芯片工程师展示了一个高度专业化的行业如何使用 NVIDIA NeMo 来定制大语言模型,以获得竞争优势。

10 月 31 日,NVIDIA发布的一篇研究论文描述了生成式 AI 如何助力芯片设计,后者是当今最复杂的工程工作之一。
这项工作展示了高度专业化领域的公司如何利用内部数据训练大语言模型,从而开发提高生产力的 AI 助手。
像半导体设计这样如此具有挑战性的工作并不多见。在显微镜下,NVIDIA H100 Tensor Core GPU(上图)这样最先进的芯片看起来就像一个精心规划的大都市,由数百亿个晶体管组成,把它们连接起来的线比人的头发丝还细 1 万倍。
多个工程团队进行协作,需要长达两年的时间才能构建出这样一个数字化超级大都市。
一些小组定义芯片的整体架构,一些小组负责各种超小型电路的设计与布局,还有一些小组负责测试工作。每项工作都需要采取专门的方法、软件程序和计算机语言。
大语言模型广阔的前景
该论文的主要作者、NVIDIA 研究总监 Mark Ren 表示:“我相信,随着时间的推移,大语言模型将全面助力所有流程。”
在同日举行的国际计算机辅助设计会议上,NVIDIA 首席科学家 Bill Dally 发表主题演讲并公布了这篇论文。这个年度盛会每年都会吸引数百名电子设计自动化(EDA)领域的工程师参加。
此次会议在旧金山举行。Dally 在会上表示:“这标志着在将大语言模型用于复杂的半导体设计方面迈出了重要一步。这项工作表明,即使高度专业化的领域也可以利用内部数据来训练极具价值的生成式 AI 模型。”
ChipNeMo 浮出水面
这篇论文详细介绍了 NVIDIA 工程师如何创建名为 ChipNeMo 的定制大语言模型,供内部使用。该模型使用公司内部数据进行训练并生成和优化软件,以更好地协助人类设计师。
Ren 在 EDA 领域从业超过 20 多年,他表示,从长远来看,工程师们希望生成式 AI 能够用于芯片设计的各个阶段,从而大幅提升整体生产力。
在针对可能的使用场景对 NVIDIA 工程师进行调研之后,研究团队一开始选择了三个场景:聊天机器人、代码生成器和分析工具。
初始用例
维护已知 bug 的更新描述需要耗费大量时间,而上述分析工具中的后者能够实现此类任务的自动化,并已得到广泛的采用。
一个聊天机器人原型可以回答有关 GPU 架构和设计的问题,并且已经帮助许多工程师在早期测试中快速找到技术文档。
