欧洲 RISC-V 定制内核人工智能专家 Semidynamics 公布了其运行 LlaMA-2 7B 参数大型语言模型 (LLM) 的 "一体化 "人工智能 IP 的张量单元效率数据。
Semidynamics 首席执行官 Roger Espasa 解释说:"传统的人工智能设计使用三个独立的计算元件:通过总线连接的 CPU、GPU(图形处理器单元)和 NPU(神经处理器单元)。这种传统架构需要 DMA 密集型编程,易出错、速度慢、耗能大,而且还必须集成三种不同的软件栈和架构。此外,NPU 是功能固定的硬件,无法适应未来尚未发明的人工智能算法。
"相比之下,Semidynamics 重新发明了人工智能架构,并将这三个元素集成到一个单一、可扩展的处理元件中。如图 1 所示,我们将一个 RISC-V 内核、一个处理矩阵乘法的张量单元(扮演 NPU 的角色)和一个处理类激活计算的矢量单元(扮演 GPU 的角色)整合到一个完全集成的一体化计算元件中。我们的新架构不需要 DMA,使用基于 ONNX 和 RISC-V 的单一软件栈,并在三个元件之间提供直接的零延迟连接。因此,性能更高、功耗更低、面积更大、编程环境更简单,从而降低了总体开发成本。此外,由于张量和矢量单元由灵活的 CPU 直接控制,我们可以部署任何现有或未来的人工智能算法,为客户的投资提供了极大的保护。"
图 1 传统人工智能架构与 Semidynamics 全新一体化解决方案的比较
大型语言模型(LLM)已成为人工智能应用的关键要素。LLM 在计算上以自我关注层为主,详见图 2。如图 2 所示,这些层由五个矩阵乘法(MatMul)、一个矩阵转置(Transpose)和一个 SoftMax 激活函数组成。在 Semidynamics 的 All-In-One 解决方案中,张量单元(TU)负责矩阵乘法,而矢量单元(VU)则能有效处理 Transpose 和 SoftMax。由于张量单元和矢量单元共享矢量寄存器,因此在很大程度上避免了昂贵的内存拷贝。因此,从 MatMul 层到激活层之间的数据传输是零延迟和零能耗,反之亦然。为了使 TU 和 VU 持续工作,必须高效地将权重和输入从内存获取到矢量寄存器中。为此,Semidynamics 的 Gazzillion™ Misses 技术提供了前所未有的数据移动能力。通过支持大量的飞行中缓存缺失,可以提前获取数据,从而提高资源利用率。此外,Semidynamics 的定制张量扩展包括新的矢量指令,该指令针对二维瓦片的获取和转置进行了优化,大大提高了张量处理能力。

图 2 LLM 中的注意层
Semidynamics 使用 Semidynamics 的 ONNX Run Time Execution Provider 在其 All-In-One 元件上运行了完整的 LlaMA-2 7B 参数模型(BF16 权重),并计算了模型中所有 MatMul 层的张量单元利用率。结果如图 3 所示。结果按 A 张量形状汇总和展示。LlaMA-2 共有 6 种不同的形状,如图 2 中 x 轴标签所示。可以看出,大多数形状的利用率都在 80% 以上,与其他架构形成鲜明对比。结果是在最具挑战性的条件下收集的,即批量为 1 和第一个标记计算。作为对这些数据的补充,图 4 显示了大矩阵尺寸的张量单元效率,以展示张量单元和 Gazzillion™ 技术的综合效率。图 4 标注了 A+B 矩阵大小。我们可以看到,随着矩阵 N、M、P 维元素数量的增加,以 MB 为单位的总大小很快就超过了任何可能的缓存/抓板。图表中值得注意的一点是,无论矩阵的总大小如何,性能都能稳定地略高于 70%。这一令人惊讶的结果归功于 Gazzillion 技术能够在主内存和张量单元之间维持较高的数据流速率。
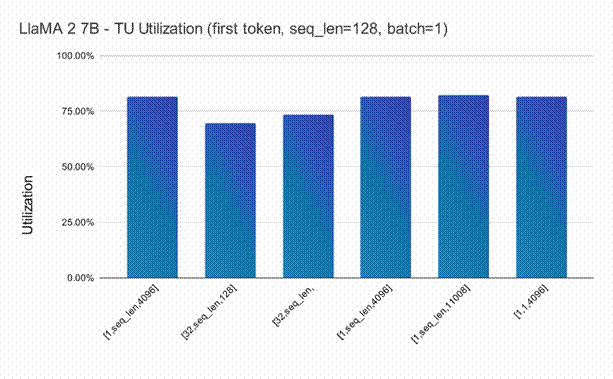
图 3 LlaMA-2 张量单元效率(按张量-A 形状排列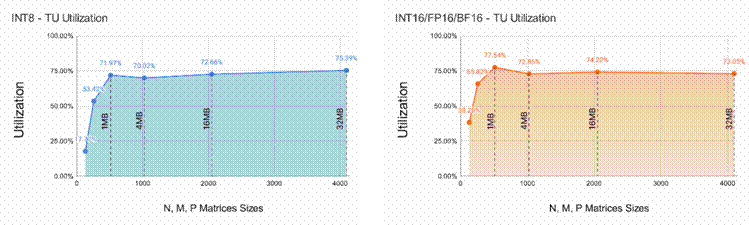
图 4 不同矩阵大小的 8 位矩阵(左侧)和 16 位矩阵(右侧)的张量单元利用率
Espasa 总结说:"我们的全新一体化人工智能 IP 不仅具有出色的人工智能性能,而且编程也更加简单,因为现在只需一个软件栈,而不是三个。开发人员可以使用他们已经熟悉的 RISC-V 栈,而且不必担心软件管理的本地 SRAM 或 DMA。此外,Semidynamics 还提供了针对 All-In-One AI IP 进行优化的 ONNX 运行时,使程序员能够轻松运行他们的 ML 模型。因此,我们的解决方案在程序员友好性和易于集成到新的 SOC 设计中方面向前迈进了一大步。我们使用 All-In-One 的客户将能够以更好、更易于编程的硅片形式将所有这些优势传递给他们的客户、开发人员和用户。
"此外,我们的 All-In-One 设计完全能够适应人工智能/ML 算法和工作负载的未来变化。这对于启动芯片项目的客户来说是一个巨大的风险保护,因为该项目在几年内都不会进入市场。当您的芯片进入批量生产时,您的人工智能 IP 仍然具有相关性,这是我们技术的独特优势。
Semidynamics www.semidynamics.com
Semidynamics® 成立于 2016 年,总部位于西班牙巴塞罗那,是唯一一家提供可完全定制的 RISC-V 处理器 IP 的公司,专注于针对机器学习和人工智能应用提供具有向量单元和张量单元的高带宽、高性能内核。该公司为私营企业,是 RISC-V 联盟的战略成员。
通过DeepL.com(免费版)翻译