为计算密集型应用选择最佳多核架构
从微小而且集成度非常高的片上系统,到大型数据中心,多核革命已经呈现出烽火燎原之势。那么,当你在设计自己的系统时,怎样才能把多核技术发挥到极致呢?另外需要注意的是,要在一个多核系统中把每一份计算能力都充分利用起来,并不是一件容易的事。
当今的多核处理器绝不仅仅是把多个处理器放进同一个芯片那么简单。领先的处理器提供商在其产品中植入了很多有用的特殊功能。例如,散列(hashing)、高速缓存(caching)、处理器间通信、中断管理和内存管理等。这些功能特性如果能够善加利用,就会让AMP架构高效率地运行起来,这就需要在软件上进行专门的优化。
我们知道,多核处理架构基本上可以分为对称多处理(SMP)和非对称多处理(AMP)两种。SMP架构的特征是同等地看待每一个处理器内核,不会特别指定哪个内核或者哪些内核去执行哪个特定的任务,完全由操作系统来平均地分配和协调内核之间的工作。AMP架构的特征是与SMP相反,不是同等地看待每一个处理器内核,而是把特定的任务分配给特定的内核来运行。这样做的好处是减少了重复性工作的相关数据切换,从而获得较高的运行效率。
例如,你可以拿到某一款典型的多核处理器--例如Freescale T4240,它具备12个多线程的内核,每个内核可供2个线程来调度共享。12个内核被分为3组,每4个内核为一组,共享2MB的Cache。相信你已经感觉到,这个系统还是挺复杂的。那么,你要让所有的内核都来运行单一一个OS Domain,并由它来调度所有的线程,还是把全部的计算能力划分成多个独立的OS Domain,各自承担不同的任务?哪一种方案会比较好呢?实际上,这必须根据应用类型来进行取舍。这个应用在并行处理时是否足够安全?它属于数据密集型应用吗?能否发挥共享Level 2 Cache所具备的优势,很可能是你做出判断时应该重点考虑的一个因素。
采用内置GPU的一组标准CPU,例如Intel Core i7,也是常用的硬件方案。这类系统可在4个内核中实现8个超线程,并且利用GPU来实现复杂的通用计算。对于典型的计算密集型应用来说,尽管开发这种CPU-GPU混合异构架构会增加系统的复杂度,但由此带来的性能提升仍然具有很大的吸引力,这让我们不厌其烦地进行尝试。
一旦理解了对应用如何进行分解,我们就有了选择何种方法和语言来开发这个应用的依据。如果采用多操作系统架构,不论是SMP还是AMP,通常都必须利用共享内存在不同OS Domain之间传递数据。虽然这不是仅有的方式,但却是常用方式--把带有一些数据的命令传递给某个OS Domain,然后由一个中断程序来做出相应的处理。但是,有什么API可以使用呢?
这里有好几种选择。多核联盟(Multicore Association)推出了MCAPI (Multicore Communication API)标准,如图1所示。这是专为multi-OS环境而设计的,可以建构在相关的技术规范和MRAPI (Multicore Resource API)之上。MRAPI作为一种资源,为多OS Domain之间提供了共享内存。

图1:基本的多核软件配置
对于这种架构,其他可供选择的架构是类似的自带专用API。无论你做出何种选择,都希望它是便于配置和维护的,这样才是最有利于长远发展的最佳方案。其中一个重要的影响因素是所选接口自身的资源消耗情况。系统中众多的内核通常都是共享内存的,其数据传输速度远远高于以太网。如果你把应用分割为在多个OS Domain中运行的原因之一是防止Cache Thrashing (多个线程在执行中读写同一个cache line,进入竞争状态),那么降低接口对资源的消耗占用就显得尤为必要。
