有人使用STM32F446做产品开发,用到TIM1的4个通道做PWM输出。具体使用是这样的,选择CHI1采样PMW模式做PMW输出。CH2、CH3、CH4采用比较切换模式结合DMA输出PWM波形,其中各通道的CCR值通过DMA基于比较事件周期性循环修改。
客户使用CubeMx做图形化配置后生成基于HAL库的工程,然后添加相关用户代码。
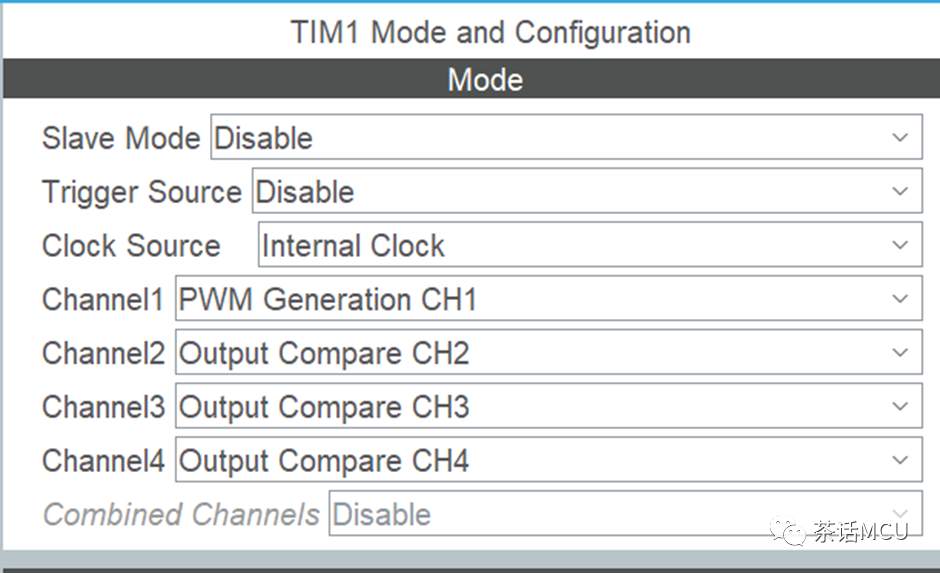
组织完用户代码后,不论代码顺序如何调整,发现总是最多只能启动2路使用OC切换模式结合DMA实现PWM输出的通道。
DMA缓冲区配置:
uint32_t tim_CCR2_Data[] = {8*9, 20*9};
uint32_t tim_CCR3_Data[] = {10*9, 20*9};
uint32_t tim_CCR4_Data[] = {17*9, 20*9};
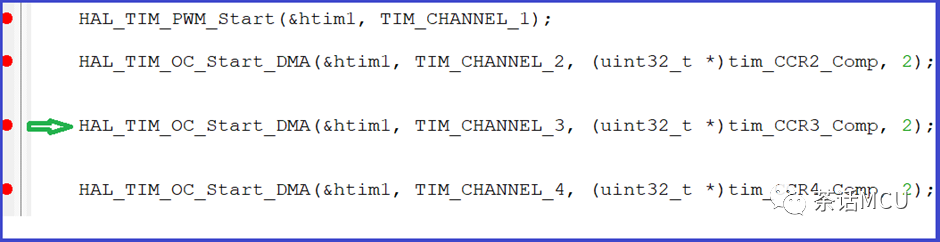
如果按照上图组织代码,代码运行到箭头处就不往下走了,通道4无输出。

如果说代码按照上图组织编写,不仅通道4没输出,连通道1都没有输出。也就是说运行到绿色箭头所指后程序就运行不下去了,至少调试时短时间感觉上是这样。
像这种问题,我怀疑过是否跟HAL库函数里有些状态机变量的处理有关,但从现象来看又不像,因为这里有2个HAL_OC_Start_DMA()函数可以正常运行。现在症状是代码没法正常或者没法顺畅地运行下去,感觉CPU太忙或跑飞了。
先不管它,自己参照客户的功能需求找块F446的板验证下。我测试了相同功能,结果并未遇到客户反馈的问题。我的用户代码跟客户的是一样的,就重点比较我与客户的有关TIMER的时间参数。结果发现我设置的时间参数跟客户设置的差别比较大,客户设置的TIM1的溢出周期远小于我的。看到这里我就基本锁定原因了。我把TIMER时间参数改得跟客户一样后,进行测试。
经过测试立即呈现客户反馈的问题。
TIMER计数溢出时间参数改小了为什么就出现程序不能完整【至少短时间内】运行呢?
