沿着材料工程前沿的新研究有望为计算设备带来真正的性能改进。以马库斯·海伦布兰德德等人为首的研究小组和剑桥大学的相关人员认为,一种基于氧化铪层的新材料,通过电压变化的钡尖峰隧穿,融合了和处理绑定材料的特性。这意味着这些设备可以用于数据存储,提供 10 到 100 倍于现有存储介质的密度,或者它可以被用作处理单元。
本文引用地址:这项研究发表在《科学进展》杂志上,为我们指明了一条道路,通过这条道路,我们的计算设备可能会获得更高的密度、性能和能源效率。事实上,基于该技术(称为连续范围)的典型 USB 记忆棒可以容纳比我们目前使用的 USB 记忆棒多 10 到 100 倍的信息。
正如 JEDEC 指出的那样,RAM 的密度每四年翻一番,RAM 制造商需要数十年的时间才能最终达到与该技术今天所显示的相同的密度水平。
该设备也是神经形态计算隧道中的一盏灯。就像我们大脑中的神经元一样,这种材料(称为电阻开关)有望同时用作存储和处理介质。这在我们当前的半导体技术中根本不会发生:存储单元所需的晶体管和材料设计安排与处理单元所需的晶体管和材料设计安排非常不同(主要是在耐用性方面,例如不遭受性能下降的能力),目前还没有办法将它们合并。
这种无法合并它们的情况意味着信息必须在处理系统及其各种缓存(当考虑现代 CPU 时)以及其外部内存池之间持续流动。在计算中,这被称为冯诺依曼瓶颈,这意味着具有独立内存和处理能力的系统将从根本上受到它们之间的带宽(通常称为总线)的限制。这就是为什么所有半导体设计公司(从 Intel 到 AMD、Nvidia 等)都设计专用硬件来加速这种信息交换,例如 Infinity Fabric 和 NVLink。
问题在于这种信息交换会产生能源成本,而这种能源成本目前限制了可实现性能的上限。当能量循环时,也会存在固有的损耗,这会导致功耗增加(当前硬件设计的硬性限制,也是半导体设计中日益重要的优先事项)以及热量的增加——这是另一个硬性限制,导致越来越奇特的冷却解决方案的开发,试图让摩尔定律暂时失效。当然,还有可持续性因素:预计在不久的将来,计算将消耗全球能源需求的 30%。
「在很大程度上,能源需求的爆炸式增长是由于当前计算机存储技术的缺陷造成的,」剑桥大学材料科学与冶金系的第一作者马库斯·海伦布兰德博士说。「在传统计算中,一侧有内存,另一侧有处理,数据在两者之间重新洗牌,这既需要能量又需要时间。」
正如您可能想象的那样,合并内存和处理的好处是相当惊人的。虽然传统只能具有两种状态(一或零),但电阻开关存储器件可以通过一系列状态改变其电阻。这使得它能够在更多的电压下运行,从而可以编码更多的信息。在足够高的水平上,这与 NAND 领域中发生的过程大致相同,每个单元位数的增加对应于存储单元设计中解锁的更多可能电压状态。
区分处理和存储的一种方法是,处理意味着信息正在按照其切换周期请求的速度进行写入和重写(添加或减去、转换或重组)。存储意味着信息需要在较长时间内保持静态——例如,可能因为它是 Windows 或 Linux 内核的一部分。
为了构建这些突触设备,正如论文所提到的,研究团队必须找到一种方法来解决材料工程瓶颈,即均匀性问题。由于氧化铪 (HfO2) 不具有任何原子级结构,因此决定或破坏其绝缘性能的铪和氧原子会随机沉积。这限制了它在传导电子(电力)方面的应用;原子结构越有序,造成的阻力就越小,速度和效率就越高。但研究小组发现,在非结构化氧化铪薄膜中沉积钡(Ba)会产生高度有序的钡桥(或尖峰)。而且由于它们的原子结构更加结构化,这些桥可以更好地允许电子流动。
