ARM嵌入式编译器(五) 优化循环的4种方法
1. 循环展开
循环执行的时间取决于循环的次数,循环中每次检查是否进行循环的条件会降低循环的性能。使用循环展开可以减少检查条件的判断次数,但是展开循环就意味着增加代码量。例如:在精确的时钟周期循环中,可以使用#pragma unroll (n)来展开循环。
“pragma”(编译指示)仅在选择优化等级为-O2/-O3/-Ofast和-Omax时有效。
编译指示的相关用法:

注:虽然给出了循环展开的编译指示,但Arm官方不建议使用,这样会影响编译器的展开优化和其他循环优化。
将代码分别复制到file.c文件中,然后使用以下命令进行编译和反汇编。
armclang --target=arm-arm-none-eabi -march=armv8-a file.c -O2 -S -o file.s
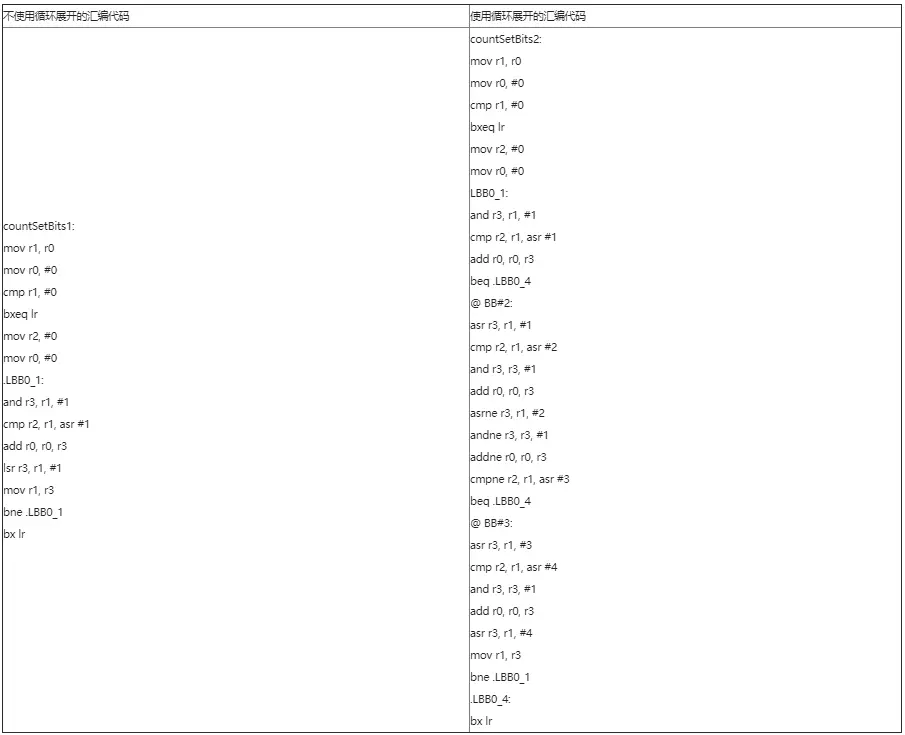
可以看到展开循环时,代码执行会更快,但代码量也更大。
2. 循环向量化
如果编译的目标含有SIMD单元,那么编译器就可以使用向量引擎来优化代码的向量部分。在优化等级为-O1,可以使用-fvectorize 来启动优化,而在-O2或更高等级时向量优化是自动启用。
要使用向量优化,在编写代码的时候需要将结构体的成员放到同一个循环中,而不能使用独立的循环。

对于每个例子,将代码分别复制到file.c文件中,然后使用以下命令进行编译和反汇编。
armclang --target=arm-arm-none-eabi -march=armv8-a file.c -O2 -S -o file.s

在64位运行状态下要避免编译器使用SIMD向量优化可以在-march或-mcpu后+nosimd;
例如:
armclang --target=aarch64-arm-none-eabi -march=armv8-a+nosimd -O2 file.c -S -o file.s
在32位运行状态下要避免编译器使用SIMD向量优化,可以通过设置-mfpu=fp-armv8;
例如:
armclang --target=aarch32-arm-none-eabi -march=armv8-a -mfpu=fp-armv8 -O2 file.c -S -o file.s
3. 循环终止
在写循环的时候如果编写不当会使得代码的运行效率降低和代码量增大。建议使用以下的终止条件:
1)使用变量类型为:unsigned int
2)使用向下减少的计数方式,以减到0作为计数结束。
3)使用简单的终止条件。
单独或组合使用以上原则的终止条件,可以获得更好的代码大小或效率。
例如:这是一个实现n!的计算程序。

用以下命令反汇编以下armclang -Os -S --target=arm-arm-none-eabi -march=armv8-a

对比反汇编代码可以看出在递减循环中用SUBS指令代替了递增循环中ADD 和CMP两条指令。这是因为SUBS指令会自动更新Z标志。
此外在递减循环中变量n不必再循环的过程实时使用,从而减少了寄存器的数量。
如果终止条件是一个函数,则循环的每次都调用该函数,这种情况下递减的循环优势就更明显了。例如:
for (...; i < get_limit(); ...);
说明:这种递减循环计数的方式也适用于while-do 命令。
4. 无限循环
在某些情况下armclang会删除一些编译器认为没有影响的无限循环,从而导致最终程序无法正常运行。
为确保无限循环的正确编译执行,ARM官方建议在无限循环中添加__arm volatile的声明。这个声明的目的是告诉编译器删除这个无限循环会有影响,不能被优化删除。在无限循环中,把处理器设置为低功耗模式是一个不错的做法,当有中断或事件触发时再回到正常模式。
下面是一个包含__arm volatile声明的无限循环例子:
void infinite_loop(void) {
while (1)
__asm volatile("wfe");
}
注:wfe(Wait for Event)是给处理器一个提示,使处理器进入低功耗状态,直到事件或中断触发。 作者:亿道电子 https://www.bilibili.com/read/cv18803688/ 出处:bilibili
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。