2022年11月,ChatGPT的出现永久地改变了人类的生活。大模型随之兴起,各行各业都在思考如何利用大模型做产品,如何利用大模型做能效提升、产品体验力提升。
智能驾驶在其中如何顺势而为?如何乘风破浪?

在吉利汽车研究院技术规划中心主任陈勇看来,大模型领域的门槛会逐步变得更高。今天看到的百模也好,千模也好,三年之后会是怎么样,现在还无法判断,但其中能够真正坚持下去的,就是找到高价值用户场景的企业,因为用户场景决定技术价值。
在智能驾驶领域,大模型能够解决问题,创造价值。例如,用大模型合成数据,挖掘数据价值等等,拥有极大的想象力。
以下是陈勇的演讲实录。
很高兴跟大家分享大模型时代吉利的应用探索。刚才两位老总介绍了智能驾驶在安全、数据领域应该如何做/如何把智能驾驶体验做得更好。接下来分享一下吉利在智能驾驶方面的思考。
对于智能驾驶来讲,用户也好,产品也好,市场比较关心的第一个应该是安全,因为在真正的智能驾驶当中,包括辅助驾驶当中,安全是每个人、每位用户,包括每个主机厂/合作伙伴最关心的事情。

如何能够保证安全?智能驾驶核心要解决很多长尾问题,智能驾驶发展得越快,发展得越好,真正最后那一点点长尾效应可能花的时间/代价/精力越大、越高,因为安全是0和1的事情。如何把这种corner case长尾效应做好,这是非常难的,也要花大量精力思考去做。
目前大部分智能驾驶感知还停留在标注阶段,这意味着还是缺少一种认知能力,更多的是我们见过多少,我们标注了多少目标物、交通参与者,但是它是否真正具备认知能力?刚才提到,如果在高速公路上一块石头突然滑下来,它是否具备这样的认知?能否通过泛化做这样的事情,如果没有标注过,这样的事情能否做?
另外,安全和安全感是两回事。智能驾驶如何做到安全?有安全,就有安全感,这不是一个等号。如何给用户营造一个安全感,安全是一个前提,安全感是一种体验。
其次,如何把智能驾驶体验做好,毕竟是一个智能化的产品和体验,但是智能化的体验不是有没有,现在很多人在思考我有各种功能,不管是高速NOA、城市NOA,APA、RPA等等,功能有没有,不等于体验好不好。
如果一个功能体验不好,不如没有,自动驾驶体验过程当中,高速NOA也好,RPA也好,一旦有一次让你感觉到意外的事情,相信你长时间都不会用,甚至可能因为这样的事情你就不会去用了。在复杂道路上,如何把接管率做得更低,其次智能驾驶的体验大部分是不连贯的。
另外是关于成本,如何把智能驾驶的成本降下来。现在我们为了满足很多功能场景需求,堆砌了很多传感器、硬件技术、冗余设计等等,让智能驾驶成本相对来说比较高。如何让它能够回归到商业本质?如何把成本做得更低,或者如何把这个体验比做得更好,这是智能驾驶应该关心的问题。
前几年智能驾驶由粗犷的硬件驱动体验逐步转向数据算法驱动体验转变。原来有1V1R、1V3R、7V+毫米波雷达,现在有10V、11V+毫米波雷达+激光雷达,加一个不够,加两个,两个不够加三个,目前大部分都是这种情况,这种粗犷式的硬件堆砌来满足各种功能体验或者安全的要求。