海伦布兰德说:「这些材料真正令人兴奋的是它们可以像大脑中的突触一样工作:它们可以在同一个地方存储和处理信息,就像我们的大脑一样,这使得它们在快速发展的人工智能和机器学习领域非常有前途。」
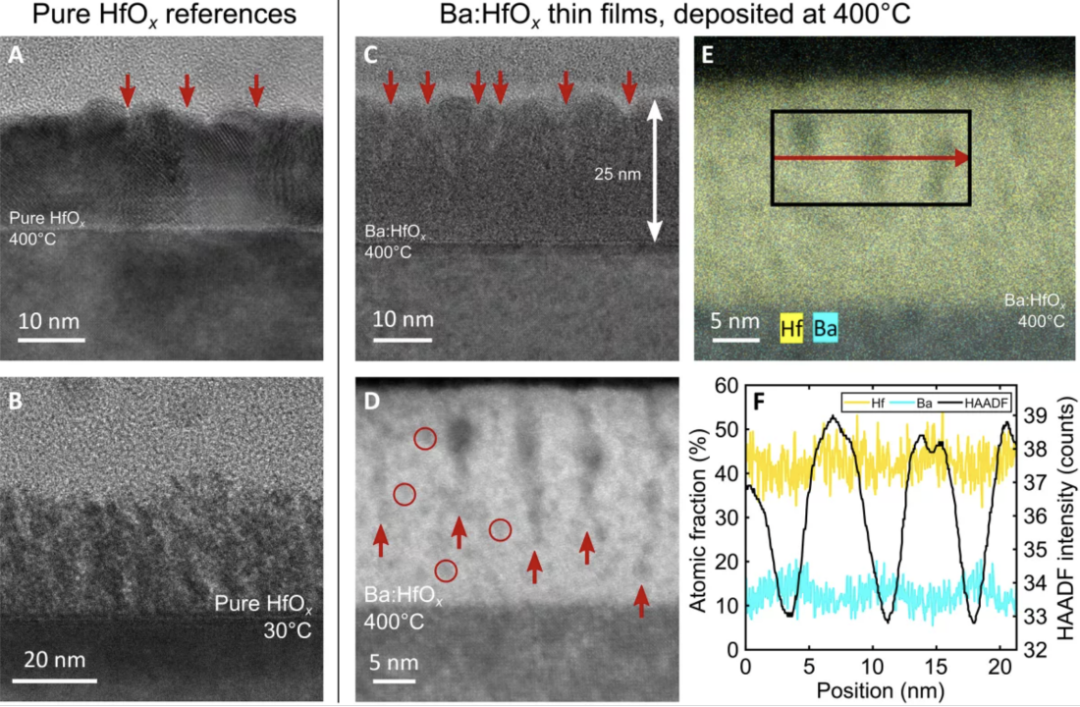
这些照片是用透射电子显微镜 (TEM) 拍摄的,展示了当动态变化的钡尖峰穿过氧化铪沉积时,氧化铪的沉积顺序增加(无序和自然沉积,如图 A 所示)。(来源:剑桥大学/Markus Hellbrand 等人)
但当研究团队发现他们可以动态改变钡尖峰的高度,从而可以对其电导率进行细粒度控制时,乐趣就开始了。他们发现尖峰可以以约 20 纳秒的速率提供开关能力,这意味着它们可以在该窗口内改变其电压状态(从而保存不同的信息)。他们发现开关耐久性 >10^4 个周期,内存窗口 >10。这意味着虽然该材料速度很快,但它目前可以承受的最大电压状态变化次数约为 10,000 次循环。
它相当于 MLC(多级单元)技术的耐用性,这自然会限制其应用,使用这种材料作为处理介质(其中电压状态快速变化,以保存计算及其中间结果的存储)。
粗略地计算一下,大约 20 ns 的切换导致工作频率为 50 MHz(转换为每纳秒的周期数)。当系统全速处理不同状态时(例如,作为 GPU 或 CPU 工作),这意味着钡桥将在 0,002 秒左右停止运行(达到其耐用极限)。对于处理单元来说,它的性能似乎不够。
就是存储容量「密度高 10 到 100 倍」的 USB 记忆棒的用武之地。这些突触设备可以访问比当今最宽敞的 USB 记忆棒中最密集的 NAND 技术更多的中间电压状态,是其 10 或 100 倍。
在钡电桥的耐用性和开关速度方面还有一些工作要做,但看起来该设计已经是一个诱人的概念证明。更好的是,半导体行业已经使用氧化铪,因此需要克服的工具和物流噩梦更少。
但这里有一个特别巧妙的产品可能性:想象一下,该技术已经改进到可以制造并可用于设计 AMD 或 Nvidia GPU(目前其运行频率约为 2 GHz)。在某个世界中,显卡具有重置出厂状态,完全作为内存运行(现在想象一下具有 10 TB 容量的显卡,与我们假设的 USB 记忆棒相同)。
想象一下这样一个世界:AMD 和 Nvidia 提供的本质上是可编程 GPU,基于连续范围的 GPU 芯片在最大存储能力方面进行了产品堆叠(记住比当前 USB 密度高 10 到 100)。如果您是一位人工智能爱好者,试图构建自己的大型语言模型 (LLM),您可以对 GPU 进行编程,以便适量的合成设备(这些神经形态晶体管)运行处理功能—随着复杂性的增加,我们无法确定模型最终会产生多少万亿个参数,因此内存将变得越来越重要。
能够决定图形卡中的晶体管是完全用作内存还是完全用作养眼放大器以将图形设置提高到 11 个,这完全取决于最终用户;从休闲游戏玩家到高性能计算 (HPC) 安装人员。即使这意味着我们芯片部件的寿命会明显缩短。
总之,这是一项新技术,不要操之过急,与所有技术一样,当它准备就绪时,它就会到来。