2023年7月28日,在宁波前湾新区管委会联合浙江吉利控股集团主办、浙江省绿色智能汽车及零部件技术创新中心及盖世汽车承办的第三届前湾汽车产业创新高端论坛上,中国科学技术大学计算机科学技术学院副院长、教授 ,ACM 中国副主席、ACM中国 理事会常务理事张燕咏表示,Owl路测系统从“感、算、用”三方面进行部署,指导实际部署方案。Owl路测系统的“感”完成高精度点云地图生成,同时进行仿真建模,对激光雷达传感器等部署位置进行仿真模拟;Owl路测系统“算”基于差分进行激光数据压缩算法,基于数据特点,使用TDEnglie定义数据模型,完成数据存储,通过单显卡多模型调度策略,进行模型推理优化;Owl路测系统的“用”打通了与数字孪生可视化平台接口。

张燕咏|中国科学技术大学计算机科学技术学院副院长、教授 ,ACM 中国副主席、ACM中国 理事会常务理事
以下为演讲内容整理:
路侧感知的精度部署
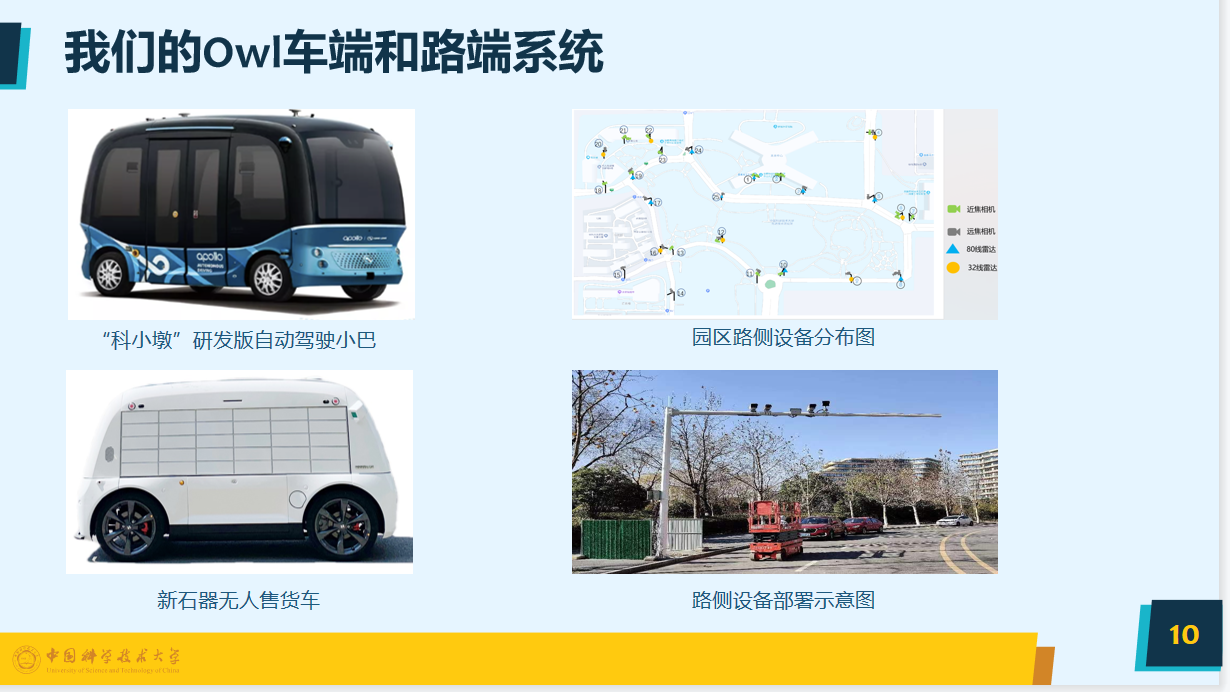
路侧的交通感知与车端的交通感知相比,可以对周围环境进行全面的感知和理解,比如车流监控、车流分析、园区监控等应用。车端感知的局限性分为遮挡严重、控制独立、鬼探头问题、视距受限;路侧感知有望实现全域感知和协同控制,可以做到提前预警和超视距感知。下图的路侧设备称为“猫头鹰”,是“感”、“算”、“用”为一体的路侧交通感知系统。
图源:演讲嘉宾材料
“感”的部分首先要做系统的传感器部署,比如在校园的25个路侧智能路杆上,部署了34个带有红外功能的远近焦摄像头,不仅可以感知车辆,还可以关注学生的动向。毫米波雷达会是未来部署的重点,可以生成园区内交通参与者的实时信息。
