随着大语言模型 (LLM) 和视觉基础模型 (VFM) 的出现,受益于大模型的多模态人工智能系统有潜力像人类一样全面感知现实世界、做出决策。在最近几个月里,LLM 已经在自动驾驶研究中引起了广泛关注。尽管 LLM 具有巨大潜力,但其在驾驶系统中的关键挑战、机遇和未来研究方向仍然缺乏文章对其详细阐明。
在本文中,腾讯地图、普渡大学、UIUC、弗吉尼亚大学的研究人员对这个领域进行了系统调研。该研究首先介绍了多模态大型语言模型 (MLLM) 的背景,使用 LLM 开发多模态模型的进展,以及对自动驾驶的历史进行回顾。然后,该研究概述了用于驾驶、交通和地图系统的现有 MLLM 工具,以及现有的数据集。该研究还总结了第一届 WACV 大语言和视觉模型自动驾驶研讨会 (LLVM-AD) 的相关工作,这是应用 LLM 在自动驾驶领域的首个研讨会。为了进一步推动这一领域的发展,该研究还讨论了关于如何在自动驾驶系统中应用 MLLM,以及需要由学术界和工业界共同解决的一些重要问题。

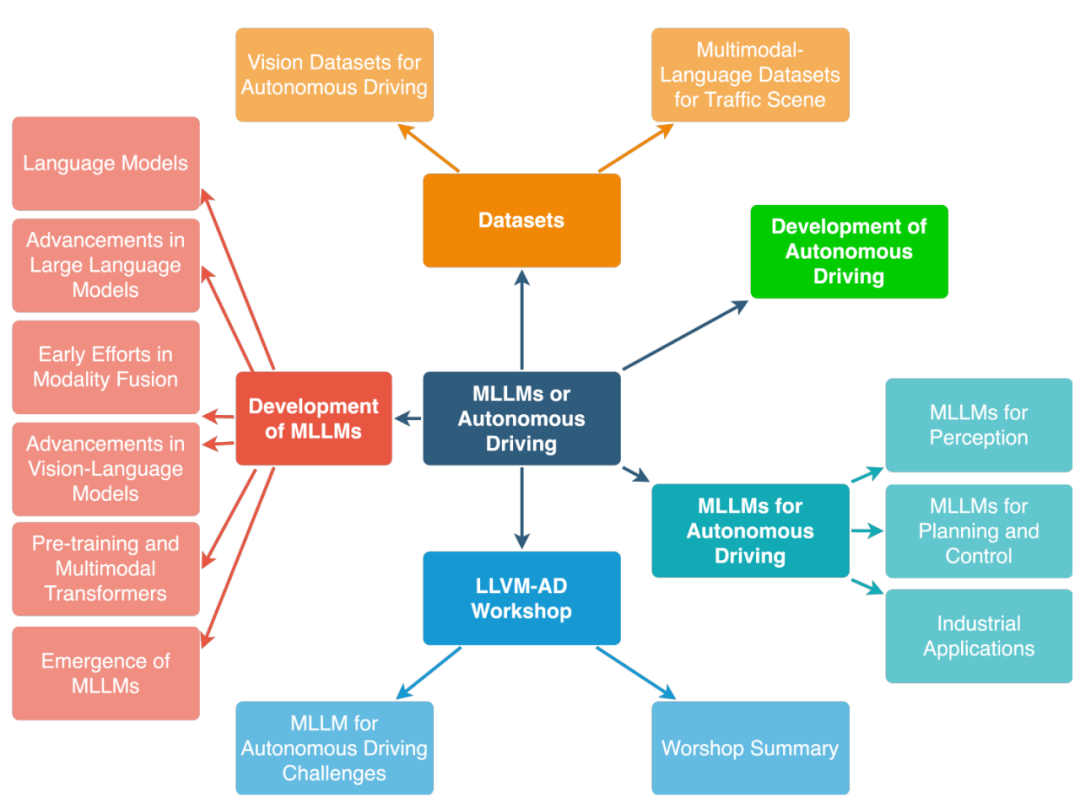
综述结构
多模态大语言模型(MLLM) 最近引起了广泛的关注,其将 LLM 的推理能力与图像、视频和音频数据相结合,通过多模态对齐使它们能够更高效地执行各种任务,包括图像分类、将文本与相应的视频对齐以及语音检测。此外,一些研究已经证明 LLM 可以处理机器人领域的简单任务。然而,MLLM 在自动驾驶领域的整合依然十分缓慢,我们不禁提出疑问,像 GPT-4、PaLM-2 和 LLaMA-2 这样的 LLM 是否有潜力改良现有的自动驾驶系统?
