2024年CES展上,索尼用自家的PS5游戏机遥控原型车AFEELA登台颇为惊艳,预计AFEELA在2025年上市,起售价约为45000美元,首选发售地据悉是北美。AFEELA是高通数字底盘的典型代表。
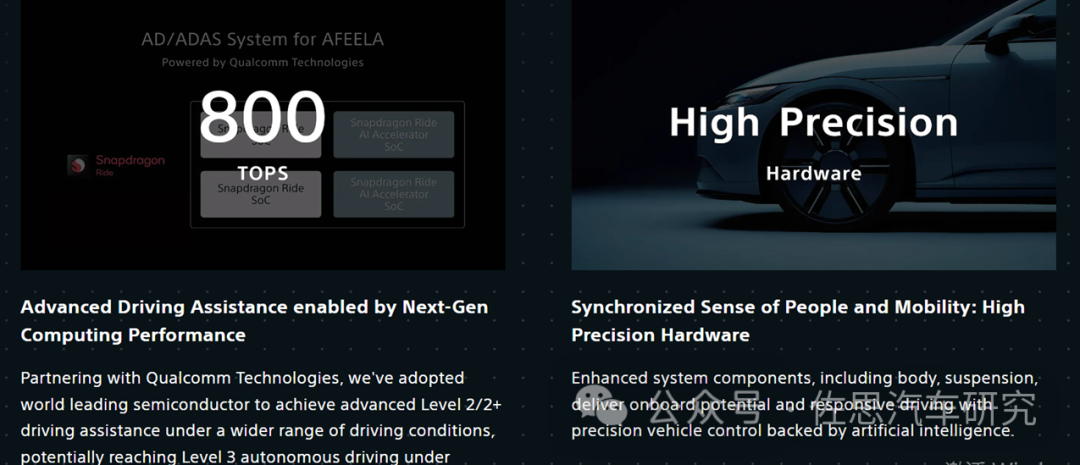
AFEELA具备800TOPS的算力。
图片来源:SHM

图片来源:SHM
AFEELA显然是采用了两套Snapdragon Ride级联,推测SoC是高通的SA8650,加速器是基于Cloud AI 100 Ultra的车载版。
AFEELA的AD/ADAS架构

图片来源:SHM
上图是AFEELA的AD/ADAS架构,不要质疑CNN做感知,即便是2000TOPS的英伟达也支撑不起全Transformer,车载感知的Backbone网络还是基于CNN的,包括特斯拉,特斯拉是Regnet。只有Head才能用得上Transformer,这里的环境模型基本可等同于BEV加占用网络。全Transformer估计得用8张英伟达H200显卡,价格是整车的好几倍了。
SA8650之前笔者已介绍过,高通第一代Snapdragon Ride即SA8540P+SA9000P似乎是过渡产品,SA8540P和高通的SA8295P几乎完全一致,与高通笔记本电脑领域的8cx Gen3即SC8280P也几乎完全一致。
高通自动驾驶一直在英伟达和Mobileye的夹缝中,英伟达凭借超高性能几乎垄断高端市场,而Mobileye以40-70美元的超低价格垄断中低端市场。对大部分厂家,包括保时捷这样的高端品牌,对自动驾驶都缺乏兴趣和重视度,自动驾驶是可有可无,锦上添花的配置,只有Mobileye不到100美元的芯片能满足这些厂家的成本需求,Mobileye牢牢占据全球70%的智能驾驶芯片市场,地位稳如泰山,短期的客户库存调整不会影响Mobileye的未来。高通无意与Mobileye竞争,可能是利润太微薄,高通主要竞争对手就是英伟达,但高通主要市场还是手机,技术核心还在手机上,所以高通的AI加速器是分离的,高通主打的是低功耗和高性价比。
今天我们主要来看高通AI加速器的新产品,即AI 100 Ultra,这是高通2023年11月底推出的产品,就是要挑战英伟达的H100,高通号称单张AI 100 Ultra可以对应1000亿参数的大模型,两张可以对应1750亿参数的ChatGPT 3,功耗和价格远低于英伟达的H100,惠普和联想已经有基于AI 100 Ultra的服务器销售。
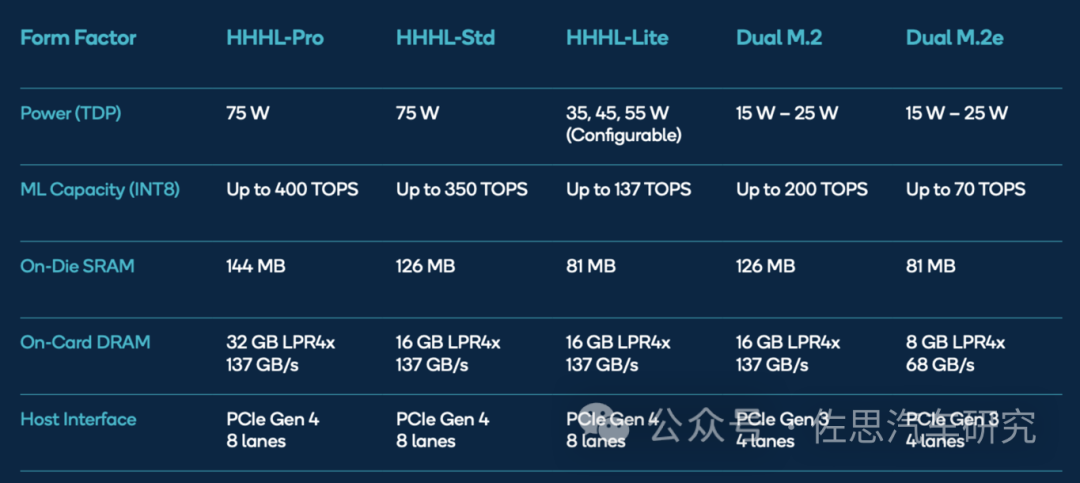
上表是高通2020年9月推出AI 100的各个版本的性能表现。高通目前只有这两款AI加速器,车载的AI加速器毫无疑问是基于AI 100设计的。

