如何实现逼真的音场音频
如今到处都可以听到录制的声音,我们几乎不会刻意想到它们。这些声音从智能手机、智能音箱、电视、收音机、光盘播放机和汽车音响系统倾泻而出,持久而愉快地出现在我们的生活中。2017年,尼尔森市场调研公司的一项调查显示,约90%的美国人经常听音乐,每周平均听32个小时。 在这自由流畅的愉悦背后,庞大的产业推动技术实现长远的目标:最大可能真实地再现声音。从19世纪80年代爱迪生的留声机和喇叭扬声器开始,一代又一代工程师追求这一理想,发明和开发了无数项技术:真空三极管、电动式扬声器、盒式磁带留声机、数十种不同拓扑结构的固态放大器电路、静电扬声器、光盘、立体声音响和环绕立体声音响。在过去的50年里,音频压缩和流媒体等数字技术改变了音乐产业。

然而,即使是现在,经过150年的发展,我们从高端音频系统中听到的声音,也远远不及音乐表演现场听到的声音。在这样的演出现场,我们处于一个自然的声场中,可以很容易地感觉到来自不同位置、不同乐器的声音,即使声场有多种乐器的混合声音交织在一起。人们支付大价钱去现场听音乐是有原因的:现场音乐更令人愉悦、更令人兴奋,并且可以产生更大的情绪感染力。 如今,研究人员、公司和企业家,包括我们公司,终于接近实现真实重建声场进而记录音频的目标了。其中包括苹果和索尼这样的大公司,以及CreaTIve这样的小公司。奈飞最近披露了与Sennheiser的合作,在网络中开始使用一种新系统,即Ambeo 2-Channel SpaTIal Audio,提高《怪奇物语》和《巫师》等电视剧的声音真实感。 目前,至少有6种不同的方法可以制作高逼真的音频(见插图“音频分类”)。我们使用术语“音场”(soundstage)来区别我们的成果与其他音频格式,例如空间音频或沉浸式音频。与普通立体声相比,这些音频可以呈现出更多的空间效果,但它们通常不包含再现真正令人信服的声场所需的详细音源位置提示。 我们相信,音场是音乐录制和再现的未来。但在这场大规模革命发生之前,我们必须克服一个巨大的障碍:如何方便、廉价地转换现有不计其数的录音,无论它们是单声道、立体声还是多通路环绕声(5.1、7.1等)。没有人确切地知道录制了多少首歌曲,但根据Gracenote的娱乐元数据,目前地球上有超过2亿首录制歌曲。考虑到一首歌曲的平均时长约为3分钟,这相当于音乐时长约为1100年。 音乐的数量是庞大的。任何推广一种新音频格式(无论它是多么有前途)的尝试都注定要失败,除非它包含一种技术,使我们能够轻松、方便地收听所有这些现有音频,就像我们现在在家里、海滩上、火车上或汽车内听立体声音乐一样。