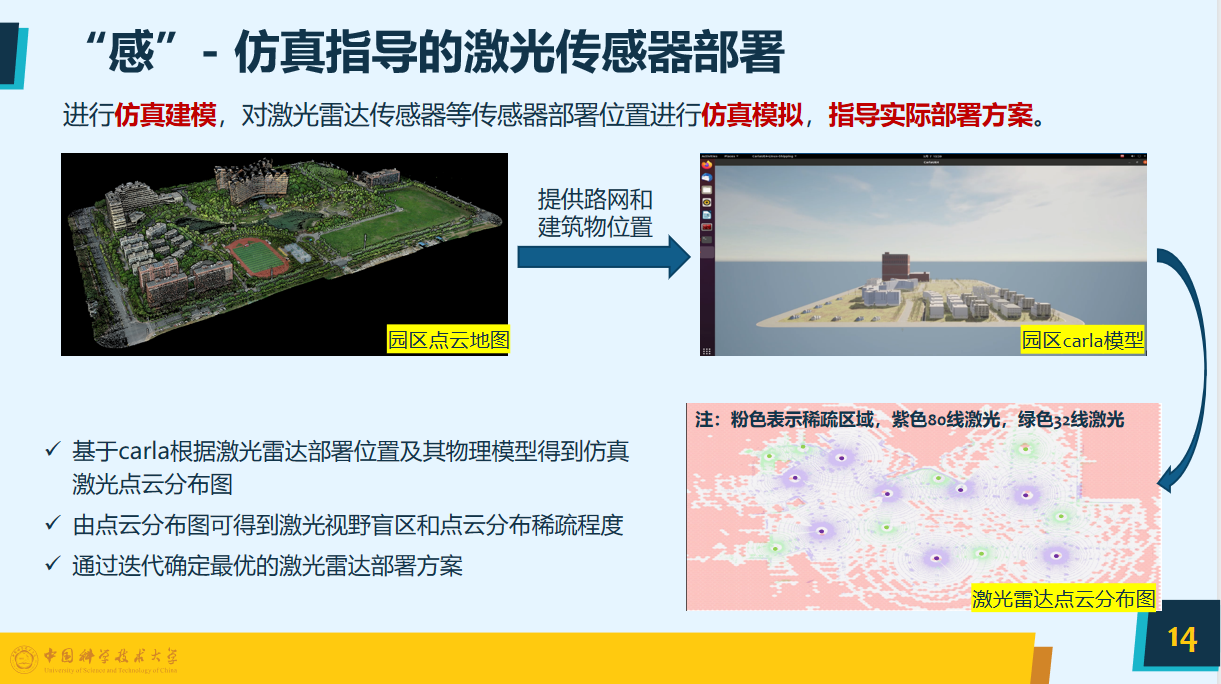
高精度点云地图的挑战在于激光雷达算法部署在路侧时如何滤除不稳定的特征,再结合无人机点云地图,可以形成一个园区较为精准的点云地图。下图是carla根据激光雷达部署位置及其物理模型,得到的仿真激光点云分布图,根据这个图可以对激光的位置进行调整,实现迭代与优化。
图源:演讲嘉宾材料
激光雷达部署完成,首先要进行感知工作,但会发现较多标定的工作难以开展,比如传统的传感器的标定距离较近,而路侧激光雷达之间位置转换距离较大,且静态背景点较为稀疏,特征提取也较为困难。在这样的情况下,用激光点云将目标提取,追踪其轨迹匹配的自动标定,因为激光雷达虽位置不同,但其轨迹是一致性的,所以有效缓解路侧点云稀疏带来的特征难以提取的问题。
摄像头与激光雷达同步的过程较为繁杂,采用自动化的标定方式是未来开发的重要技术点。像素坐标系和激光雷达坐标系可以投影到稠密的点云地图中,其投影的实际误差较小,也较为实用。结合目标检测算法实现目标级特征对齐,如果标定还无法对齐的情况,需要一辆车载GPS作为动态的标志物,这样会与目标进行对齐。
基于环境几何的单目视觉3D检测是我们的一个技术亮点,路测部署激光雷达,成本也会较高。采用摄像头进行3D的深度检测则会大幅度降低成本,但是难度较大,比如说观察下图右侧的图片,很难从2D图片中判断出车的距离。

图源:演讲嘉宾材料
此处使用几何建模透视之间的关系,已知摄像头的高度,可以算出图片中的目标的距离,也就是基于环境几何的单目视觉3D检测。其优点是基于几何关系,不需要深度学习的模型,计算速度较快,但其缺点是如果地面的起伏较大,精度不够会导致几何关系的不成立。所以在改进时要利用环境特征,可以计算出地面倾角并修正深度估计结果。我们的算法与灭点结合后,能在一百米的范围内达到0.5米的误差,此模式在业界也较为领先。