如果让这个事情回归到商业本身或者用户需求本质,相信用户要的不是传感器,用户要的是智能化体验而已,如何通过数据和算法来驱动体验提升,而不是靠硬件配置的堆砌。
做加法我觉得容易,但做减法很难。如何通过用户体验驱动价值创造,让智能化设计回归理性?这是做智能驾驶的每个人要去思考的事情。这里面应该用技术驱动创新,使体验提升,提升性价比,包括各种集成,不管是行泊一体也好,舱驾一体也好等等“去硬件化”。另外通过各种技术,通过大模型也好、数据闭环也好,能够“轻地图、去硬件化”,这是值得思考的。
大模型能来做什么?
在大模型时代当中,传统AI算法发展好几十年了,大模型应该是这几年,从2022年11月ChatGPT出来以后,大家的关注越来越高了。
各行各业都在思考如何利用大模型做产品,如何利用大模型做能效提升、产品体验力提升,在大模型时代,在智能驾驶领域,我们如何顺势而为?如何乘风破浪?目前大模型应该是百模大战,千模乱舞。
回顾五年之前的新能源市场,五年之前也有很多新势力,如同现在的市场这么疯狂,可能都差不多。那时候应该有400多家新能源企业,到现在还有多少家?可能那个百就没有了,就剩后面的零头了,那个零头还能坚持多久?大模型也是一样,大模型跟新能源相比,门槛可能比新能源还要高。
因为大模型有核心几个要素:(1)需要大量GPU算力。随着参数量的增加,GPU算力会越来越多。(2)需要大量数据,随着参数量的增加,应用场景的扩大,需要大量的数据,包括高质量的数据。(3)人工智能大模型领域需要大量的人才。
这个领域的门槛会逐步变得更高。今天看到的百模也好,千模也好,三年之后会是怎么样?这里面谁能真正坚持下去,把场景找到,才能够胜出。用户场景决定技术价值。
如果一个技术没有找到合适的用户场景,这个技术我觉得不是没有价值,可能有学术价值,但不一定有商业价值,我们应该找到合适的应用场景,才能够决定这个技术的价值是多少。
如果当下的大模型用来做智能驾驶,我觉得它应该值智能驾驶的价钱,如果大模型用来蒸包子,一个包子五分钟,十个包子几分钟,如果大模型用来做鸡兔同笼这样的事情,大模型也就值这个价。技术的价值谁决定的?由用户场景决定的,而不是技术本身决定的。
大模型用来干什么?显然在智能驾驶领域我们需要大模型,但并不是所有领域都需要大模型。任何一个产品都有它的市场价值和定位,今天有了高铁飞机,不意味着我们不骑自行车了,并不是大模型来了,大模型可以应用所有场景,传统东西不需要了,不见得。
智能驾驶领域大模型能做什么事情?大模型是来解决问题的,如果没有问题就不需要新技术,或者它是来创造价值的,大模型能够解决智能驾驶领域什么问题?或者能够创造什么价值?
首先是数据。数据量的要求或者数据质量的要求非常高,大模型能不能解决数据量不足的问题?深层次的大模型本身具有强大的泛化能力,数据采集能否不依靠实际道路采集?能否利用大模型做生成数据。
第二是数据价值创造。数据采集、数据标注成本非常高,从原来不管做L2、L2+也好,包括城市NOA,至少是几百万帧,甚至是上千万帧,上亿,现在是BEV+Transformer这样的数据做这样的事情。一帧数据的采集和标注的成本几块钱到几十块钱不等,大部分实际道路的采集很多应该还不能共用,不同车型都有差异,能否用大模型做这样的事情?
第三我们有数据,但数据价值并没有真正挖掘出来。我们可能采集了很多数据,但数据的价值挖掘取决于每个人的认知。

我的认知能力决定了数据价值挖掘能力,如果这张图片给我,你只标了三个障碍,三个交通参与者,这就是你的认知,决定了这个图片就值这个价值,大模型能否帮我们把数据,把每一帧的图片语义深刻理解出来,挖掘更多的价值,能否做这个事情?我觉得可以做这样的事情。
第四如果真正能够做到端到端的大模型应用,那是非常好的事情,学术上现在大家都在研究这样的事情,但是短期来讲量产还是有一点距离的,因为它要解决很多问题。
智能驾驶如何做,把大模型轻量化做本地化问题,这个必须要解决,大模型生成式有很多不确定性的问题,如何把可控性做得更好,这些都是我们需要思考和做的事情。

大模型如何提升数据?
这些领域当中我们做了一些思考和探索,今天跟大家做分享。
如何把数据的数量和质量做提升?因为在智能驾驶领域或者在大模型与人工智能领域,其中一个应该叫“数据价值战”,如何利用数据驱动模型的迭代和体验的提升,这是未来在人工智能领域、在智能驾驶领域都应该思考和做的事情。