我们已经开发了这样一种技术,称为3D音场。该系统可在智能手机、普通或智能音箱、头戴式耳机、耳塞、笔记本电脑、电视、条形音箱和车内播放音场音乐。它不仅可以将单声道和立体声录音转换为音场,还允许未经特殊训练的听众根据自己的喜好,使用图形用户界面重新配置声场(sound field)。例如,听众可以指定每个乐器和声乐源的位置,并调整各自的音量,改变相对音量,例如伴奏乐器与人声乐的对比。该系统在这里应用了人工智能(AI)、虚拟现实和数字信号处理(稍后将详细介绍)。
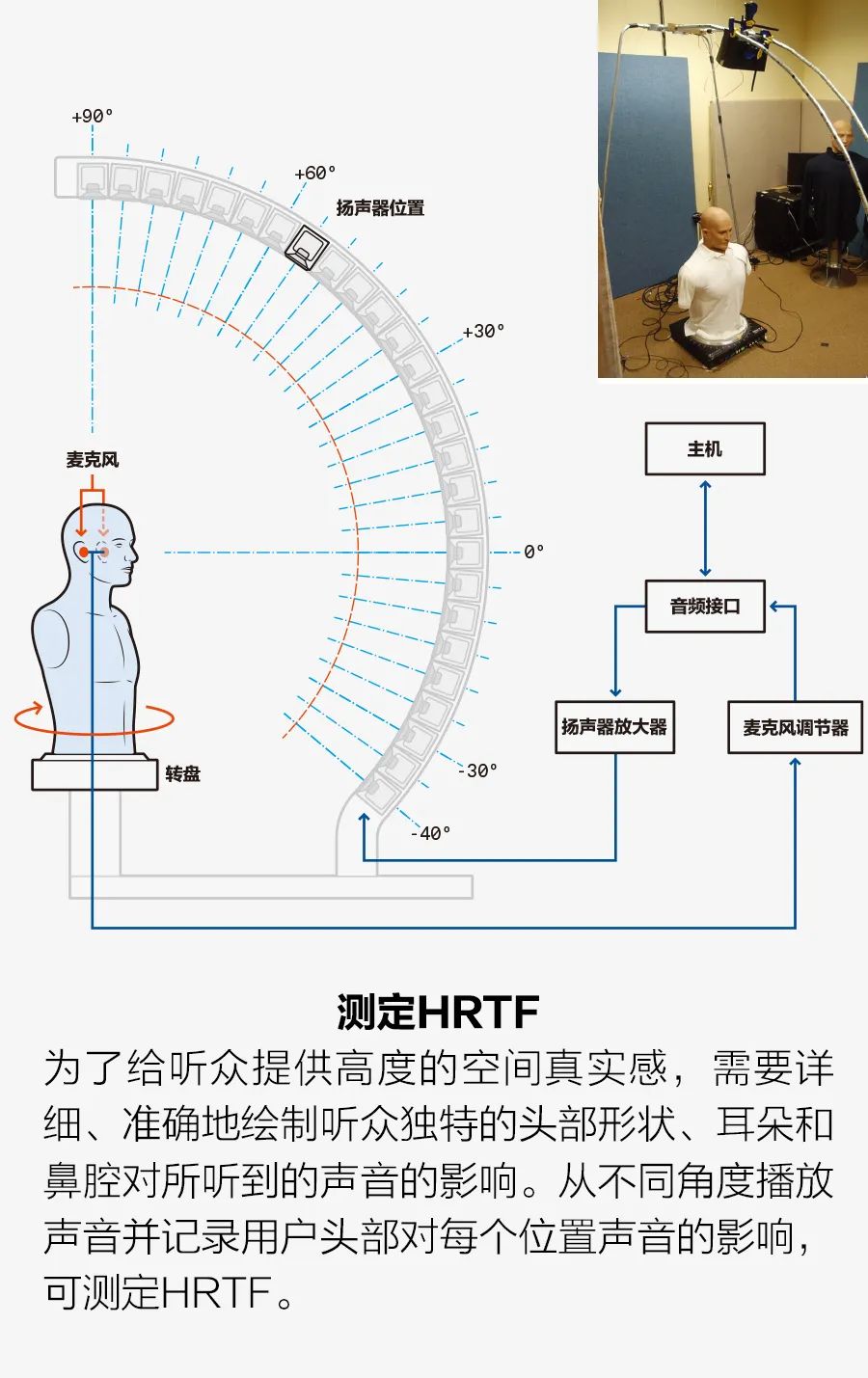
要用两个小扬声器(比如一副头戴式耳机)令人信服地再现弦乐四重奏等声音,需要大量的技术技巧。要了解这是如何做到的,还要从感知声音的方式说起。 当声音传到耳朵时,你头部的特征,包括物理形状、外耳和内耳的形状,甚至是鼻腔的形状等,都会改变原始声音的音频频谱。此外,一个声源传送到两只耳朵的时间也有非常细微的差别。通过这种频谱变化和时间差,大脑可以感知声源的位置。频谱变化和时间差可以根据头部相关传递函数(HRTF)进行数学建模。在头部周围三维空间的每个点都有一对HRTF,一个用于左耳,另一个用于右耳(见插图“测定HRTF”)。 因此,使用一对HRTF来处理一段给定的音频,一个用于右耳,另一个用于左耳。为了重现最初的体验,我们需要考虑声源相对于录制麦克风的位置。然后播放处理过的音频,例如通过一副头戴式耳机,听众将听到音频中带有原始提示,感觉到声音来自最初录制的方向。 如果没有原始位置信息,我们可以简单地指定每个音源的位置,并获得基本相同的体验。听众不太可能注意到表演者位置的细微变化,事实上,他们可能更喜欢自己的配置。 许多商业化的应用程序都使用HRTF为使用头戴式耳机和耳塞的听众创建空间音响。苹果公司的Spa-TIalize Stereo就是一个例子。这项技术将HRTF应用于播放音频,令人感受到空间音效,即比普通立体声更逼真的更深层次的声场。苹果公司还提供了一个头部追踪器版本,使用iPhone和AirPods上的传感器跟踪头部(AirPods)和iPhone之间的相对方向。然后,使用与iPhone方向相关联的HRTF生成空间音频,使人感觉是自己听到的是来自iPhone的声音。这不是我们所说的音场音频,因为乐器的声音仍然混合在一起。例如,你感觉不到小提琴手在中提琴手左边。

