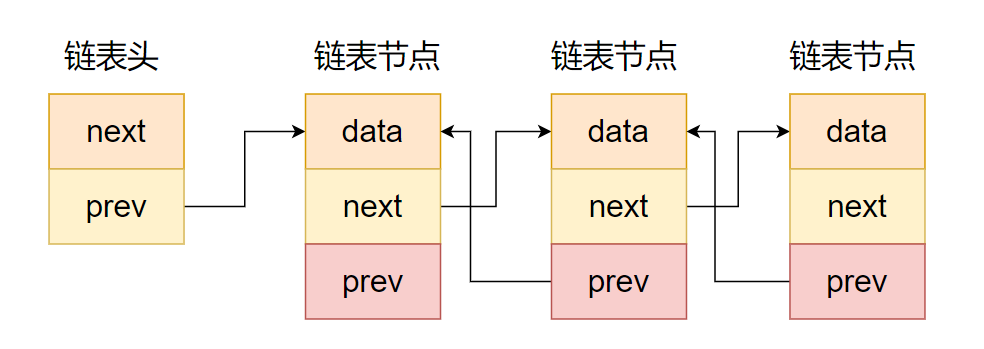
<include/linux/types.h>struct list_head {struct list_head *next, *prev;};
<include/linux/mm_types.h>struct page {...struct list_head lru;...}
<include/linux/list.h>/*静态初始化*/#define LIST_HEAD_INIT(name) { &(name), &(name) }#define LIST_HEAD(name)struct list_head name = LIST_HEAD_INIT(name)/*动态初始化*/static inline void INIT_LIST_HEAD(struct list_head *list){list->next = list;list->prev = list;}
<include/linux/list.h>void list_add(struct list_head *new, struct list_head *head)list_add_tail(struct list_head *new, struct list_head *head)
#define list_for_each(pos, head)for (pos = (head)->next; pos != (head); pos = pos->next)
#define list_entry(ptr, type, member)container_of(ptr, type, member)//container_of()宏的定义在kernel.h头文件中。#define container_of(ptr, type, member) ({const typeof( ((type *)0)->member ) *__mptr = (ptr);(type *)( (char *)__mptr - offsetof(type,member) );})#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
<drivers/block/osdblk.c>static ssize_t class_osdblk_list(struct class *c,struct class_attribute *attr,char *data){int n = 0;struct list_head *tmp;list_for_each(tmp, &osdblkdev_list) {struct osdblk_device *osdev;osdev = list_entry(tmp, struct osdblk_device, node);n += sprintf(data+n, "%d %d %llu %llu %s ",osdev->id,osdev->major,osdev->obj.partition,osdev->obj.id,osdev->osd_path);}return n;}
红黑树
-
每个节点或红或黑。 -
每个叶节点是黑色的。 -
如果结点都是红色,那么两个子结点都是黑色。 -
从一个内部结点到叶结点的简单路径上,对所有叶节点来说,黑色结点的数目都是相同的。
#include <linux/init.h>#include <linux/list.h>#include <linux/module.h>#include <linux/kernel.h>#include <linux/slab.h>#include <linux/mm.h>#include <linux/rbtree.h>MODULE_AUTHOR("figo.zhang");MODULE_DESCRIPTION(" ");MODULE_LICENSE("GPL");struct mytype {struct rb_node node;int key;};/*红黑树根节点*/struct rb_root mytree = RB_ROOT;/*根据key来查找节点*/struct mytype *my_search(struct rb_root *root, int new){struct rb_node *node = root->rb_node;while (node) {struct mytype *data = container_of(node, struct mytype, node);if (data->key > new)node = node->rb_left;else if (data->key < new)node = node->rb_right;elsereturn data;}return NULL;}/*插入一个元素到红黑树中*/int my_insert(struct rb_root *root, struct mytype *data){struct rb_node **new = &(root->rb_node), *parent=NULL;/* 寻找可以添加新节点的地方 */while (*new) {struct mytype *this = container_of(*new, struct mytype, node);parent = *new;if (this->key > data->key)new = &((*new)->rb_left);else if (this->key < data->key) {new = &((*new)->rb_right);} elsereturn -1;}/* 添加一个新节点 */rb_link_node(&data->node, parent, new);rb_insert_color(&data->node, root);return 0;}static int __init my_init(void){int i;struct mytype *data;struct rb_node *node;/*插入元素*/for (i =0; i < 20; i+=2) {data = kmalloc(sizeof(struct mytype), GFP_KERNEL);data->key = i;my_insert(&mytree, data);}/*遍历红黑树,打印所有节点的key值*/for (node = rb_first(&mytree); node; node = rb_next(node))printk("key=%d ", rb_entry(node, struct mytype, node)->key);return 0;}static void __exit my_exit(void){struct mytype *data;struct rb_node *node;for (node = rb_first(&mytree); node; node = rb_next(node)) {data = rb_entry(node, struct mytype, node);if (data) {rb_erase(&data->node, &mytree);kfree(data);}}}module_init(my_init);module_exit(my_exit);
无锁环形缓冲区
<include/linux/kfifo.h>int kfifo_alloc(fifo, size, gfp_mask)
#define DEFINE_KFIFO(fifo, type, size)#define INIT_KFIFO(fifo)
int kfifo_in(fifo, buf, n)
#define kfifo_out(fifo, buf, n)
#define kfifo_size(fifo)#define kfifo_len(fifo)#define kfifo_is_empty(fifo)#define kfifo_is_full(fifo)
#define kfifo_from_user(fifo, from, len, copied)#define kfifo_to_user(fifo, to, len, copied)
文章来源于: 单片机与嵌入式原文链接
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。