引言:
随着科技的飞速发展,自动驾驶技术逐渐走进了人们的视野。在过去的几年里,特斯拉、Waymo和Uber等公司在自动驾驶领域的投入和研发引起了广泛关注。尽管自动驾驶技术有望改变交通行业,带来诸多便利,但在其广泛应用之前,我们还需要解决许多关键问题和挑战。本文将重点关注自动驾驶规控决策方面的问题和挑战,分析当前所面临的困境,并提出一些建设性的建议与解决方案。
我们首先将深入剖析目前在制定自动驾驶规控策略过程中所面临的问题和挑战,如模型泛化、安全性可靠性、计算效率等。最后,结合国内外的先进经验与实践,我们将提出一系列可能的解决方案,以期为自动驾驶技术的发展和普及提供有益的参考。
通过本文的阐述,我们希望能够提高人们对自动驾驶规控决策问题和挑战的认识,促使业界加强合作与沟通,共同应对未来自动驾驶技术带来的挑战,为人类社会带来更为安全、高效、可持续的交通出行方式。
01.
规控决策的重要性
规控决策在自动驾驶领域的重要性不容忽视,因为它直接影响到自动驾驶技术实际应用的成功与否。首先,规控决策对于确保自动驾驶车辆的安全性至关重要,通过合理的规控,可以有效地降低交通事故的发生率,确保人们的生命财产安全。其次,高效的规控决策有助于提升道路通行效率,缓解交通拥堵,降低能源消耗和尾气排放,从而为实现可持续交通发展做出贡献。
此外,规控决策还需要充分考虑法规合规性,这意味着自动驾驶技术的发展必须在法律框架内进行,以确保道路安全并维护公共利益。规范的规控决策将有助于引导自动驾驶技术朝着更加合规、安全的方向发展。同时,公众对自动驾驶技术的信任度也是衡量规控决策重要性的一个关键因素。通过透明、合理的规控,可以加强公众对自动驾驶技术的信任,为其更广泛的应用奠定基础。
综上所述,规控决策在自动驾驶领域具有举足轻重的地位。它关乎自动驾驶系统的安全性、效率、法规合规性以及公众接受度,为实现自动驾驶技术的成功实施与广泛应用提供关键支持。因此,深入研究规控决策问题,寻求有效的解决方案,是推动自动驾驶技术健康发展的重要任务。
问题与挑战:
在接下来的文章中,我们将深入探讨当前决策规划在自动驾驶领域所面临的问题与挑战,以及相关的潜在解决方向和趋势。我们将重点关注以下几个方面:
1.模型泛化
2.不确定性估计,数据质量和数量评估
3.多智能体与智能体-环境交互
4.安全与可靠性
5.计算效率
6.利用多模态融合进行最优决策
7.可解释性和可说明性
8.无需高清地图的自动驾驶
9.与现有基础设施的集成
在上一篇文章中,我们着重分析了模型泛化、不确定性估计以及数据质量和数量评估和多智能体与智能体-环境交互三个方面。本篇文章我们将继续分析决策规划在自动驾驶领域所面临的问题与挑战,着重于安全与可靠性、计算效率和利用多模态融合进行最优决策这三个方面。
02.