在本综述中,研究人员认为将 LLM 整合到自动驾驶领域可以在驾驶感知、运动规划、人车交互和运动控制方面带来显著的范式转变,提供以用户为中心、适应性更强、更可信的未来交通方案。在感知方面,LLM 可以利用工具学习 (Tool Learning) 调用外部 API 来访问实时的信息源,例如高精地图、交通报告和天气信息,从而使车辆更全面地理解周围环境。自动驾驶汽车可以在读取实时交通数据后,用 LLM 推理拥堵路线并建议替代路径以提高效率和安全驾驶。
对于运动规划和人车交互,LLM 可以促进以用户为中心的沟通,使乘客能够用日常语言表达他们的需求和偏好。在运动控制方面,LLM 首先使控制参数可以根据驾驶者的偏好进行定制,实现了驾驶体验的个性化。此外,LLM 还可以通过解释运动控制过程的每个步骤来提供对用户的透明化。该综述预计,在未来的 SAE L4-L5 级别的自动驾驶车辆中,乘客可以在驾驶时使用语言、手势甚至眼神来传达他们的请求,由 MLLM 通过集成视觉显示或语音响应来提供实时的车内和驾驶反馈。
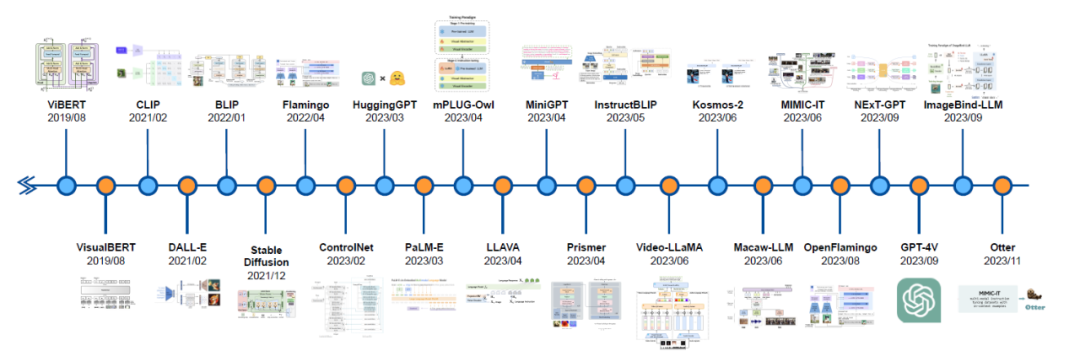
自动驾驶和多模态大语言模型的发展历程
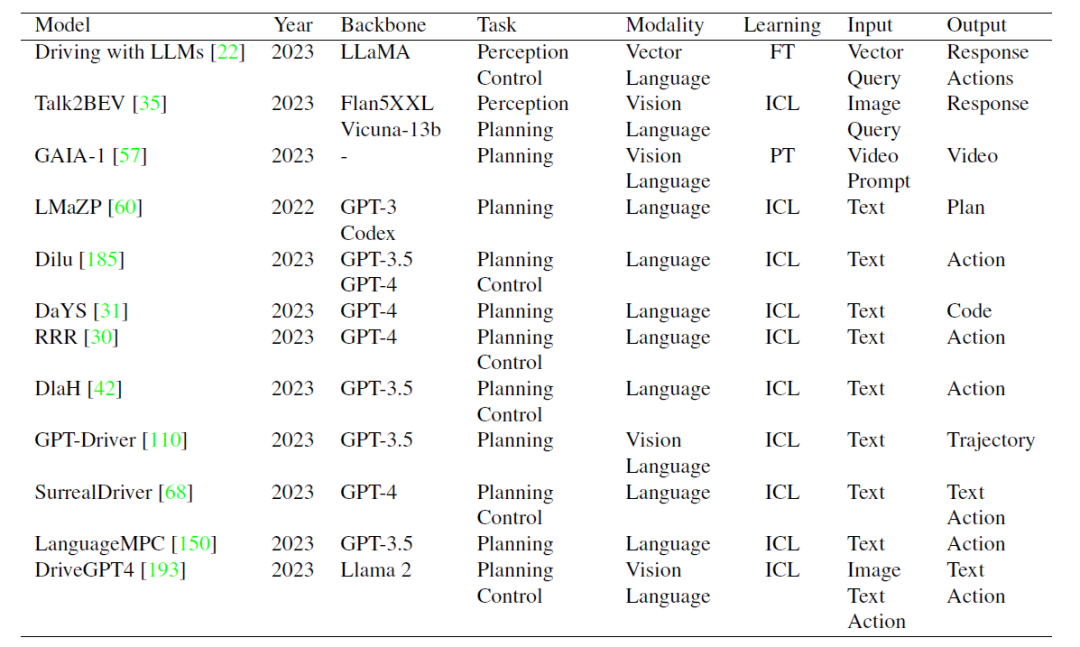
自动驾驶 MLLM 的研究总结:当前模型的 LLM 框架主要有 LLaMA、Llama 2、GPT-3.5、GPT-4、Flan5XXL、Vicuna-13b。FT、ICL 和 PT 在本表中指的是微调、上下文学习和预训练。文献链接可以参考 github repo: https://github.com/IrohXu/Awesome-Multimodal-LLM-Autonomous-Driving 为了搭建自动驾驶和 LLM 之间的桥梁,相关研究人员在 2024 年 IEEE/CVF 冬季计算机视觉应用会议 (WACV) 上组织了首届大语言和视觉模型自动驾驶研讨会(LLVM-AD)。该研讨会旨在增强学术研究人员和行业专业人士之间的合作,探讨在自动驾驶领域实施多模态大型语言模型的可能性和挑战。LLVM-AD 将进一步推动后续的开源实际交通语言理解数据集的发展。