从参数上看,当然无法和英伟达H100相提并论,并且H100主打的是FP16精度,高通主打的是INT8精度,高通主要的信心来自其软件优化,即Polyhedral Mapper。

特色主要是核心/线程的并行性,明确的数据传输,以及SIMD的并行性。

上图是一个具体的BERT优化。

主要的挑战一是如何让核心、线程和矢量单元都处于最大利用状态,二是如何利用好本地内存,而不是外部昂贵的HBM内存,三是减少数据搬运。
高通AI加速器架构
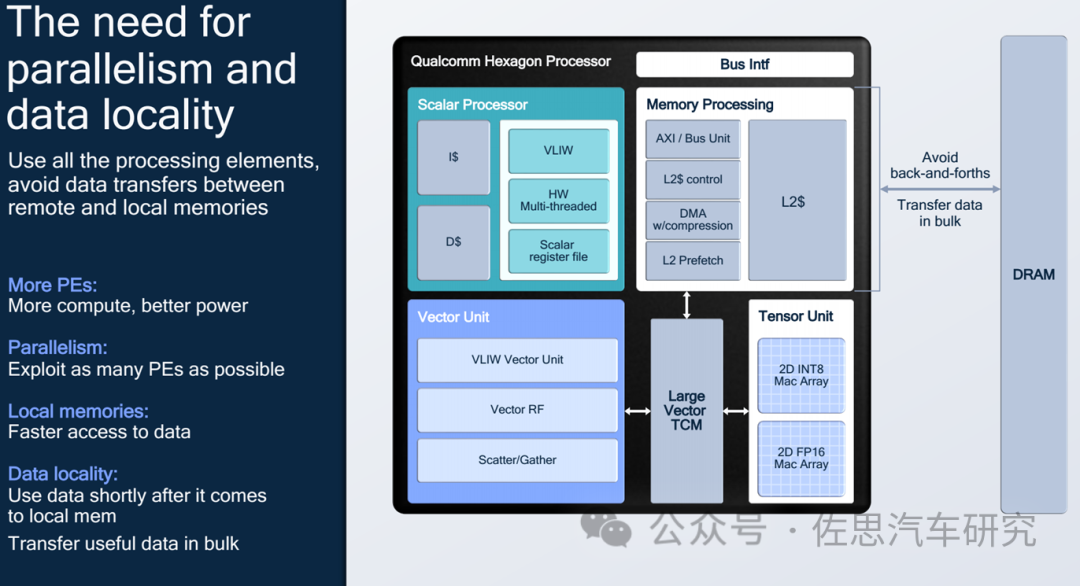
高通AI 100内核
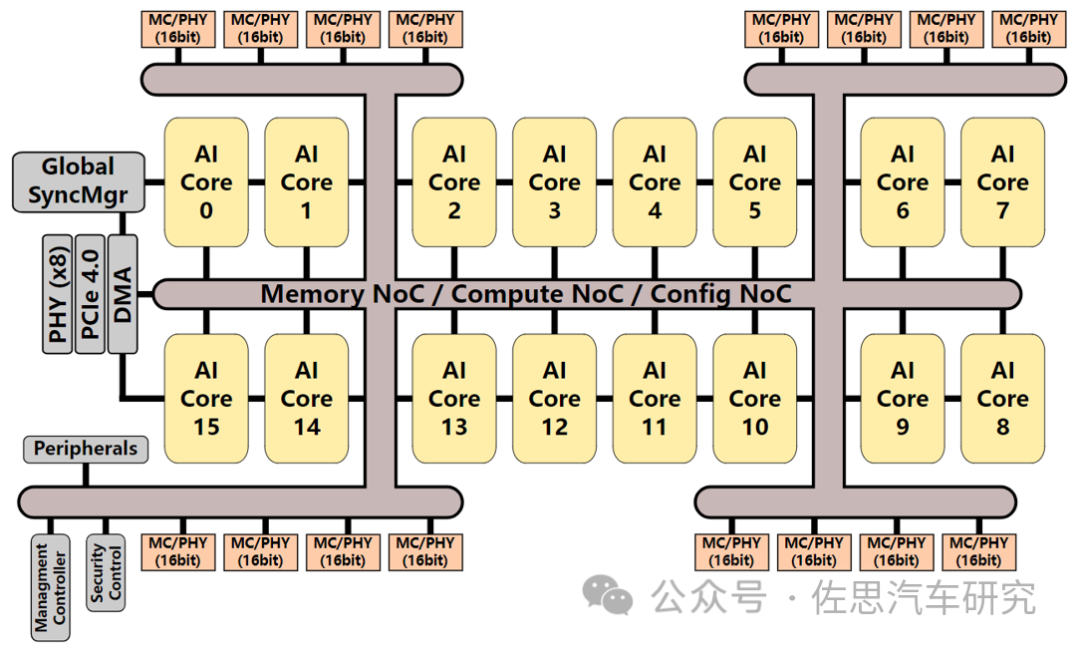
高通AI 100内核是16个,AI 100 Ultra是64个,不过考虑到功耗,性能没有增加4倍。
每个AI核心内部架构
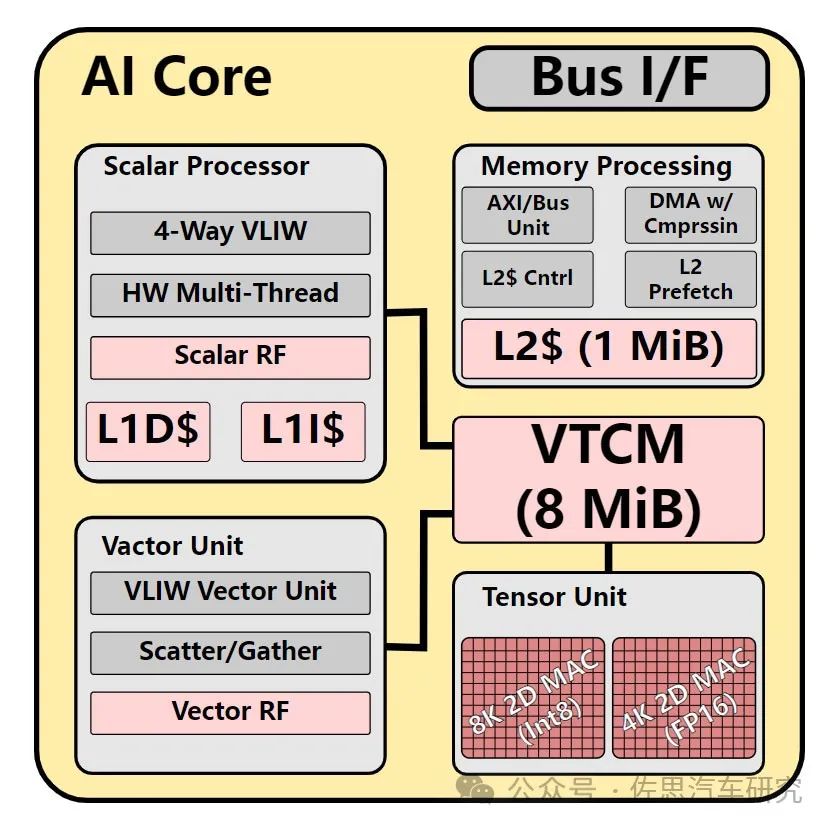
大多数车载AI加速器只有张量Tensor计算单元,且只有INT8,高通的不仅包括张量还有标量Scalar和矢量Vector单元。张量分INT8和FP16两种,INT8有8192个MAC,FP16有4096个MAC。标量与矢量单元都是VLIW指令集,跟高通手机芯片中的DSP完全一致。
每核心有1MB的L2缓存,有8MB的VTCM存储,所谓VTCM是Vector Tightly-Coupled Memory紧耦合矢量存储,合计每个AI核心有9MB的SRAM,64个内核就是576MB的SRAM,SRAM的成本每MB约5美元,也就是2880美元,AI 100 Ultra至少一半以上的die size是SRAM,一半以上的成本也来自SRAM,估计AI 100 Ultra售价是6000美元左右。
矢量计算需要频繁搬运数据,特别是矢量矩阵运算,Transformer里主要延迟都来自矢量矩阵运算。

