Arm:从低端应用杀入机器学习市场
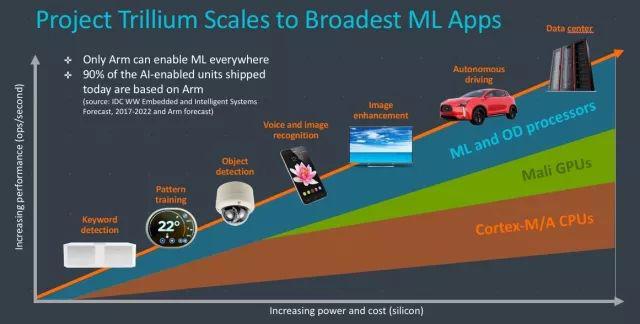
Arm在2018年2月推出自己的人工智能平台:Project Trillium。在硬件IP层面,除了支持机器学习功能的Cortex -A/Cortex-M CPU与Mali GPU,Project Trillium平台还带来了全新的机器学习专用IP核,即面向通用机器学习应用的机器学习处理器(ML Processor),以及监控、视频识别场景专用的目标检测处理器(OD Processor)。
在3月7日北京Arm全球技术发布会上,Arm资深市场营销总监Ian Smythe表示,Trillium项目是Arm一个全新的技术产品架构,该项目能够为客户带来最灵活、最高可扩展的机器学习产品方案。“我们相信Trilium项目能够为客户带去市场上最优秀的机器学习专用芯片和目标检测专用芯片。”
据Ian介绍,Trillium项目中的机器学习处理器和目标检测处理器均为全新设计,与原有CPU、GPU相比,新处理器在机器学习应用上的性能与效率均有大幅提升。机器学习处理器,可支持7纳米工艺,具备每平方毫米4.6万亿次每秒(4TOPs)的计算力,效率可达3万亿次计算每秒每瓦(3TOPs/W),能否满足移动设备对效率和成本的需求。“这款机器学习处理器专门为机器学习和神经网络引用而设计,其性能密度非常高,能效比也非常好,在实际应用中优化以后,性能还可以提高2到4倍。” Ian指出,机器学习首款芯片将在2018年中面世。
Arm的第一代目标检测处理器已经投产,技术来源于2016年收购的Apical公司。跟随Trillium推出的是第二代目标检测处理器,性能上有了更大提升,在全高清分辨率下可以做到实时每秒60帧的检测,而对目标物的检测数量几乎没有限制。
在硬件IP之上,Arm也提供完整的机器学习软件框架,其中有针对Arm所有硬件的专用计算库,同时它也支持市场上所有主流人工智能框架。Arm 机器学习计算平台能够支持多样化的机器学习使用场景,并且支持各式各样的设备。“Arm机器学习解决方案所应用的第一个市场细分,就是移动手机以及智能摄像头的市场。但Trillium项目的目标是非常明确的,最终ML将会实现全场景的覆盖。”

机器学习正在由数据中心走向边缘设备,由于应用特性,在带宽、功耗、基础建设成本、用户体验、可靠性与安全方面,边缘机器学习设备更有优势。“Arm的机器学习平台高可扩展的,从低至2到20GOPs,到高至70TOPs的应用,Arm都有相应产品。但是我们在做机器学习处理器时,首先要做到的是从小做起,从最低端的机器学习应用做起。”
附录:Arm Trillium平台简介
性能
Arm全新的机器学习和目标检测处理器不仅相比于独立的CPU, GPU和各种加速器有了显著的效率提升,而且远胜像DSP这样的传统可编程逻辑处理器。
Arm 机器学习处理器是专门针对机器学习而重新设计的。它基于高度可扩展的Arm 机器学习架构, 并达到了机器学习应用场景要求的最高性能和效率:
-
在移动计算领域,Arm 机器学习处理器可以提供每秒超过4.6万亿次的运算能力。
-
凭借智能数据管理,每秒万亿次的运算(TOPs, Trillion Operations Per Second)在实际应用中可以进一步实现2~4倍的有效吞吐量的提升。
-
在散热和和成本受限的环境下,Arm 机器学习处理器能够以超过每瓦特每秒3万亿次运算操作的效能(TOPs/W)达到无以伦比的性能。有关Arm机器学习处理器的更多细节可在我们的网站上找到。
Arm 目标检测处理器是专门为高效识别人或其他物体而设计的,它能够在每帧图像中识别出的物体对象的数目几乎不受限制:
-
在全高清分辨率下可以做到实时每秒60帧的检测。
-
性能可以达到传统DSP的80倍,并且相对于以往的Arm技术,检测质量有了显著提高。有关Arm 目标检测处理器的更多细节可在我们的网站上找到。
组合使用时,Arm深度学习处理器和目标检测处理器性能表现会更好,它们搭配能够提供高性能、高能效的人物检测和识别解决方案。基于这些技术,用户们将会在省电的模式下,在他们的智能设备上尽情体验高分辨率的,且实时、精细的人脸识别功能。
当和Arm Compute Library和CMSIS-NN一起使用时, Arm神经网络(NN)软件库专门为神经网络运算(NN)进行了优化,并且无缝的把如TensorFlow、Caffe和Android NN等神经网络框架和全系列的Arm Cortex® CPU, Arm Mali™ GPU, 和机器学习处理器高效连接在一起。这样开发人员能够充分利用底层Arm硬件的能力和性能,从而从ML应用中获得最高的性能。关于Arm NN软件的更多细节可在我们的网站上找到。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。