安全与可靠性
自动驾驶汽车必须能够在各种复杂且难以预测的场景中做出安全、可靠且值得信赖的决策[1]。这些决策必须在实时的情况下以及有限的信息条件下进行,并且必须考虑到道路上其他行驶主体的行为。这包括设计能够检测并从故障中恢复的系统,以及用于在各种场景中测试和验证系统性能的方法。
自动驾驶汽车在各种错综复杂且充满不确定性的场景中,必须具备做出安全、稳定且可信赖的决策能力。这意味着在实时动态环境中,自动驾驶汽车需要根据有限的信息条件迅速地做出恰当的决策,并且须充分考虑道路上其他行驶主体的行为,确保行车安全。为了达到这一目标,需要设计先进的算法和机制,以防止可能发生的事故。此外,为了不断提升自动驾驶系统的性能,研究人员需制定一套全面且严谨的测试和验证方法,以便在各种实际场景中检验系统性能。这包括在模拟环境中进行大量实验,以及在实际道路条件下进行实车测试,以确保自动驾驶汽车在不同情境下都能表现出卓越的性能。总之,自动驾驶汽车在面对复杂且难以预测的场景时,需要做出安全、可靠且值得信赖的决策。为实现这一目标,设计先进的算法和机制,以及制定严格的测试和验证方法,都是关键的研究方向。
子挑战
1.自动驾驶汽车决策的验证和确认:在复杂且不断变化的环境中,验证和确认基于深度学习模型的自动驾驶汽车决策行为可能颇具挑战性。由于深度学习模型的内在复杂性和不透明性,传统的测试和验证方法很可能无法充分保证自动驾驶汽车决策的安全性和可靠性。
2.受外部数据影响的安全性:自动驾驶汽车的性能和安全性很大程度上取决于其准确感知周围环境并处理外部数据的能力。然而,这些车辆可能会遭遇到不完整、不准确或错误的外部数据,这为算法的开发带来了极大的挑战。因此,如何开发具有鲁棒性和容错性的算法,使得自动驾驶汽车能够在各种异常情况下保持行驶安全,是当前研究的一个重要方向。
3.在云端外部模型决策存在的情况下的安全决策:在云端外部模型决策存在的情况下,如何确保自动驾驶汽车做出安全决策是非常重要的问题。云端模型可以为自动驾驶汽车提供实时的交通信息、道路状况等数据,帮助提升决策的准确性和效率。然而,在这一过程中,确保安全决策的实现面临着一些挑战。例如通信延迟与不稳定:当自动驾驶汽车依赖云端模型进行决策时,通信延迟和不稳定可能对决策的实时性产生影响;数据安全与隐私保护:在云端决策过程中,自动驾驶汽车需要与云端服务器进行数据交换,这就涉及到数据安全和隐私保护问题;鲁棒性与容错性:自动驾驶汽车在依赖云端模型进行决策时,必须具备应对云端服务中断或其他异常情况的能力。
潜在的解决方案和趋势
1.安全规则方法与深度学习技术的结合 [3]:这种结合策略旨在充分发挥两种方法各自的优势,为自动驾驶汽车提供更高的安全性能和决策能力。基于规则的方法具有较高的透明度和可解释性,使得研究人员和工程师能够更容易地理解和评估自动驾驶系统的决策过程。这有助于及时发现潜在的问题,提高系统的安全性和可靠性。而深度学习技术在处理复杂场景和动态环境方面具有很高的灵活性和适应性。通过结合基于规则的方法,自动驾驶汽车可以在遵循预设安全规则的前提下,灵活应对各种不确定和变化的道路条件,实现更加高效的决策过程。同时基于规则的方法可以为深度学习模型提供结构化的知识和先验约束,从而减少训练时间和提高决策效率。
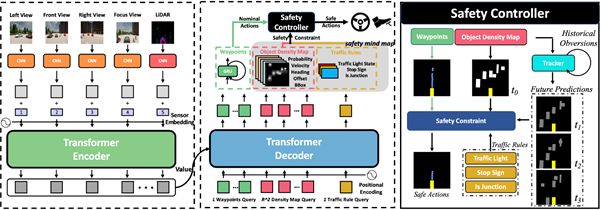
InterFuser[3]
2.模型检查和定理证明,验证决策方法的正确性:利用形式化方法,如模型检查和定理证明,即便在存在不确定性和错误的情况下,也可以确保自动驾驶汽车在各种场景下的正确行为和决策。通过模型检查和定理证明等形式化方法,可以对自动驾驶汽车决策系统的正确性进行严格验证。这有助于在系统部署前发现并修复潜在的安全漏洞,从而确保其在实际应用中的安全性和可靠性。
3.对抗性训练和异常检测:为提高深度学习模型的鲁棒性,可以采用诸如对抗性训练和异常检测的技术。对抗性训练是一种训练策略,通过在对抗性示例上训练模型,提高模型在面对攻击或干扰时的稳定性和鲁棒性。这种方法有助于确保自动驾驶汽车在遇到极端或异常情况时仍能做出正确的决策。异常检测技术可以帮助深度学习模型识别出意外输入,并根据预设的安全策略作出适当的响应。这包括在检测到异常情况时激活安全措施,如减速、刹车或转向,以确保车辆和乘客的安全。
03.