不过苹果公司确实有一款产品试图提供音场音频:苹果SpaTIal Audio。我们认为,与普通立体声相比,这是一个显著的改进,但仍然有一些问题需要解决。首先,它结合了杜比全景声,这是杜比实验室开发的一种环绕声技术。Spatial Audio使用一组HRTF为头戴式耳机及耳塞创建空间音频。但是,采用杜比全景声意味着,要使用这项技术,所有现有立体声音乐必须重新灌录,而重新灌录数百万单声道和立体声歌曲几乎是不可能的。Spatial Audio的另一个问题是,它只支持头戴式耳机或耳塞,而不支持扬声器。因此,那些喜欢在家里和车里听音乐的人无法获益。
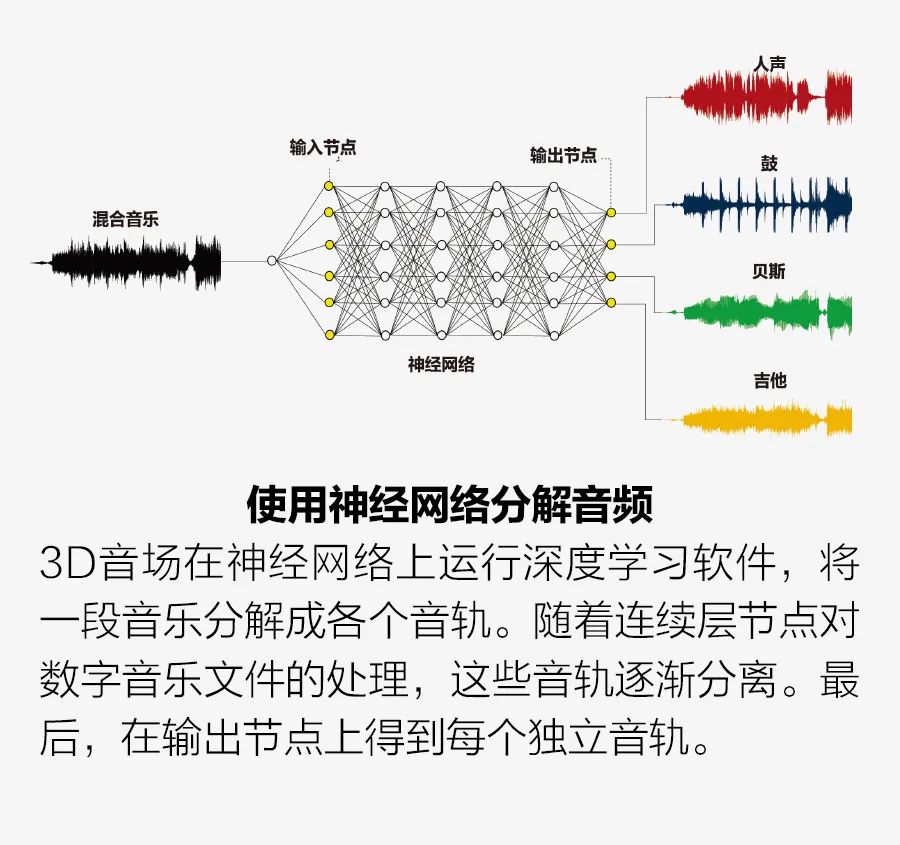
那么我们的系统是如何实现逼真的音场音频的呢?我们首先使用机器学习软件将音频分解成多个单独的音轨,每个音轨代表一种或一组乐器/歌手。这种分离过程称为混音(upmixing)。一个制作人,甚至是未经特殊训练的听众都可以将多个音轨重新组合,重建和个性化所需的声场。
假设要处理的是一首四重奏,音乐由吉他、贝司、鼓和人声组成,听众可以根据个人喜好决定表演者的位置并调整音量;可以使用触摸屏安排声源和听众在声场的虚拟位置,实现满意的配置效果。图形用户界面显示一个舞台的形状,上面覆盖着指示音源的图标,包括人声、鼓、贝司、吉他等。中间有一个头部图标,表示听众的位置。听众可以根据自己的喜好,触摸并拖动头部图标来更改声场。 将头部图标靠近鼓时,鼓声会更突出。如果听众将头部图标移动到表示一个乐器或一位歌手的图标,听众将听到表演者的独奏(唱)。重点是允许听众重新配置声场,3D音场为音乐欣赏增加了新维度(如有不当,请多包涵)。 如果你想通过头戴式耳机或普通的左右声道系统收听音频,转换后的音场音频可以有两个声道;如果你想在多扬声器系统上播放,它还可以是多声道的。在后一种情况下,可以由2个、4个或更多扬声器创建音场。重建声场中不同音源的数量甚至可能大于扬声器的数量。 这种多声道方法与普通的5.1和7.1环绕声道不同。