






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服目前,学术圈还是用“打榜”来对自动驾驶算法评分。所谓“打榜”就是在某一数据集上利用其训练数据集来测试算法的优劣,目前自动驾驶圈内最常用的打榜数据集是安波福Aptiv旗下的nuScenes。严格意义上的自动驾驶算法评分对比几乎是不可能的,单独对比算法不够公允,此外还必须考虑算法的效率和落地可行性。训练数据集的数据结构也会影响算法的发挥。同时由于深度学习的不可解释性,在nuScenes数据集上表现好不代表在其他数据集也会表现好,也许会表现得很差,同样道理在nuScenes数据集上表现不好不代表在其他数据集也表现不好。当然算力大小无关算法的准确度。
nuScenes数据集的任务包括六大类,分别是3D目标检测detection、目标追踪tracking、目标轨迹预测prediction、激光雷达目标分割lidar segmentation、全景panoptic、决策planning。其中,3D目标检测是自动驾驶最基础的任务,全球有近300个团队或企业参加了比试,也是全球自动驾驶数据集参赛者最多的,足见其权威性。决策任务的榜单还没有公布,因为打榜的人太少了。目标追踪、目标轨迹预测参与热度相对还比较高,而激光雷达目标分割和全景参与热度就很低了,不到20家参与。
近期打榜的基本都是中国企业或高校,除了中国,其他地区对自动驾驶缺乏兴趣,即便在美国,研究自动驾驶的基本都是华人。很少有车企会参与打榜,早期还有奔驰、博世等企业参加,奔驰的成绩惨不忍睹,博世还不错。车企不参加打榜的原因很简单,成绩好消费者也不知情,成绩差的话就会被竞争对手拿来攻击,干脆不参与,要参与就是对自己的能力非常自信,就比如零跑和上汽。
前15名如下:
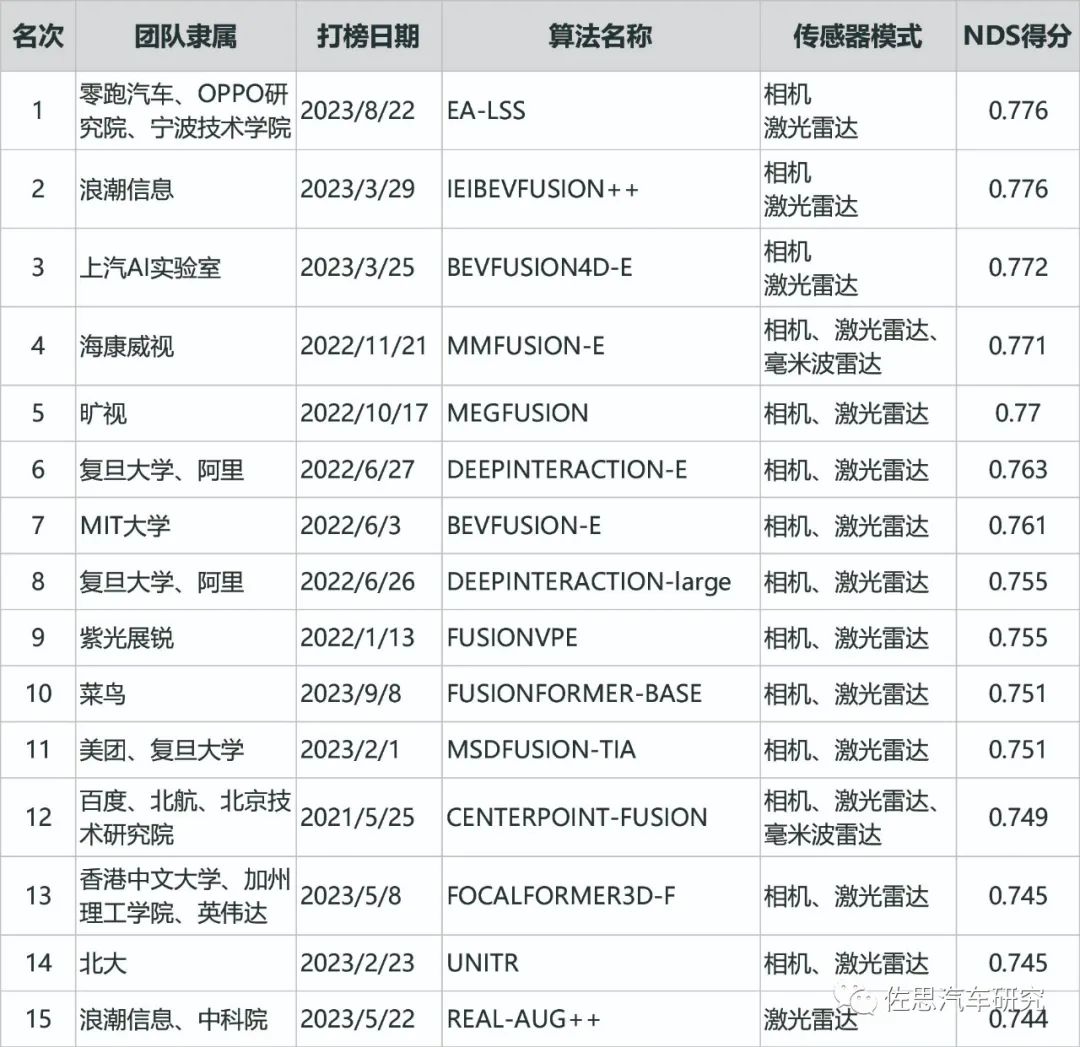
资料来源:公开信息整理