计算效率
自动驾驶汽车必须能够在实时、有限计算资源的条件下做出决策。为实现这一目标,我们需要开发能够在高效、迅速执行的同时,保持准确和可靠性的决策方法。
子挑战
1.模型复杂性导致训练和评估成本高昂:自动驾驶的深度学习模型通常具有大量参数,这可能导致它们在计算上需要高昂的训练和评估成本。自动驾驶系统需要处理多种复杂任务,如物体检测、路径规划、车辆控制等。因此,深度学习模型需要具备足够的表达能力来解决这些复杂问题。然而,随着模型复杂性的增加,训练所需的计算资源和时间成本也相应提高,这可能导致昂贵的硬件投资、电力消耗和人力成本。此外,训练过程可能需要大量的标注数据,而获取和标注这些数据也需要投入大量的人力和时间。评估复杂模型的性能可能同样需要耗费大量的计算资源和时间。为了确保自动驾驶汽车的安全性和可靠性,评估过程需要在多种场景和环境下进行,这可能包括成千上万个不同的测试用例。
2.实时处理与模型推断,因为自动驾驶汽车必须在毫秒级时间尺度上做出决策:自动驾驶系统需要实时处理来自各种传感器的数据,并在极短的时间内做出正确决策。这对于那些可能需要大量计算时间的深度学习模型来说,是一个巨大的挑战。自动驾驶汽车在行驶过程中需要实时识别和响应各种复杂的道路条件、交通状况以及其他道路用户。为确保安全性和准确性,系统需要在毫秒级时间尺度内完成数据处理和决策推断。深度学习模型在处理大量参数和计算复杂度时,可能需要较长时间进行推断。这可能导致自动驾驶汽车在实时场景中无法满足决策速度的要求。
3.便携式NPU设备中的计算和内存资源限制:自动驾驶系统通常部署在资源受限的平台上,如嵌入式系统或移动设备,这可能限制可用的计算能力和内存。在便携式NPU设备上运行自动驾驶系统,需要在有限的计算资源和内存空间内完成各种任务,如图像识别、路径规划和控制。这些限制可能导致模型性能下降或响应速度减缓,从而影响整体系统的可靠性和安全性。便携式NPU设备的计算能力相对于高性能GPU或服务器来说较低,可能无法满足复杂深度学习模型的实时推断需求。同时,便携式NPU设备的内存容量有限,可能无法容纳大型深度学习模型。此外,内存带宽和访问速度的限制也可能导致模型推断速度降低。
潜在的解决方案和趋势
1. 剪枝、量化和知识蒸馏:开发优化深度学习模型的技术,如剪枝、量化和知识蒸馏,以减小模型的尺寸并提高其效率。这些技术有助于减少运行模型所需的计算量,使模型更适合实时处理。剪枝方法通过消除模型中不重要或冗余的参数(例如权重或神经元),来减少模型的计算量和内存需求 [5]。常见的剪枝策略包括权重剪枝(移除较小权重)和结构化剪枝(移除整个神经元或通道)。这些策略可以在保持模型性能的同时,显著降低模型复杂度。量化方法通过减少表示模型参数所需的位数来降低模型尺寸。例如,将32位浮点数转换为16位或更低位数的整数。量化可以显著减小模型大小,降低内存占用和计算需求,同时仅引入较小的精度损失。知识蒸馏是一种模型压缩技术,通过将一个大型、复杂的“教师模型”所学到的知识传递给一个较小、简单的“学生模型”。这种方法通过让学生模型模拟教师模型的输出概率分布,从而使学生模型在保持较小尺寸的同时,获得与教师模型相近的性能 [6] [7]。