5.1和7.1环绕声道通常有5或7个单独的频道,每个频道都有一个扬声器,外加一个低音炮(即数字5和7后的“.1”)。多扬声器创建的声场比标准的双扬声器立体声设备更具沉浸感,但它们仍达不到真正的音场录制所能带来的真实感。当通过此多声道设备播放时,我们的3D音场录音会绕过5.1、7.1或任何其他特殊音频格式,包括多音轨音频压缩标准格式。
简单介绍一下这些标准格式。为了更好地处理数据,改进环绕声和沉浸式音频应用,最近一系列新标准推出,包括沉浸式空间音频的空间音频对象编码(SAOC)和MPEG-H 3D音频标准。这些新标准继承了几十年前开发的各种多声道音频格式及其相应的编码算法,如杜比数码环绕声AC-3和DTS。 在开发新标准格式时,专家必须考虑到人们的各种要求和期望的功能。人们想要与音乐互动,例如改变不同乐器组合的相对音量。他们想要不同的多媒体流、不同的网络、不同的扬声器配置。空间音频对象编码的设计考虑了这些功能,允许高效存储和传输音频文件,同时保留了听众根据个人喜好调整混音的可能性。 但是,要实现这一点,要依赖于各种标准化编码技术。空间音频对象编码需要通过编码器来创建文件。编码器的输入是一批包含音轨的数据文件;每个音轨文件表示一个或多个乐器。编码器基本上使用标准化技术来压缩数据文件。在播放过程中,音频系统中的解码器对文件进行解码,然后通过数模转换器将这些文件转换成多声道模拟声音信号。 我们的3D音场技术绕过了这一点,使用单声道、立体声或多声道音频数据文件作为输入。我们将这些文件或数据流划分为多个分立音源的音轨,然后根据听众偏好的配置,将这些音轨转换为双声道或多声道输出,驱动多个扬声器或头戴式耳机。我们使用人工智能技术避免多声道重录、编码和解码。

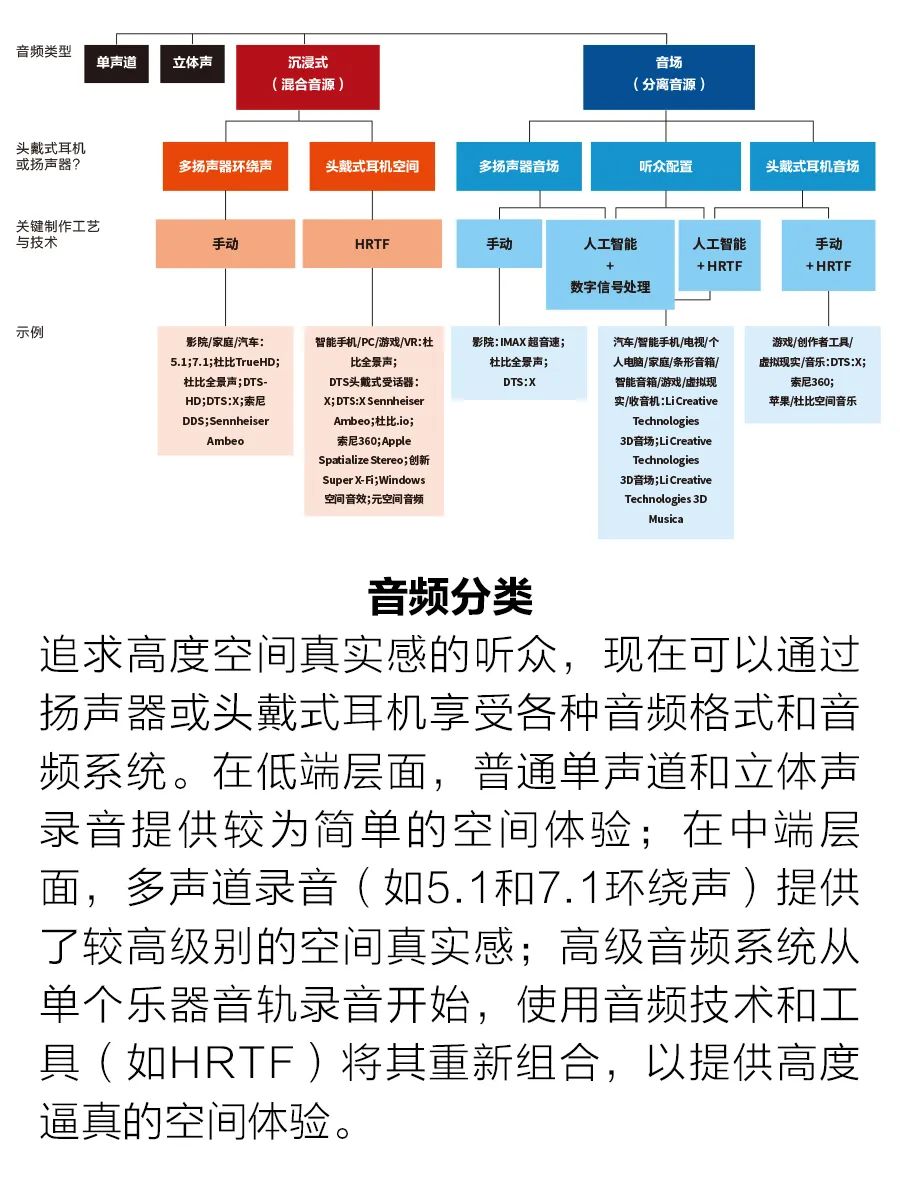
事实上,我们在开发3D音场系统时面临的最大的技术挑战是编写机器学习软件,将传统的单声道、立体声或多声道录音实时分离(或混合)成多个独立的音轨。该软件在神经网络上运行。我们于2012年开发了这种音乐分离方法,并在2022年和2015年获得的专利(美国专利号:11240621 B2和9131305 B2)中进行了描述。 典型的过程包括两个部分:训练和混合。在训练过程中,大量的混音歌曲及其独立的乐器和声乐音轨,分别用作神经网络的输入和目标输出。