首届 WACV 大型语言和视觉模型自动驾驶研讨会 (LLVM-AD) 共接受了九篇论文。一些论文围绕自动驾驶中的多模态大语言模型主题展开,重点关注了将 LLM 整合到用户 - 车辆交互、运动规划和车辆控制中。还有几篇论文探讨了 LLM 在自动驾驶车辆中类人交互和决策方面的新应用。例如,”Drive Like a Human” 和”Drive as You Speak” 探讨了 LLM 在复杂驾驶场景中解释和推理,模仿人类行为的框架。”Human-Centric Autonomous Systems With LLMs” 强调了以用户为中心设计 LLM 的重要性,利用 LLM 来解释用户命令。这种方法代表了向以人为中心的自主系统的重大转变。除了融合 LLM,研讨会还涵盖了部分基于纯视觉和数据处理的方法。此外,研讨会也提出了创新的数据处理和评估方法。例如,NuScenes-MQA 介绍了一种新的自动驾驶数据集注释方案。总的来说,这些论文展示了将语言模型和先进技术整合到自动驾驶中取得的进展,为更直观、高效和以人为中心的自动驾驶车辆铺平了道路。 针对未来的发展,该研究提出以下几点研究方向:
1、自动驾驶中多模态大语言模型的新数据集 尽管大语言模型在语言理解方面取得了成功,但将其应用于自动驾驶仍面临挑战。这是因为这些模型需要整合和理解来自不同模态的输入,如全景图像、三维点云和高精地图。目前的数据规模和质量的限制意味着现有数据集难以全面应对这些挑战。此外,从 NuScenes 等早期开源数据集注释的视觉语言数据集可能无法为驾驶场景中的视觉语言理解提供稳健的基准。因此,迫切需要新的、大规模的数据集,涵盖广泛的交通和驾驶场景,弥补之前数据集分布的长尾(不均衡)问题,以有效地测试和增强这些模型在自动驾驶应用中的性能。
2、自动驾驶中大语言模型的硬件支持 自动驾驶汽车中不同的功能对硬件的需求各不相同。在车辆内部使用 LLM 进行驾驶规划或参与车辆控制需要实时处理和低延迟以确保安全,这增加了计算需求并影响功耗。如果 LLM 部署在云端,数据交换的带宽将成为另一个关键的安全因素。相比之下,将 LLM 用于导航规划或分析与驾驶无关的命令(如车载音乐播放)不需要高查询量和实时性,使得远程服务成为可行的方案。未来,自动驾驶中的 LLM 可以通过知识蒸馏进行压缩,以减少计算需求和延迟,目前在这一领域仍然有很大发展空间。