nuScenes数据集的灵感来自开创性的KITTI数据集(丰田与德国KIT于2012年完成)。nuScenes是首个提供自动驾驶汽车整个传感器套件(6个摄像头、1个LiDAR、5个Radar、GPS、IMU)数据的大规模数据集。与KITTI相比,nuScenes包含了7倍多的对象注释。完整的数据集包括大约1.4M相机图像(camera images),390k激光雷达扫描(LiDAR sweeps),1.4M雷达扫描(Radar sweeps)和1.4M物体边界框(object
bounding boxes)在40k关键帧。为方便常见的计算机视觉任务,如对象检测和跟踪,在整个数据集上以2Hz的速度用精确的3D包围框注释了23个对象类;还注释了对象级属性,如可见性、活动和姿势。
如果只用相机也就是纯视觉,地平线的Sparse4D包揽第一名和第二名。旷视的FAR3D是第三名,商汤和香港大学、哈尔滨工业大学等联合的HOP第四名,丰田排名第五。纯视觉的效果比视觉和激光雷达融合的效果落后不少,但纯激光雷达的效果与视觉和激光雷达融合后的效果相差甚微。
3D目标检测的得分共六项(见下表)。
mAP平均精确度,mean of Average Precision的缩写。
mATE,Average Translation Error,平均平移误差(ATE) 是二维欧几里德中心距离(单位为米)。
mASE,Average Scale Error, 平均尺度误差(ASE) 是1 - IoU, 其中IoU 是角度对齐后的三维交并比。
mAOE, Average Orientation Error平均角度误差(AOE) 是预测值和真实值之间最小的偏航角差。(所有的类别角度偏差都在360∘度内, 除了障碍物这个类别的角度偏差在180∘ 内)。
mAVE,Average Velocity Error平均速度误差(AVE) 是二维速度差的L2 范数(m/s)。
mAAE,Average Attribute Error,平均属性错误(AAE) 被定义为1−acc, 其中acc 为类别分类准确度。
其中,mAP是最核心指标。

