在开源电子中看到一篇文章讲的是栈增长和大端/小端问题。学C语言的时候,我们知道堆栈的区别:
(1)栈区(stack):由编译器自动分配和释放,存放函数的参数值、局部变量的值等,其操作方式类似于数据结构中的栈。
(2)堆区(heap):一般由程序员分配和释放,若程序员不释放,程序结束时可能由操作系统回收。分配方式类似于数据结构中的链表。
(3)全局区(静态区)(static):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由系统自动释放。
(4)文字常量区:常量字符串就是存放在这里的。
(5)程序代码区:存放函数体的二进制代码。
下面的帖子:主要意思是要证明stm32是小端模式,堆从RAM的起始地址处(0x2000 0000)分配内存给全局变量和静态变量,并且堆是向上增长,栈是向下增长。
1,首先来看:栈(STACK)的问题。
函数的局部变量,都是存放在“栈”里面,栈的英文是:STACK.STACK的大小,我们可以在stm32的启动文件里面设置,以战舰stm32开发板为例,在startup_stm32f10x_hd.s里面,开头就有:
Stack_Size EQU 0x00000800
表示栈大小是0X800,也就是2048字节。这样,CPU处理任务的时候,函数局部变量做多可占用的大小就是:2048字节,注意:是所有在处理的函数,包括函数嵌套,递归,等等,都是从这个“栈”里面,来分配的。
所以,如果一个函数的局部变量过多,比如在函数里面定义一个u8 buf[512],这一下就占了1/4的栈大小了,再在其他函数里面来搞两下,程序崩溃是很容易的事情,这时候,一般你会进入到hardfault.。。。
这是初学者非常容易犯的一个错误。切记不要在函数里面放N多局部变量,尤其有大数组的时候!
对于栈区,一般栈顶,也就是MSP,在程序刚运行的时候,指向程序所占用内存的最高地址。比如附件里面的这个程序序,内存占用如下图:
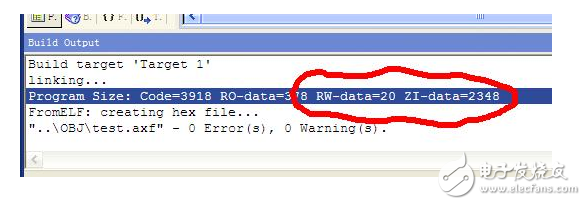
图中,我们可以看到,程序总共占用内存:20+2348字节=2368=0X940那么程序刚开始运行的时候:MSP=0X2000 0000+0X940=0X2000 0940.事实上,也是如此,如图:
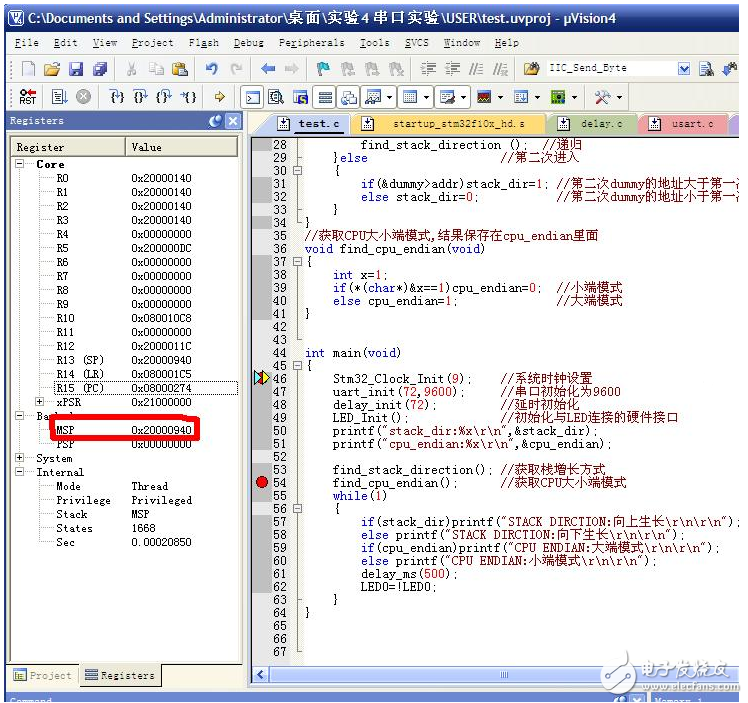
图中,MSP就是:0X2000 0940.程序运行后,MSP就是从这个地址开始,往下给函数的局部变量分配地址。
再说说栈的增长方向,我们可以用如下代码测试:
[objc] view plain copy//保存栈增长方向
//0,向下增长;1,向上增长。
static u8 stack_dir;
//查找栈增长方向,结果保存在stack_dir里面。
void find_stack_direction(void)
{
static u8 *addr=NULL; //用于存放第一个dummy的地址。
u8 dummy; //用于获取栈地址
if(addr==NULL) //第一次进入
{
addr=&dummy; //保存dummy的地址
find_stack_direction (); //递归
}else //第二次进入
{
if(&dummy》addr)stack_dir=1; //第二次dummy的地址大于第一次dummy,那么说明栈增长方向是向上的。
else stack_dir=0; //第二次dummy的地址小于第一次dummy,那么说明栈增长方向是向下的。