多模态融合定义数据模型多样化
只采用摄像头显然是不够的,路侧应该基于多模态的融合,古语云:“尺有所短寸有所长”,毫米波雷达可以捕捉动态信息,比如物体的速度,距离较远的目标容易形成漏检,如果将摄像头和毫米波雷达融合,有望得到类激光雷达性能的传感器。
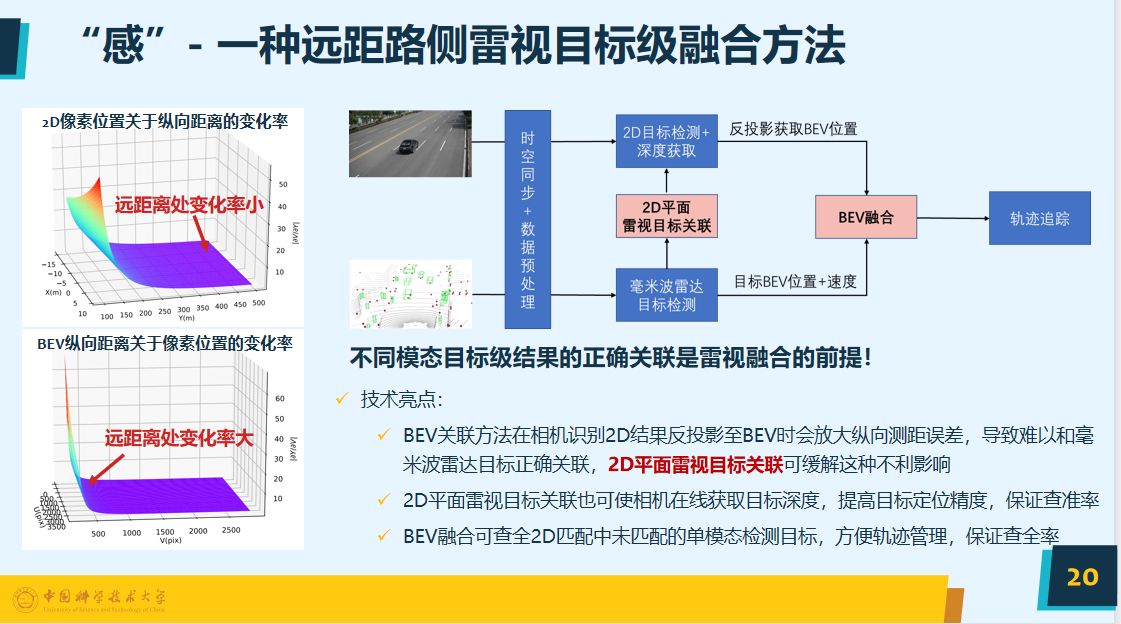
我们采用多传感器后融合技术,用以处理视觉和毫米波雷达信息,将其目标值的结果融合。从下图可以看出俯视的平面远距离其变化率较大,所以在2D平面上进行融合,再将其换到俯视的平面上,会大幅度提高目标定位精度。
图源:演讲嘉宾材料
基于BEV平面的模型是目前较为主流的趋势,把不同传感器的信息通过此模型进行融合,但一般都部署在车端,路端的部署难度较大,一是缺少数据,算力消耗较大;二是BEV模型降采样严重,现有版本只支持短距离50米之内,这个距离对路侧显然是不够的,所以需要进行设计革新。
数据量巨大会对通信和存储的基础设施造成挑战,所以要进行编码。因为路侧的环境变化较小,可以用简单的差分方法,也就是将动态的环境信息摘除,这样采样率可以达到2.5%,如果再加上比较常用的量化,又会进一步降低采样率,从而达到约6%。这样可以把这套基于路侧较为实用的编码方式用在激光雷达、毫米波雷达和视觉图片上。
数据存储中的非结构化数据面对事件查询时,存在较大的难题,基于数据特点,使用TDEngine,定义数据模型,构建时空索引,对数据进行高效存储和查询。