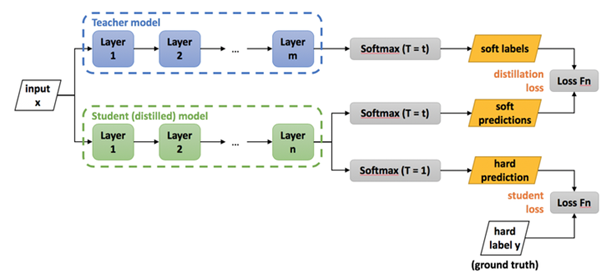
知识蒸馏通用框架 [8]
2. 硬件加速:专用硬件,如图形处理器(GPU)、张量处理器(TPU)和现场可编程逻辑门阵列(FPGA),为深度学习模型提供了强大的计算加速能力。借助这些专用硬件,模型能够更高效地运行,延迟大幅降低,从而更适应实时处理场景。GPU:图形处理器(GPU)具有大量的并行处理单元,可同时执行多个计算任务。这使得GPU非常适合处理深度学习模型中的矩阵和张量运算。相较于传统的中央处理器(CPU),GPU能显著提高模型的计算速度和效率。张量处理器(TPU)是专为深度学习应用设计的定制硬件加速器。TPU专注于执行深度学习模型中的矩阵和向量运算,通常比GPU在性能和能效方面更具优势。TPU可以进一步提升模型的实时推断 速度,从而满足自动驾驶汽车的实时决策需求。现场可编程逻辑门阵列(FPGA)是一种可重新配置的硬件平台,可以根据特定应用需求定制硬件逻辑。FPGA在深度学习领域的优势在于其灵活性和低功耗。通过为特定模型定制硬件逻辑,FPGA可以实现高效的计算性能,同时降低能耗。
3.稀疏表示和神经网络结构搜索:稀疏表示是一种高效的数据表示方法,它通过仅使用少量非零元素来精确地表示数据。这种方法可以有效地压缩输入数据并降低模型所需的计算量。对于深度学习模型来说,稀疏表示可以应用于权重矩阵、激活矩阵或其他相关参数,从而提高计算效率并降低内存需求。神经网络结构搜索(Neural Architecture Search,NAS)是一种自动化技术,用于寻找最佳的神经网络结构和超参数组合。NAS的目标是在维持模型性能的同时,找到具有更高计算效率的网络结构。这些结构可能包括不同的层数、神经元数量、激活函数等。通过利用NAS,研究人员可以为自动驾驶汽车设计更高效且计算需求更低的深度学习模型。
4.稀疏模型、压缩感知、降维(PCA/VAE):高效的数据管理技术有助于降低自动驾驶系统的计算和内存需求。例如,可以通过稀疏模型、压缩感知、降维(PCA/VAE)等多种方法预处理或压缩数据,以减少运行时所需的存储和计算量。通过构建稀疏模型,可以减少模型参数的数量,从而降低计算和存储需求。稀疏模型利用数据的稀疏性质,仅在关键参数上分配非零权重,以实现较低的计算复杂度和内存占用。压缩感知是一种数据采样技术,通过在少量样本上恢复信号或图像信息,以达到减少数据量的目的。这种方法可以有效地压缩数据,降低自动驾驶系统的计算和存储需求。降维技术则是通过将高维数据投影到低维空间,从而减少数据的维度和复杂性。主成分分析(PCA)和变分自编码器(VAE)是两种常用的降维方法,可以在保留数据中的关键信息的同时,降低其存储和计算需求。
04.