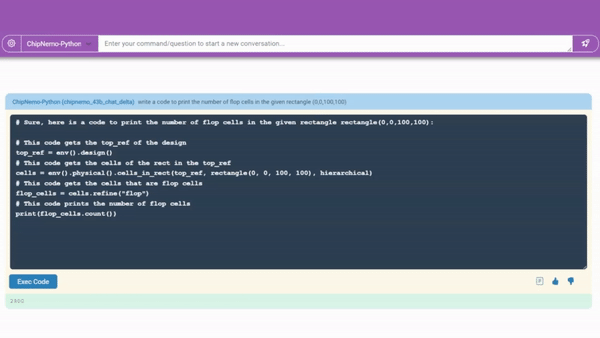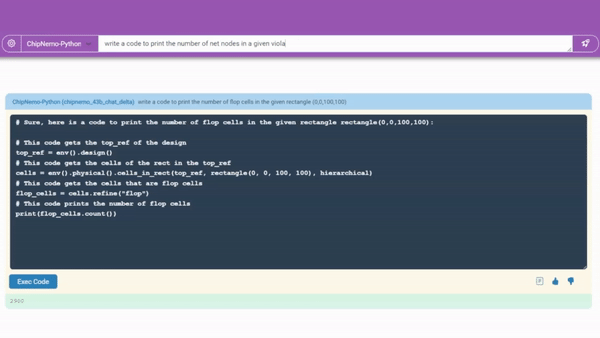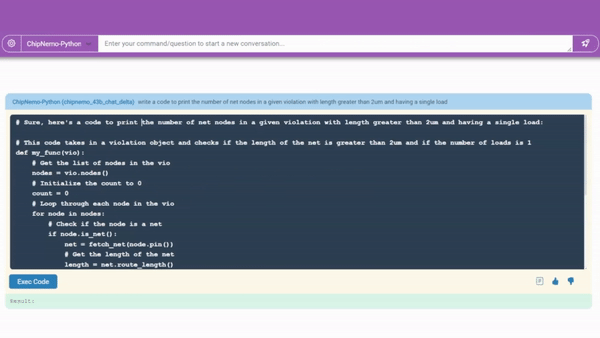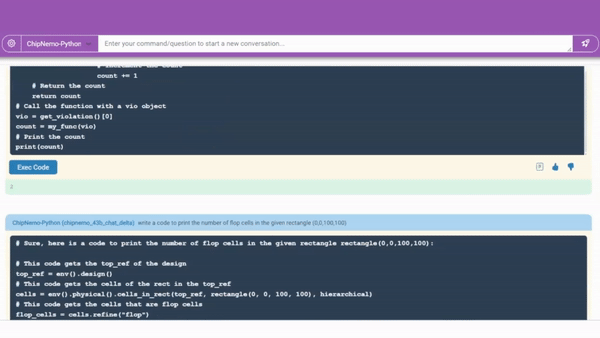
代码生成器将帮助设计者编写芯片设计软件。
一个正在开发中的代码生成器(如上图所演示)已经用两种芯片设计师专用语言创建了大约 10-20 行软件的片段。它将与现有工具集成,为工程师们提供一个方便的助手来进行设计。
使用 NVIDIA NeMo 定制 AI 模型
这篇论文主要关注该团队收集设计数据并使用这些数据创建专门的生成式 AI 模型,这个过程可以移植到任何行业。
作为起点,该团队选择了一个基础模型,并使用 NVIDIA NeMo 对其进行了定制。作为 NVIDIA AI Enterprise 软件平台的一部分,NVIDIA NeMo 是一个用于构建、定制和部署生成式 AI 模型的框架。定的 NeMo 模型具有 430 亿个参数,这衡量了它对模式的理解力。它使用超过一万亿个文本和软件中的 token、单词和符号进行了训练。
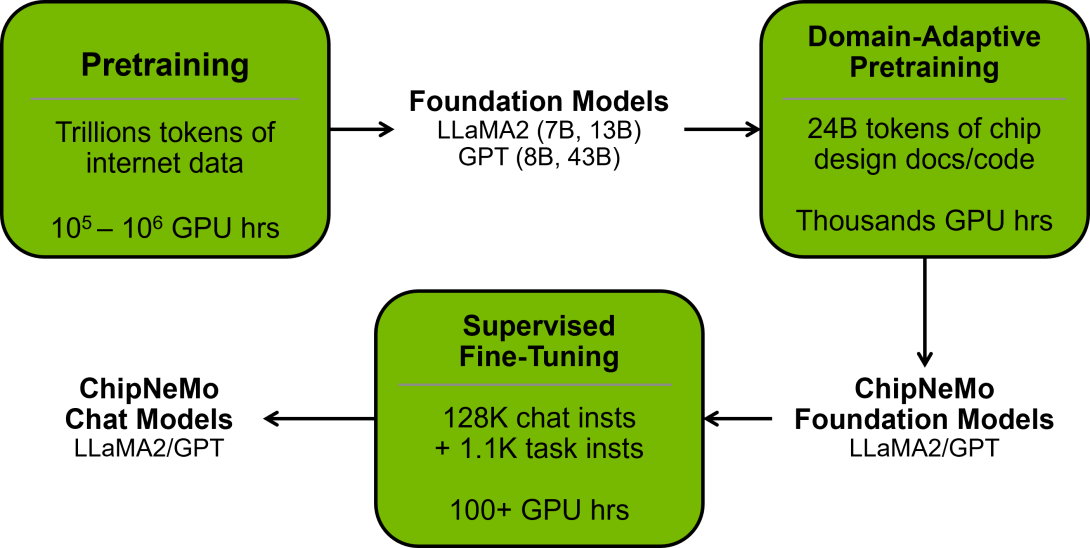
ChipNeMo 提供了一个技术团队如何用自己的数据改进预训练模型的示例。
然后,该团队在两轮训练中完善了该模型。第一轮使用了相当于大约 240 亿个 token 的内部设计数据,第二轮使用了约 13 万个对话和设计示例。
这项工作是半导体行业进行生成式 AI 概念研究和印证的几个例子之一, 这一趋势刚刚开始在实验室兴起。
分享经验
Ren 的团队学到的一个最重要的经验就是定制大语言模型的重要性。
在芯片设计任务中,只有 130 亿个参数的定制 ChipNeMo 模型的性能达到或超过了更大的通用大语言模型(例如包含 700 亿个参数的 LLaMA2)。在某些使用场景中,ChipNeMo 模型甚至好很多。
他补充道,在这一过程中,用户需要谨慎地确定他们收集什么数据以及如何清理数据以用于训练。
最后,Ren 建议用户及时了解可以加快和简化工作的最新工具。
NVIDIA Research 在全球各地拥有数百名科学家和工程师,专注于 AI、计算机图形学、计算机视觉、自动驾驶汽车、机器人学等领域。近期的其它半导体项目包括使用 AI 设计更小、更快的电路,以及优化大型模块的布局。
希望构建自己的定制大语言模型的企业现在可以从使用 GitHub 和 NVIDIA NGC 目录中的 NeMo 框架开始。