在数据的收集方面,假设路段上有100辆车,所有的数据都上传到云端,就需要通过实时计算,给这100辆车都规划好其路径,如果有一辆车稍有变化,就需要重新计算和规划路径,所以对算力的要求较高。目前我们也在基于深度学习模型,去研究如何通过并行化的手段来达到实时的处理。
“用”方面打通与数字孪生可视化平台接口,在孪生世界中复现出交通道路情况,可以实时分析和优化路网的流量,提高交通系统的效率。下图展示了在这个过程中用到的实验平台,比如轻量小机器人群、小猬智能车、无人小巴等。

图源:演讲嘉宾材料
未来研究目标与方向
首先计划将园区的路侧数据集开源,因为这方面的数据较为稀缺,所以希望开源之后,能有更多人一起来协同攻关。其次是BEV-CLIP多模态自动驾驶大模型,在人工智能、大模型的浪潮的席卷下,当模型参数量足够大时,其范式性和准确性都会极大提高,但chatgpt大模型主要是语言信息,也就是文本信息,我们想面向自动驾驶领域做一个多模态的大模型。比如图片、点云等信息,这些信息不一定是对齐的,放到大模型中预训练,希望可以较好的解决其范式性以及长尾的问题。但在这个过程中的难题较多,除了大模型的并行训练、数据的收集与融合,还需要高精度自动标注和。
城市交通场景较为拥堵,路测设备能否进行感知也是需要解决的难题之一。2D图像平面遮挡较严重容易引起跟踪轨迹的中断,在BEV下结合轨迹预测任务可解决短时遮挡问题。还可以将检测和追踪任务使用端到端网络实现,即融合时序特征,使用交叉注意力机制对历史特征进行查询,以解决当前帧目标被遮挡特征缺失无法有效预测的问题。
路端雷视融合也是我们研究的方向,视觉的密度比较大,毫米波雷达可以提供3D和距离等信息,如果将这两个相融合,在成本降低的同时也能达到较好的效果。
我们还有前融合的方案,可以更大程度的利用这两种传感器的原始数据,目前已经有了初步的模型设计,但未来需要大规模的验证。