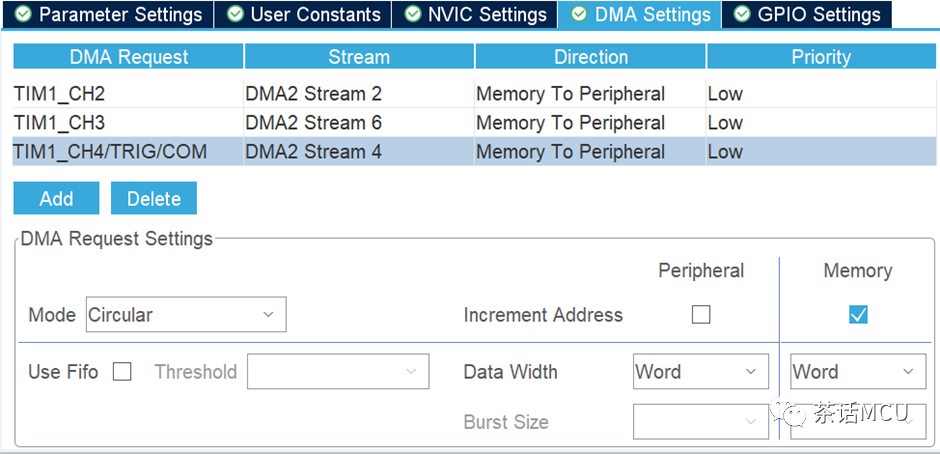
这里使用CubeMx进行配置并采用HAL库编程,当使用OC 切换输出并结合DMA传输功能时,同时也默认开启了DMA传输的完成中断和半完成中断。具体到这里,每个DMA通道只做2个数据的循环传输,因半完成和完成中断都开启了,意味着每传输1个数据就发生1次中断,每个计数周期将发生2次中断,分别是半完成中断和完成中断。显然,当TIMER的溢出周期设置得越小,发生中断的频率就越高。另外,每增加1个通道的DMA传输,意味着每个计数周期内又增加2次中断。
显然,随着开启的OC切换通道的增加,DMA中断就相应增多;另外,随着TIMER计数溢出频率的提升,DMA中断响应就变得更频繁。到达一定程度时就会导致CPU根本没法再往下运行主流程代码,而被频繁的DMA中断死死地缠住。 相反,当TIMER的计数溢出频率放慢下来时,CPU即使依然要频繁响应各个通道DMA中断,但中断响应频率降下来了,此时依然有可能有空闲去继续运行主流程代码,而不至于卡死【或近似卡死】在哪个位置。显然,计数溢出频率越低,就相对越不容易出现程序执行卡死的状况。
事实上,当发生主程序代码运行不下去时我们暂停程序运行时可以非常清晰地看到程序指针都落在DMA中断服务程序的某行代码上。【这里也可以判断程序并非跑飞】
到此,原因搞清楚了,即开启基于DMA传输的2路OC输出后,当定时器的溢出频率到达一定程度时,CPU忙于应付频繁的DMA传输中断,难以抽身或完全抽不开身继续运行主程序代码了。那么,如何解决呢?