资料来源:公开信息整理
mAP意思是平均精确度(averageprecision)的平均(mean),是object detection中模型性能的衡量标准。object detection中,因为有物体定位框,分类中的accuracy并不适用,因此才提出了object detection独有的mAP指标,上汽在这个单项中是第一名。

mAP计算流程图,非常复杂,这里的class就是分类,nuScenes有23个分类。Ground truth就是人工标注的真值,当然也可以电脑自动标注,但人工标注是不可或缺的,只是比例多少,一般来说精细标注都是人工标注,电脑自动标注是稀疏标注。Prediction预测就是深度学习模型根据训练数据集给出的答案。要理解平均精确度的概念,要先熟悉几个基本概念:
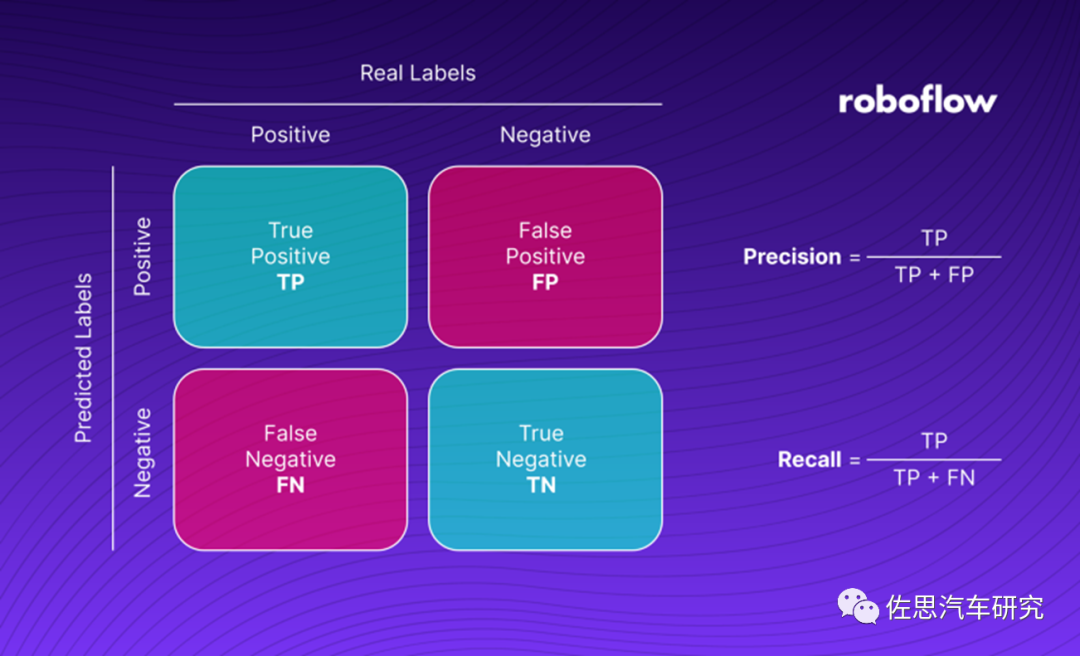
查准率(Precision)是指在所有预测为正例中真正例的比率,也即预测的准确性。
查全率(Recall)是指在所有正例中被正确预测的比率,也即预测正确的覆盖率。
真正率为TP,真反率为TN,假正率是FP,假反率为FN。
查准率是TP/TP+FP,查全率是TP/FP+FN。
单一类别的AP计算,物体检测中的每一个预测结果包含两部分:预测框(bounding box)和置信概率(PC)。bounding box通常以矩形预测框的左上角和右下角的坐标表示,即x_min, y_min, x_max, y_max,如下图。
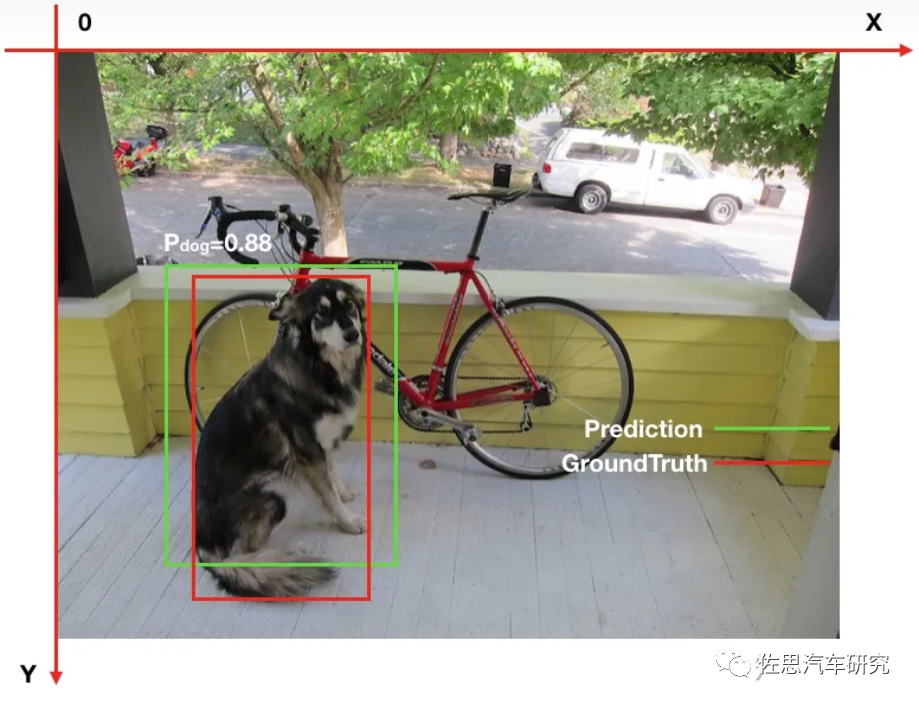
红框为真值也就是groundtruth,真值也就是准确答案;绿框为算法预测值,88%是置信度,简单说就是有88%的可能是狗。