上图是三星对GPT大模型workload分析,在运算操作数量上,GEMV矩阵矢量乘法所占的比例高达86.53%,在大模型运算延迟分析上,82.27%的延迟都来自GEMV;GEMM矩阵通用乘法所占仅为2.12%,非线性运算也就是神经元激活部分占的比例也远高于GEMM。
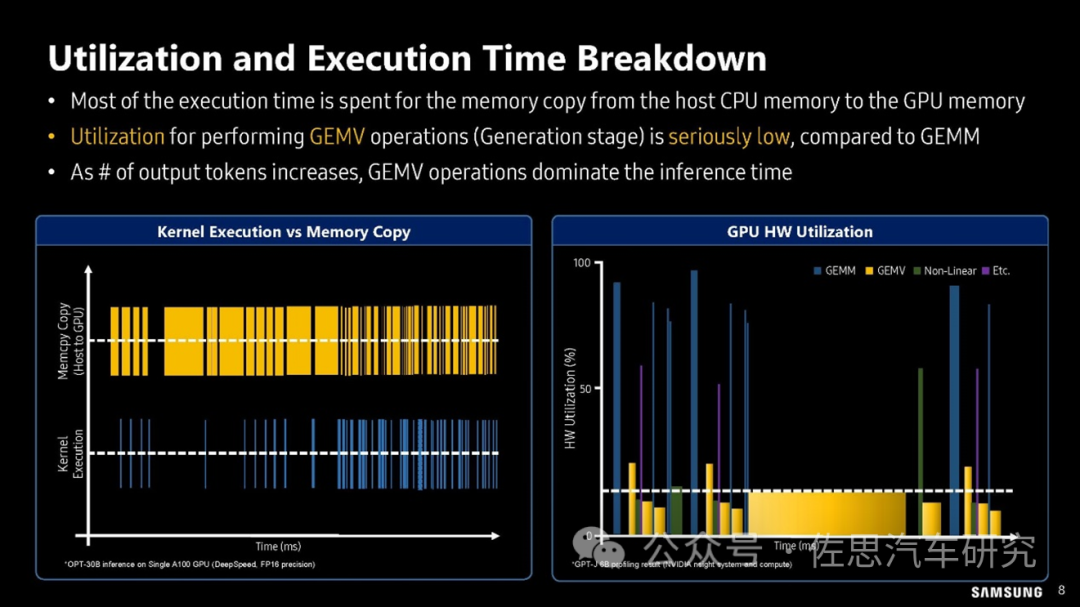
上图是三星对GPU利用率的分析,可以看出在GEMV算子时,GPU的利用率很低,一般不超过20%,换句话说80%的时间GPU都是在等待存储数据的搬运。所以芯片内部的TCAM非常有必要,其效果要比芯片外部的HBM更好,缺点是容量远不能和HBM比,用于训练和汽车级模型推理比较好。
AI 100 Ultra的存储系统升级不少,从原来的137GB/s升级至576GB/s,但还是用了老旧的LPDDR4,实际就是内存控制器增加到了4路,每路128bit,合计512bit。接口方面,PCIe提升到第四代,Lane增加到16。
AI加速器硬件似乎已走到了尽头,能做文章的只有存储部分和制造工艺,更先进的制造工艺容纳更多的计算单元,更高bit的内存控制器增加存储带宽或者升级HBM,像英伟达的H200,只是存储部分更换成了HBM3,其余与H100完全一致。