}
}
这个代码不是我写的,网上抄来的,思路很巧妙,利用递归,判断两次分配给dummy的地址,来比较栈是向下生长,还是向上生长。
如果你在STM32测试这个函数,你会发现,STM32的栈,是向下生长的。事实上,一般CPU的栈增长方向,都是向下的。
2,再来说说,堆(HEAP)的问题。
全局变量,静态变量,以及内存管理所用的内存,都是属于“堆”区,英文名:“HEAP”与栈区不同,堆区,则从内存区域的起始地址,开始分配给各个全局变量和静态变量。
堆的生长方向,都是向上的。在程序里面,所有的内存分为:堆+栈。 只是他们各自的起始地址和增长方向不同,他们没有一个固定的界限,所以一旦堆栈冲突,系统就到了崩溃的时候了。
同样,我们用附件里面的例程测试:
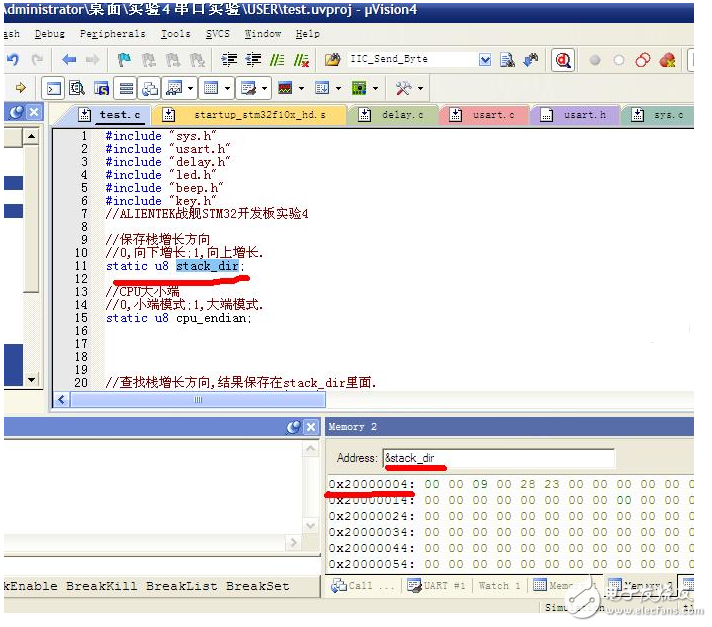
stack_dir的地址是0X20000004,也就是STM32的内存起始端的地址。
这里本来应该是从0X2000 0000开始分配的,但是,我仿真发现0X2000 0000总是存放:0X2000 0398,这个值,貌似是MSP,但是又不变化,还请高手帮忙解释下。
其他的,全局变量,则依次递增,地址肯定大于0X20000004,比如cpu_endian的地址就是0X20000005.
这就是STM32内部堆的分配规则。
3,再说说,大小端的问题。
大端模式:低位字节存在高地址上,高位字节存在低地址上
小端模式:高位字节存在高地址上,低位字节存在低地址上
STM32属于小端模式,简单的说,比如u32 temp=0X12345678;
假设temp地址在0X2000 0010.
那么在内存里面,存放就变成了:
地址 | HEX |
0X2000 0010 | 78 56 43 12 |
CPU到底是大端还是小端,可以通过如下代码测试:
//CPU大小端
//0,小端模式;1,大端模式。
static u8 cpu_endian;
//获取CPU大小端模式,结果保存在cpu_endian里面
void find_cpu_endian(void)
{
int x=1;
if(*(char*)&x==1)cpu_endian=0; //小端模式
else cpu_endian=1; //大端模式
}
以上测试,在STM32上,你会得到cpu_endian=0,也就是小端模式。
4,最后说说,STM32内存的问题。
还是以附件工程为例,在前面第一个图,程序总共占用内存:20+2348字节,这么多内存,到底是怎么得来的呢?
我们可以双击Project侧边栏的:Targt1,会弹出test.map,在这个里面,我们就可以清楚的知道这些内存到底是怎么来的了。在这个test.map最后,Image 部分有:
==============================================================================
Image component sizes
Code (inc. data) RO Data RW Data ZI Data Debug Object Name
172 10 0 4 0 995 delay.o//delay.c里面,fac_us和fac_ms,共占用4字节
112 12 0 0 0 427 led.o
72 26 304 0 2048 828 startup_stm32f10x_hd.o //启动文件,里面定义了Stack_Size为0X800,所以这里是2048.