3、使用大语言模型理解高精地图 高精地图在自动驾驶车辆技术中起着至关重要的作用,因为它们提供了有关车辆运行的物理环境的基本信息。高精地图中的语义地图层非常重要,因为它捕获了物理环境的意义和上下文信息。为了有效地将这些信息编码到下一代由 LLM 驱动的自动驾驶中,需要新的模型来映射这些多模态特征到语言空间。腾讯已经开发了基于主动学习的 THMA 高精地图 AI 自动标注系统,能够生产和标记数十万公里规模的高精地图。为了促进这一领域的发展,腾讯在 THMA 的基础上提出了 MAPLM 数据集,包含全景图像、三维激光雷达点云和基于上下文的高精地图注释,以及一个新的问答基准 MAPLM-QA。
4、人车交互中的大语言模型 人车交互以及理解人类的驾驶行为,在自动驾驶中也构成了一个重大挑战。人类驾驶员常常依赖非语言信号,例如减速让路或使用肢体动作与其他驾驶员或行人交流。这些非语言信号在道路上的交流中扮演着至关重要的角色。过去有许多涉及自动驾驶系统的事故是因为自动驾驶汽车的行为往往出乎其他驾驶员意料。未来,MLLM 能够整合来自各种来源的丰富上下文信息,并分析驾驶员的视线、手势和驾驶风格,以更好地理解这些社交信号并做出高效规划。通过估计其他驾驶员的社交信号,LLM 可以提高自动驾驶汽车的决策能力和整体安全性。
5、个性化自动驾驶 随着自动驾驶汽车的发展,一个重要的方面是考虑它们如何适应用户个人的驾驶偏好。越来越多的人认为,自动驾驶汽车应该模仿其用户的驾驶风格。为了实现这一点,自动驾驶系统需要学习并整合用户在各个方面的偏好,如导航、车辆维护和娱乐。LLM 的指令调整 (Instruction Tunning) 能力和上下文学习能力使其非常适合将用户偏好和驾驶历史信息整合到自动驾驶汽车中,从而提供个性化的驾驶体验。
总结 多年来,自动驾驶一直是人们关注的焦点,吸引着众多风险投资人。将 LLM 集成到自动驾驶汽车中会带来独特的挑战,但克服这些挑战将显着增强现有的自动驾驶系统。可以预见的是,LLM 支持的智能座舱具备理解驾驶场景和用户偏好的能力,并在车辆与乘员之间建立更深层次的信任。此外,部署 LLM 的自动驾驶系统将可以更好地应对道德困境,涉及权衡行人的安全与车辆乘员的安全,促进在复杂的驾驶场景中更可能符合道德的决策过程。本文集成了 WACV 2024 LLVM-AD 研讨会委员会成员的见解,旨在激励研究人员为开发由 LLM 技术支持的下一代自动驾驶汽车做出贡献。