利用多模态融合进行最优决策
在自动驾驶领域中,实现多模态融合以制定最优决策是一项巨大的挑战。自动驾驶汽车必须具备根据来自各种传感器和信息源的数据进行决策的能力,这些传感器和信息源包括相机、激光雷达、雷达、GPS和地图等。然而,在实际应用中,这些不同的信息源可能会提供相互矛盾或不完整的信息,这进一步增加了确定最优决策的难度。
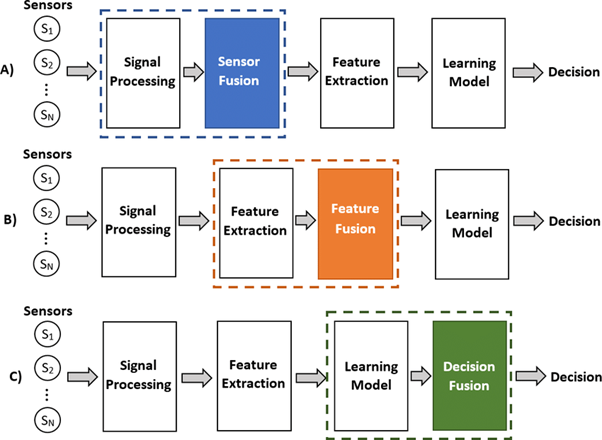
三种融合[9]
子挑战
1.数据预处理以最大化多模态融合中的信息信号:在自动驾驶领域,收集的数据需要经过预处理过程来消除噪声、异常值和不一致性,从而确保决策的准确性和可靠性。然而,针对不同类型的数据进行有效预处理是一项颇具挑战性的任务,因为各种数据类型可能需要应用不同的预处理技术
2.来自多个传感器的多模态数据集成:多模态数据集成主要涉及将来自不同传感器和信息源(如相机、激光雷达、雷达、GPS和地图)的数据高效地整合在一起,同时要尽量减少噪声、冗余和不一致性。
3.从具有不同特征的多模态输入数据中提取特征:不同模态(如视觉、雷达和激光雷达等)的数据具有各自独特的特点,因此识别能够帮助自动驾驶系统做出最优决策的关键特征至关重要,挑战在于识别可用于做出最优决策的最相关特征。
4.设计模型以最大化融合特征对最终决策的贡献:设计一个能够处理多模态数据的深度学习模型是一项复杂的任务。这样的模型不仅需要处理各种不同类型的数据,还需要以最优方式融合它们。此外,为了适应可能未在训练数据中出现的新场景,模型必须具备一定的泛化能力。
潜在的解决方案和趋势
1.数据增强、过滤和归一化:研究人员可以使用高级数据预处理技术,如数据增强、过滤和归一化,以消除噪声和异常值。这有助于确保数据质量高,并可用于最优决策。数据增强技术通过对原始数据进行变换和扩展,以产生具有多样性和代表性的新数据 [10]。这些变换包括旋转、缩放、翻转、平移等,能够增加模型的泛化能力,提高其在面对新场景时的性能。在自动驾驶领域,数据增强有助于模型更好地适应不同的道路条件、光线和天气状况。过滤技术可以去除数据中的噪声和异常值,使模型专注于学习有意义和关键的特征。在自动驾驶系统中,过滤可以通过传统的信号处理方法(如卡尔曼滤波器、中值滤波器等)或机器学习算法(如支持向量机、随机森林等)实现,从而提高模型的准确性和稳定性。归一化技术可以将来自不同传感器和数据源的数据统一到一个共同的尺度上,以消除数据分布的差异。这样可以简化模型的训练过程,加快收敛速度,并提高模型的可靠性。
2.使用融合模型进行数据集成:融合模型旨在将多种数据源的信息融合到一个统一的表示中,以便为自动驾驶系统提供更准确和可靠的决策依据。这些模型可以是基于机器学习的方法(如多层感知器、支持向量机等)或深度学习的方法(如卷积神经网络、循环神经网络等)。通过对多种传感器(如相机、激光雷达、雷达和GPS)的数据进行融合,这些模型可以捕捉到更丰富和更具辨识度的环境特征从而优化决策。
3.基于领域特定知识或设计的物理知识引导深度网络进行特征提取:在提取特征时,一种有效的方法是利用深度学习模型自动从多模态数据中挖掘相关特征。此外,研究人员还可以结合领域特定知识和物理原理来引导深度学习网络的特征提取过程,从而更精准地识别对最优决策具有关键作用的特征。这种方法有助于提高自动驾驶系统在处理复杂场景时的准确性和鲁棒性。
4.对于具有相似数据格式的输入采用并行子模型处理:为解决模型设计的挑战,可以考虑使用并行子模型来分别处理具有相似数据格式的多模态输入。这些子模型可以采用高级深度学习架构,如卷积神经网络(CNN)、循环神经网络(RNN)和注意力机制等。这些架构有助于更有效地处理和融合多模态数据,进而实现最优决策。此外,通过将这些子模型的输出进行适当整合,可以构建一个高效且鲁棒的自动驾驶系统。 05. 小结 本文主要讨论了自动驾驶领域的三个关键问题:安全与可靠性、计算效率以及利用多模态融合进行最优决策。在安全与可靠性方面,我们探讨了如何采用多种方法,如安全规则方法与深度学习技术的结合、模型检查和定理证明、对抗性训练和异常检测,来确保自动驾驶汽车在各种道路和环境条件下的安全行驶。在计算效率方面,我们强调了通过剪枝、量化、知识蒸馏等技术来降低计算需求,从而提高系统的实时性和效率。在利用多模态融合进行最优决策方面,我们关注了如何整合来自多种传感器和信息源的数据,实现高效的决策过程。
参考文献:
[1]M. Martínez-Díaz and F. Soriguera, “Autonomous vehicles: theoretical and practical challenges,” Transportation Research Procedia, vol. 33, pp. 275-282, 2018.