训练过程中使用机器学习来优化神经网络参数,使神经网络的输出(乐器和声乐的单个音轨数据的集合)与目标输出相匹配。 神经网络是非常松散的人脑模型。它有一个输入节点层,代表生物神经元,接着是许多中间层,称为“隐藏层”。最后是一个显示最终结果的输出层。在我们的系统中,输入节点的数据为混合音轨的数据。当这些数据通过隐藏层节点进行处理时,每个节点计算生成加权值的总和(见插图“使用神经网络分解音频”)。然后对总和进行非线性数学运算。此计算确定是否以及如何将来自此节点的音频数据传递到下一层的节点。 这样的层有几十个。随着音频数据从一层传输到另一层,各个乐器逐渐相互分离。最后,在输出层中,每个独立的音轨被输出到输出层中的一个节点。 不过,在训练神经网络时,输出可能会偏离目标。例如,它可能不是一个独立乐器的音轨,或它可能包含两种乐器的音频成分。在这种情况下,将调整权重方案中的单个权重,确定数据如何从隐藏节点传输到隐藏节点,然后再次运行训练。这种迭代训练和持续调整会一直继续,直到输出与目标输出接近完美地匹配为止。 与机器学习的任何训练数据集一样,可用的训练样本越多,最终的训练效果越好。我们需要数万首歌曲及其单独乐器音轨来进行训练,总训练音乐数据集为数千小时。 在神经网络经过训练后,输入一首混音歌曲,经过训练建立的系统神经网络运行,输出多个独立的音轨。
将一段录音分解成音轨成分之后,下一步是将它们重新混合成一段音场录音。这是由音场信号处理器完成的。音场处理器执行复杂的计算功能,生成驱动扬声器的输出信号,产生音场音频。发生器的输入包括独立音轨、扬声器的物理位置以及重建声场中的听众和音源的期望位置。音场处理器的输出是一个多音轨信号,每个声道一个,用于驱动多个扬声器。 如果声场是由扬声器产生的,它可以位于物理空间中;如果声场是由头戴式耳机或耳塞产生的,它也可以位于虚拟空间中。音场处理器的功能基于计算声学和心理声学实现,考虑了在期望声场中声波的传播和干扰,以及听众的HRTF和期望声场。 例如,如果听众想要使用耳机,生成器将根据期望音源位置的配置选择一组HRTF,然后使用所选的HRTF过滤独立的音源音轨。最后,音场处理器组合所有的HRTF输出,为耳机生成左右音轨。如果听众想在扬声器上播放音乐,至少需要使用两个扬声器,扬声器越多,声场越好。重建声场中的音源数量可以多于或少于扬声器的数量。