Intersection over Union (IoU),中文一般叫交并比。交并比IoU衡量的是两个区域的重叠程度,是两个区域重叠部分面积占二者总面积(重叠部分只计算一次)的比例。如上图,两个矩形框的IoU是交叉面积与合并面积之比。假设测试数据集中的某一类如“猫”的真值有10个,此算法预测到了5个,“狗”分类真值也有10个,此算法也预测到了10个,那么有如下值。

根据查准率和查全率,按置信度的不同阈值,我们绘制出一条曲线。

Conf.Thresh.就是置信度阈值的缩写。根据表格,可以得到一条查准率和查全率的曲线。AP是一个标量,可以通过两种办法计算得到。
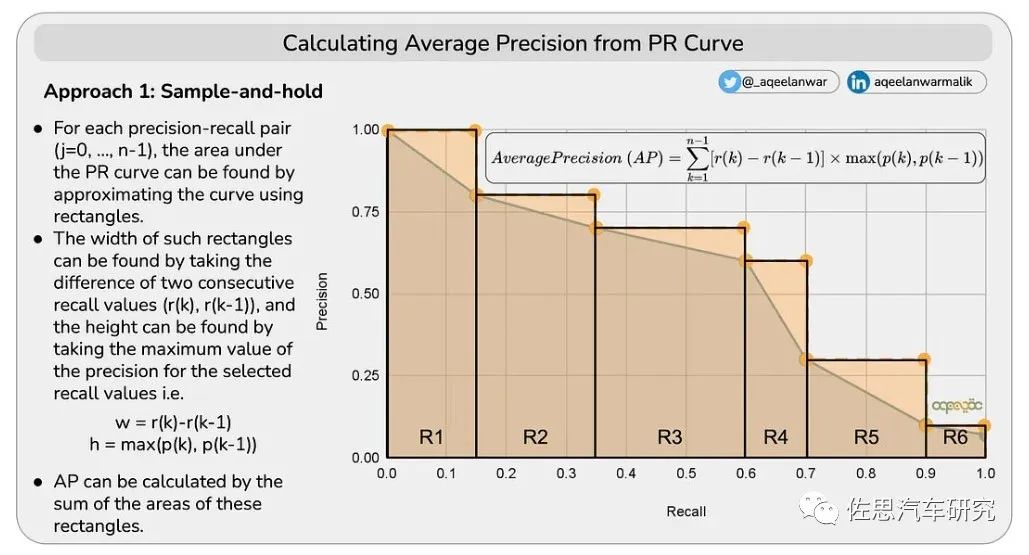
1)通过矩形累加得到AP

2)通过内插10点值计算AP
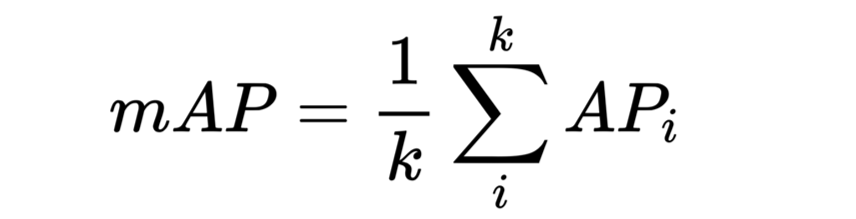
K为分类的数量,即23。
目标追踪榜单如下,只取前五名。

资料来源:公开资料整理
这些打榜的算法主要考虑性能,很少考虑落地性,不过也有考虑到实际落地的算法,如安波福的纯激光雷达的PointPillars,早在2019年3月就有了,mAP只有0.305,但使用1080ti显卡就有每秒61.2的帧率,放宽损失函数最高可达150Hz,资源消耗最小,也是目前最常见的激光雷达算法。
零跑EA-LSS算法延迟

零跑的EA-LSS算法模型是基于英伟达DGX-A100来做的,也就是8张A100显卡,每秒帧率不到15,显然是无法落地的。自动驾驶的发展面临困境,算法越来越复杂,参数越来越多,对算力的需求越来越高,而高算力芯片价格越来越高。不仅是算力还有存储带宽,transformer对存储带宽远高于CNN,而高带宽的HBM价格是主流的LPDDR4/5的十倍以上。不仅是芯片,计算系统的其他芯片或部件亦是如此,这导致自动驾驶系统成本越来越高,最终可能L4级计算系统的价格超过3万美元乃至更高。
相关文章