核心关注两件事情:数据量和数据质量。如果数据质量不好,数据量再大都没有用。如果天天思考1+1等于几的问题,我们不会进步的,数据量和数据质量非常重要。
第二,数据量和数据质量如何做提升?如何通过实际道路做采集?或者通过虚拟数据的生成和实际道路的融合,生成一些高质量合成数据。数据是模型训练的关键,直接影响了模型性能,数据量和数据质量都应该抓。我们会给我们模型什么样的数据和数据质量,决定了这个模型能力上线的天花板。
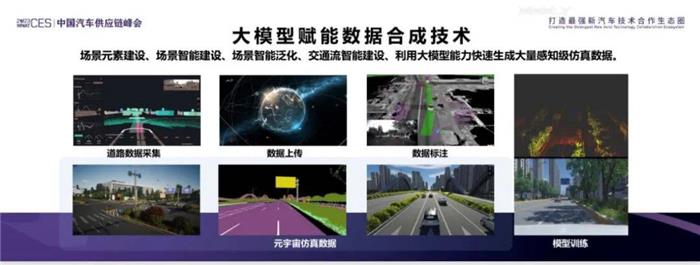
在这个过程中,首先要思考的是如何利用大模型赋能做数据的合成技术。现在大部分数据都应该是由实际道路采集的,实际道路采集的成本相对比较高,而且很多corner case采集不到,如果昆山下雪天,高速公路有交通事故的场景,中间还有大货车,相信这样的数据很难找,昆山下雪的场景都非常难找,更不要说下暴雪,如何把这样的场景通过虚拟环境做生成?
我们构建了一个虚拟环境,生成大量的数据做这个事情。另外我们通过真实数据训练虚拟环境,如何让虚拟环境的数据和真实数据变得更像,从而满足智能驾驶仿真需求,我们在做这个事情。
对于模型训练来讲,它不关心这个数据是张三还是李四给的,只关心这个数据质量是否好。这个过程当中如何利用大模型把合成数据的质量做提升?
首先我们会做很多虚拟数据的生成,过程当中我们会对比虚拟数据的生成和真实数据的风格是否一致,如果虚拟数据生成质量远远好于实际场景下的真实数据质量。一方面我们的模型,在温室下训练这个模型,有可能到真实环境当中就不适应了,鲁棒性能可能就不高,可靠性也不好。
我们需要训练大量loss的去训练我们目前真实的数据和虚拟环境数据之间的差异,同理让虚拟环境生成的数据和真实环境的数据一致性能够变得更好、变得更真实。其次如何让虚拟数据生成的语义能够更多地保持住,去做思考,我们通过大量数据训练,训练大模型数据的合成技术。
我们通过真实数据训练虚拟数据,最后达成合成数据。合成数据结合真实数据场景的风格,但又保持了虚拟数据的语义,这样大大提升了合成数据的质量。
我们目前搭的虚拟环境,所有的道路建设、场景建设、天气模拟、交通流的模拟都可以用AI建模做,这样可以大大降低实际道路数据采集和标注成本,包括道路上的做旧也好,减速带也好,锥桶也好,都可以模拟出这个事情。
其次用大模型可以解决数据价值挖掘的事情。前段时间一个整车厂看到广告牌上有一个人触发了AEB。这种数据虽然有,但是没有做过训练,导致这样的事情发生,有大量的数据,但是数据没有挖掘,没有充分地把数据价值呈现出来。
大模型具备多模态的能力,能够识别大量、海量数据语义的理解,能够把数据做标签化处理,可以快速检索,从而形成模型训练的数据集。
另外我们也做了大量的自动化标注和语义分割,结合虚拟数据和开源数据,包括道路数据、道路训练大模型语义分割的数据。

为了验证虚拟数据的能力和大模型的能力,我们也在ACDC的公开数据榜上针对特殊场景,给出各类验证,整体来讲我们的测试结果相对来说还是比较好的。
它验证了一件事情,大模型具备这样的语义分割和自动化标准的,另外虚拟数据质量已经达到了真实场景的需求,能够满足这样的场景。所以在公开数据集上才能够得到全球第一的成绩。
我们做了大量的语义分割,其实做这样的事情,大模型做比人做,相对来说还是有好处的,一致性比较高一些,整体的效率,包括精度也相对来说比较好。
最后给大家分享一下,在智能驾驶也好,人工智能大模型领域,目前大模型的确挺火的,但是当下不能高估大模型的能力,不能觉得大模型什么都行,什么都能干,但是更不能低估大模型未来的发展,因为它的潜力是无限的,谢谢大家!