对于SMP架构的编程来说,同样有好多种选择。在这种情况下,同一个 OS Domain内包含了多个相同架构的CPU.选择之一是采用操作系统内部可用的线程模式。在标准线程的OS环境中,通常有多种语言可供选择,例如:OpenMP、OpenCL和Cilk/Cilk++等。每种编程环境都有不同的语法,有些比较简单,但提供的控制水平有所差异。相对于典型的C语言语法,有些需要扩展性的改变。有些则并不支持所有的架构,所以你需要仔细检查所选的语言、编译器与操作系统是否可以很好地相互匹配和支持。
如果你有兴趣和能力将编程技艺发挥到极致,以便充分调动系统中的每一个“门”,可以考虑采用GPGPU (通用GPU编程,General Purpose GPU programming)。那么你需要注意到这些因素:语言、驱动程序和带宽。GPU是专门设计用来在像素级对图形进行操作,计算数据矢量,以及复杂的3D视图高帧速处理。因此,它们具备针对小数据集快速进行复杂计算的能力。
驱动程序对于GPGPU来说,绝不是无关紧要的琐事,必须从操作系统方面获得很好的支持。许多GPU提供商并不提供源代码,因为这属于他们知识产权的一部分。同时,他们通常也只是针对比较流行的操作系统才提供驱动程序。可能有些操作系统他们并不支持。
接下来你要考虑GPGPU语言的选择。OpenCL出自 Khronos标准。CUDA专用于Nvidia GPU。它们都采用了类似的方法来实现并行编程,而性能基准测试指标则有所不同,在不同硬件环境中的表现有些差异。由于OpenCL是一个开放标准,所以在大多数平台中都可以使用,它带有编译器,而且不需要修改代码就可以应用于CPU与GPU混合的系统。这显然是值得注意到的优势。
最后,远程GPU需要处理的数据量有多大,需要经过何种类型的总线,也会影响你的决定。越是数据密集型的应用,GPU就应该越靠近CPU。如果两者之间必须经过PCIe 总线,那就必须与外设分享带宽,这很可能会使性能受到较大的影响。如果GPU与CPU比较接近,由此造成的影响会相对降低。
特别是对于消费电子产品来说,如可穿戴设备、移动手持设备、数字成像设备、家用网关以及宽带接入等设备,面临的一个重要挑战就是以小体积、低功耗的运行环境来处理越来越大量的图像、声音甚至人体生理特征数据。为了针对这类运行环境在较短的时间内开发出优异的多核系统,开发平台如何选择就显得尤为关键。
风河公司最近针对最新版的VxWorks 7实时操作系统推出了面向各个行业的行业领域。这些Profile针对VxWorks 7扩充了一系列非常有价值的功能,帮助客户满足不断演变的市场和技术要求,从而抓住物联网所带来的新的市场发展机遇,其中就包括消费电子领域,专门针对小体积联网设备,如可穿戴设备、移动手持设备、数字成像设备、家用网关以及宽带接入设备等,提供快速启动、小体积、低功耗的运行环境,还特别强调对于GPU和2D/3D图形用户界面的支持能力,因而可以将多核处理器的优势最大限度地发挥出来。
总之,在这里并不存在点石成金的魔法棒。你必须深入研究每一种架构选择,包括硬件、软件、语言以及编译器,才能准确地评估每一部分对整体性能的影响,才能针对特定的算法进行最佳的优化。一劳永逸,这在高性能计算系统中是不存在的,至少到目前为止是如此!
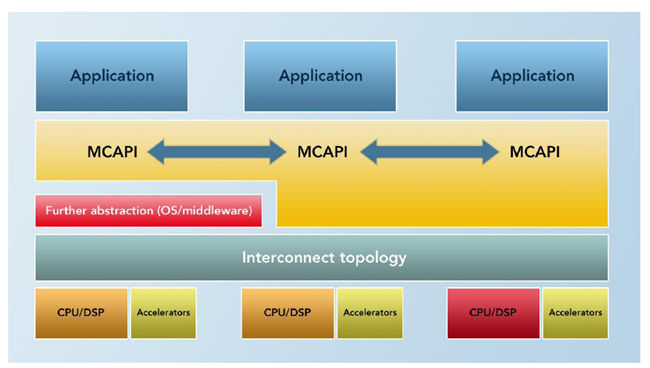
图2:MCAPI 是一个消息传递应用的接口,带有协议和语义规范,规定了其功能特性在任何应用实现中都必须遵循的行为规范。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。