[2]K. Khalaf, “Autonomous Cars- Technologies & Safety,” 30 05 2017. [Online]。 Available: https://medium.com/@kylekhalaf/autonomous-cars-technologies-safety-8b87380af5e8. [Accessed 03 05 2023]。
[3]H. Shao, L. Wang, R. Chen, H. Li and Y. Liu, “InterFuser: Safety-Enhanced Autonomous Driving Using Interpretable Sensor Fusion Transformer,” in 2022 Conference on Robot Learning, Auckland, 2022.
[4]T. B. Brown and C. Olsson, “Introducing the Unrestricted Adversarial Examples Challenge,” Google, 13 09 2018. [Online]。 Available: https://ai.googleblog.com/2018/09/introducing-unrestricted-adversarial.html. [Accessed 03 05 2023]。
[5]J. I. Choi and Q. Tian, “Visual Saliency-Guided Channel Pruning for Deep Visual Detectors in Autonomous Driving,” arXiv preprint arXiv:2303.02512, 2023.
[6]Q. Lan and Q. Tiany, “Adaptive Instance Distillation for Object Detection in Autonomous Driving,” arXiv preprint arXiv:2201.11097, 2022.
[7]C. Sautier, G. Puy, S. Gidaris, A. Boulch, A. Bursuc and R. Marlet, “Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data,” in The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), Louisiana, 2022.
[8]03 07 2021. [Online]。 Available: https://zhuanlan.zhihu.com/p/384521670. [Accessed 03 05 2023]。
[9]E. Debie, R. Fernandez Rojas, J. Fidock, M. Barlow, K. Kasmarik, S. Anavatti, M. Garratt and H. A. Abbass, “Multimodal Fusion for Objective Assessment of Cognitive Workload: A Review,” IEEE Transactions on Cybernetics, vol. 51, pp. 1542-1555, 2021.
[10]S. Y. Feng, V. Gangal, J. Wei, S. Chandar, S. Vosoughi, T. Mitamura and E. Hovy, “A Survey of Data Augmentation Approaches for NLP,” in The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021), Thailand, 2021.
[11]21 04 2019. [Online]。 Available: https://zhuanlan.zhihu.com/p/61759947. [Accessed 03 05 2023]。
[12][Online]。 Available: https://blog.ml.cmu.edu/2020/08/31/6-interpretability/。
[13][Online]。 Available: https://www.engineering.com/story/systems-engineering-will-skyrocket-the-world-to-autonomous-vehicles.
[14][Online]。 Available: https://come-in.fr/les-avantages-de-la-5g-pour-les-entreprises/.