712 52 0 0 0 2715 sys.o
348 154 0 6 0 208720 test.o//test.c里面,stack_dir和cpu_endian 以及*addr ,占用6字节。
384 24 0 8 200 3050 usart.o//usart.c定义了一个串口接收数组buffer,占用200字节。
----------------------------------------------------------------------
1800 278 336 20 2248 216735 Object Totals //总共2248+20字节
0 0 32 0 0 0 (incl. Generated)
0 0 0 2 0 0 (incl. Padding)//2字节用于对其
----------------------------------------------------------------------
Code (inc. data) RO Data RW Data ZI Data Debug Library Member Name
8 0 0 0 0 68 __main.o
104 0 0 0 0 84 __printf.o
52 8 0 0 0 0 __scatter.o
26 0 0 0 0 0 __scatter_copy.o
28 0 0 0 0 0 __scatter_zi.o
48 6 0 0 0 96 _printf_char_common.o
36 4 0 0 0 80 _printf_char_file.o
92 4 40 0 0 88 _printf_hex_int.o
184 0 0 0 0 88 _printf_intcommon.o
0 0 0 0 0 0 _printf_percent.o
4 0 0 0 0 0 _printf_percent_end.o
6 0 0 0 0 0 _printf_x.o
12 0 0 0 0 72 exit.o
8 0 0 0 0 68 ferror.o
6 0 0 0 0 152 heapauxi.o
2 0 0 0 0 0 libinit.o
2 0 0 0 0 0 libinit2.o
2 0 0 0 0 0 libshutdown.o
2 0 0 0 0 0 libshutdown2.o
8 4 0 0 96 68 libspace.o //库文件(printf使用),占用了96字节
24 4 0 0 0 84 noretval__2printf.o
0 0 0 0 0 0 rtentry.o
12 0 0 0 0 0 rtentry2.o
6 0 0 0 0 0 rtentry4.o
2 0 0 0 0 0 rtexit.o
10 0 0 0 0 0 rtexit2.o
74 0 0 0 0 80 sys_stackheap_outer.o
2 0 0 0 0 68 use_no_semi.o
2 0 0 0 0 68 use_no_semi_2.o
450 8 0 0 0 236 faddsub_clz.o
388 76 0 0 0 96 fdiv.o
62 4 0 0 0 84 ffixu.o
38 0 0 0 0 68 fflt_clz.o
258 4 0 0 0 84 fmul.o
140 4 0 0 0 84 fnaninf.o
10 0 0 0 0 68 fretinf.o
0 0 0 0 0 0 usenofp.o
----------------------------------------------------------------------
2118 126 42 0 100 1884 Library Totals //调用的库用了100字节。
10 0 2 0 4 0 (incl. Padding) //用于对其多占用了4个字节
----------------------------------------------------------------------
Code (inc. data) RO Data RW Data ZI Data Debug Library Name
762 30 40 0 96 1164 c_w.l
1346 96 0 0 0 720 fz_ws.l
----------------------------------------------------------------------
2118 126 42 0 100 1884 Library Totals
----------------------------------------------------------------------
==============================================================================
Code (inc. data) RO Data RW Data ZI Data Debug
3918 404 378 20 2348 217111 Grand Totals
3918 404 378 20 2348 217111 ELF Image Totals
3918 404 378 20 0 0 ROM Totals
==============================================================================
Total RO Size (Code + RO Data) 4296 ( 4.20kB)
Total RW Size (RW Data + ZI Data) 2368 ( 2.31kB) //总共占用:2248+20+100=2368.