我们于2020年推出了第一个支持iPhone的音场应用程序3D Musica。它允许听众实时配置、收听和保存音乐,处理过程不会造成可感觉的时间延迟。3D Musica可以将听众个人音乐库、云端甚至流媒体音乐中的立体声音乐实时转换为音场音乐。(对于卡拉OK录音,该应用程序可以删除人声或输出任一单独乐器。) 2022年早些时候,我们开设了门户网站3dsoundstage.com,提供云端3D Musica应用程序的所有功能,以及应用程序编程接口(API),因此流媒体音乐提供商,甚至任何流行网页浏览器的用户都可以使用这些功能。现在,基本上任何人都可用任何设备听音场音频的音乐。 我们还为车辆和家庭音频系统和设备开发了不同版本的3D音场软件,可用2个、4个或更多扬声器重建3D声场。除了音乐播放,我们希望视频会议中也能应用这项技术。我们许多人都体验过参加视频会议的疲惫。参加视频会议时,我们很难清楚地听到其他与会者的声音,还可能搞不清是谁在讲话。而应用音场,你可以配置音频,听到每个人的声音来自虚拟房间的不同位置,“位置”指派可简单地按照参会者在Zoom和其他视频会议应用程序中的网格位置。这样一来,至少对一些人来说,视频会议不会太累,讲话也更容易听清楚。
正如音频从单声道到立体声,从立体声到环绕声和空间音频一样,它现在也开始走向音场。在早期,发烧友评估音响系统的保真度根据的是带宽、谐波失真、数据分辨率、响应时间、无损或有损数据压缩,以及其他与信号相关的参数。现在,音场可以看成是声音保真度的另一个维度,我们甚至敢说,这是最基本的维度。对于人耳而言,相比不断改善谐波失真,有空间提示、具备扣人心弦的即时性的音乐所带来的影响更为显著。这是录制音频第一次在与保真度相关外,还考虑到了心理声学和更广泛的大脑活动。这个非凡特性提供的体验甚至超过了许多财力雄厚的音响发烧友的体验。 技术推动了音频产业的前几次革命,现在它正在掀起另一场革命。人工智能、虚拟现实和数字信号处理正在利用心理声学为音频爱好者提供前所未有的体验。同时,这些技术为唱片公司和艺术家提供了新的工具,为旧唱片注入了新的活力,并开辟了创作的新途径。令人信服地重现音乐厅音响的百年目标终于实现。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。