在不影响功能需求的情况下,适当放慢TIMER的计数溢出频率的确也是个办法。不过,我们必须清楚,在这种情况下总的DMA中断还是很多的,对CPU资源的耗用较大,必要时可以考虑下面的办法。
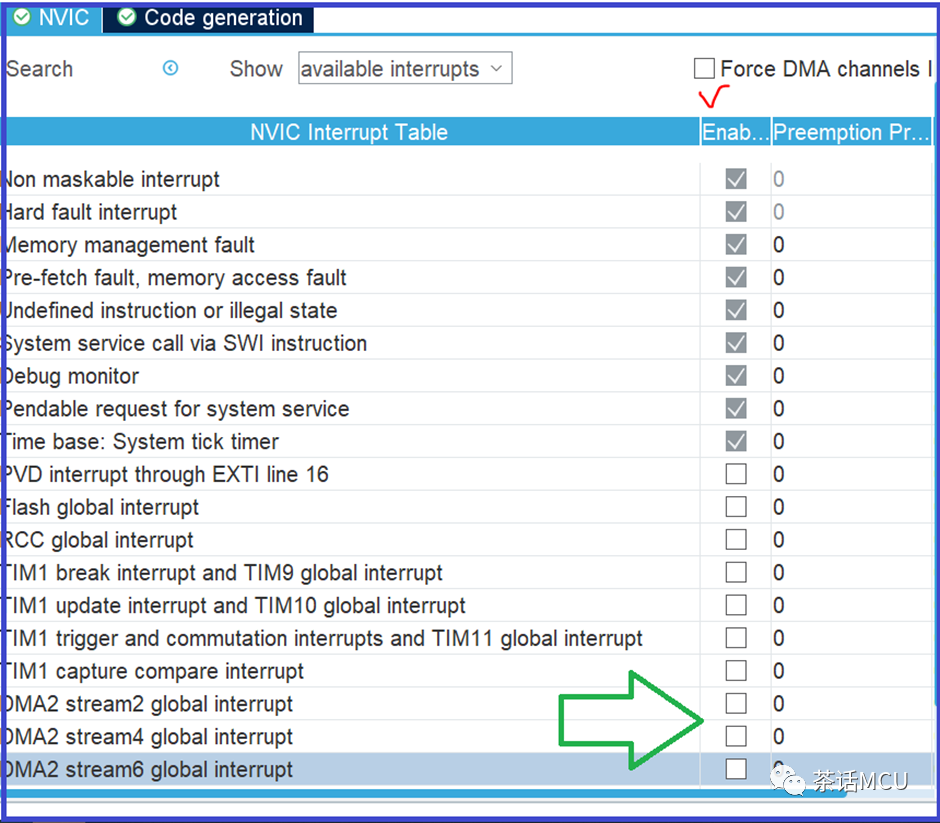
具体到这里,有3个通道使用DMA传输,DMA无非就是周期性修改CCR值来实现特定的波形输出。对于开启DMA传输的半完成中断和完成中断的必要性不大,完全可以关掉二者。其实,哪怕只关闭半完成中断也让CPU负荷大大减少。至于关闭DMA的相关中断使能及响应,我们可以手动调整代码,也可以在进行CubeMx配置时直接关闭其中断响应。有些人可能不了解在CubeMx图形界面下的操作,这里稍作演示。详见下图,先把Force DMA Channel Interrupt复选框取消,然后在DMA中断使能复选框也取消使能,最后变成类似下图的样子。
关于这个主程序代码无法正常运行下去的问题,到底是TIMER原因还是DMA原因呢?应该说问题跟二者密切相关,问题的解决离不开对相关知识点的细致了解。不过,个人认为本质上讲属于中断方面的问题。这里顺便提醒下,我们在使用CubeMx进行配置时,涉及DMA的中断响应的配置都是默认开启了的。另外,使用HAL库的API代码启动DMA时默认也开启了DMA相关中断使能。或许像上面提到的API代码 HAL_TIM_OC_Start_DMA()表面上看不出开启DMA中断的痕迹或提示,但点开进去阅读就会有所发现。