Total ROM Size (Code + RO Data + RW Data) 4316 ( 4.21kB)
==============================================================================
通过这个文件,我们就可以分析整个内存,是怎么被占用的,具体到每个文件,占用多少。一目了然了。
5,最后,看看整个测试代码:
main.c代码如下,工程见附件。
[objc] view plain copy#include “sys.h”
#include “usart.h”
#include “delay.h”
#include “led.h”
#include “beep.h”
#include “key.h”
//ALIENTEK战舰STM32开发板堆栈增长方向以及CPU大小端测试
//保存栈增长方向
//0,向下增长;1,向上增长。
static u8 stack_dir;
//CPU大小端
//0,小端模式;1,大端模式。
static u8 cpu_endian;
//查找栈增长方向,结果保存在stack_dir里面。
void find_stack_direction(void)
{
static u8 *addr=NULL; //用于存放第一个dummy的地址。
u8 dummy; //用于获取栈地址
if(addr==NULL) //第一次进入
{
addr=&dummy; //保存dummy的地址
find_stack_direction (); //递归
}else //第二次进入
{
if(&dummy》addr)stack_dir=1; //第二次dummy的地址大于第一次dummy,那么说明栈增长方向是向上的。
else stack_dir=0; //第二次dummy的地址小于第一次dummy,那么说明栈增长方向是向下的。
}
}
//获取CPU大小端模式,结果保存在cpu_endian里面
void find_cpu_endian(void)
{
int x=1;
if(*(char*)&x==1)cpu_endian=0; //小端模式
else cpu_endian=1; //大端模式
}
int main(void)
{
Stm32_Clock_Init(9); //系统时钟设置
uart_init(72,9600); //串口初始化为9600
delay_init(72); //延时初始化
LED_Init(); //初始化与LED连接的硬件接口
printf(“stack_dir:%xrn”,&stack_dir);
printf(“cpu_endian:%xrn”,&cpu_endian);
find_stack_direction(); //获取栈增长方式
find_cpu_endian(); //获取CPU大小端模式
while(1)
{
if(stack_dir)printf(“STACK DIRCTION:向上生长rnrn”);
else printf(“STACK DIRCTION:向下生长rnrn”);
if(cpu_endian)printf(“CPU ENDIAN:大端模式rnrn”);
else printf(“CPU ENDIAN:小端模式rnrn”);
delay_ms(500);
LED0=!LED0;
}
}
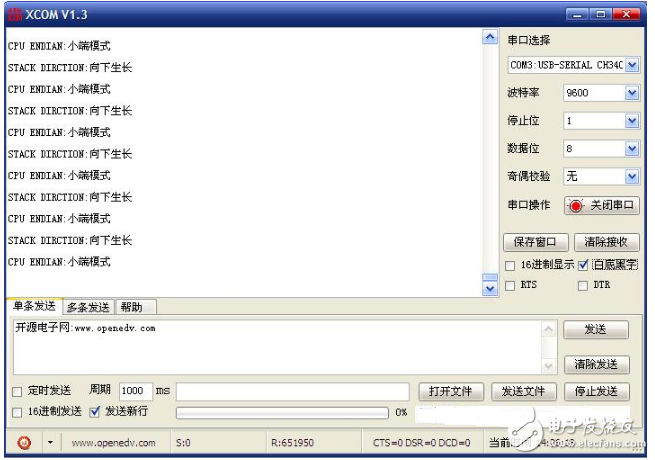
测试结果如图:
有人提出全局变量和静态变量是存储在静态区而不是堆中,并且编写了一个测试代码,(原帖48楼)修改了堆和栈的长度,main函数增加了初始化串口缓冲的操作,和调用了一个无限迭代的函数。堆栈位置在《test.map》line:431-435和line:779-780.F11执行函数Iteration,会看到内存区会不断被Iteration的地址覆盖,直到破坏所有静态变量空间。如果静态变量在栈区,按照栈先进后出的机制,应该不会被破坏。当然,如果链接器是先放栈,再放堆,最后放静态变量,就做不了这个实验了。再三实验,也认可了这种说法,做了如下的修改:
一、内存基本构成
可编程内存在基本上分为这样的几大部分:静态存储区、堆区和栈区。他们的功能不同,对他们使用方式也就不同。
静态存储区:内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。它主要存放静态数据、全局数据和常量。
栈区:在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
堆区:亦称动态内存分配。程序在运行的时候用malloc或new申请任意大小的内存,程序员自己负责在适当的时候用free或delete释放内存。动态内存的生存期可以由我们决定,如果我们不释放内存,程序将在最后才释放掉动态内存。 但是,良好的编程习惯是:如果某动态内存不再使用,需要将其释放掉,否则,我们认为发生了内存泄漏现象。
按照这个说法,我在.s文件里面设置了:
Heap_Size EQU 0x00000000
也就是,没有任何动态内存分配。
这样,内存=静态存储区+栈区了。
不存在堆!!!
因为我没有用malloc来动态分配内存。
因此,前面提到的一切堆区,其实就是静态存储区。
另外,经过测试,确实是这样。
STM32的内存分配,应该分为两种情况。
1,使用了系统的malloc。
2,未使用系统的malloc。
第一种情况(使用malloc):
STM32的内存分配规律:
从0X20000000开始依次为:静态存储区+堆区+栈区
第二种情况(不使用malloc):
STM32的内存分配规律:
从0X20000000开始依次为:静态存储区+栈区
第二种情况不存在堆区。
所以,一般对于我们开发板例程,实际上,没有所谓堆区的概念,而仅仅是:静态存储区+栈区。
无论哪种情况,所有的全局变量,包括静态变量之类的,全部存储在静态存储区。
紧跟静态存储区之后的,是堆区(如没用到malloc,则没有该区),之后是栈区。









