单片机(MCU)如何才能不死机之对齐访问(Aligned Access)
从一个结构体说起。如下,在 STM32F0 的程序中,我们定义了一个结构体My_Struct ,那么这个结构体占用多少内存呢?
struct Struct_Def {
uint8_t Var_B;
uint16_t Var_W0;
uint16_t Var_W1;
uint32_t Var_DW;
};
struct Struct_Def My_Struct;
int main(void)
{
My_Struct.Var_B = 0x01;
My_Struct.Var_W0 = 0x0203;
My_Struct.Var_W1 = 0x0405;
My_Struct.Var_DW = 0x06070809;
while(1);
}
我们粗略一算,1 + 2 + 2 + 4 = 9 Bytes 。
下载到芯片,观察一下变量,似乎没错。

如果有更进一步的好奇心,我们来到内存中实际看一下,可能会有出乎意料的发现:
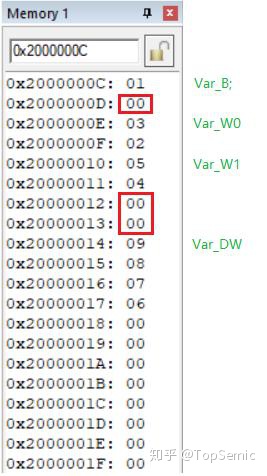
编译器在 Var_B 之后插入了一个字节,在 Var_W1 之后插入了两个字节。这个结构体在内存中实际占用了 1 + 1 + 2 + 2 + 2 + 4 = 12 Bytes 。
为什么会这样呢?这是 ARM Cortex M0 体系决定的,它只支持对齐访问 ( Aligned Access )。比如我们访问一个 4 字节 (Double Word) 型的变量时,如果这个变量的起始地址是能被 4 整除的话,我们说这种访问是双字节对齐的。如果访问一个 2 字节 ( Word ) 变量,当起始地址能被 2 整除时是对齐的。访问字节 ( Byte ) 型变量,总是对齐的。
那么如果进行了非对齐访问呢?那就会产生一个严重错误 ( HardFault ) !!!
大家看一下例子中的这一个赋值语句:
My_Struct.Var_DW = 0x06070809;
它是一个 4 字节 ( Double Word ) 型的变量赋值。Var_DW 这个成员,如果按照在结构体中的顺序,应该紧随 Var_W1 之后,分配在 0x20000012,但是这个地址是不能被 4 整除的,所以编译器在填充了 2 个字节 0 之后,把 Var_DW 的起始地址分配在了 0x20000014 。

到这里大家肯定会有一个疑问,这样岂不是很浪费 RAM 吗?RAM 又是相对来说价格比较高的。特别是在结构体比较多的情况下,大量的 RAM 白白浪费了!
还好,在这里我们可以用到伪指令 #pragma pack 了。
如下例所示,#pragma pack(1) 将会使结构体中的变量一个字节紧挨着一个字节在内存中分配,而不再考虑是否对齐的问题。可以看到结构体占用从 0x2000000C 到 0x20000014 的9个字节 RAM空间。
#pragma pack(1)
struct Struct_Def {
uint8_t Var_B;
uint16_t Var_W0;
uint16_t Var_W1;
uint32_t Var_DW;
};
struct Struct_Def My_Struct;
#pragma pack()
那么问题来了,当我们读写地址非对齐的变量时,不就会产生 HardFault 吗?
在这里,编译器采取了曲线救国的方针。大家看下面赋值语句对应的汇编部分就会看到,它用 4 个STRB 指令(单字节操作,无论任何地址都是对齐操作), 代替了 1 个 STR 指令 ( 4 字节操作 )。如此,牺牲了一些效率,但是节省了内存空间。
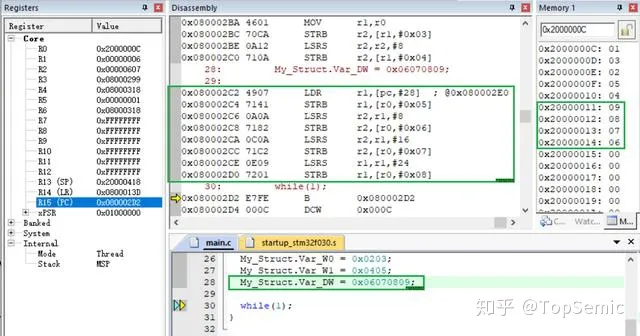
这种用法节省了 RAM,但是带来了一种比较隐蔽的错误。 尤其是当我们用指针方式访问这些变量时,编译器无法发现错误,而且只有当语句实际执行时才会引起问题。所以在使用指针式要特别注意,指针所指向的地址,是否和指针类型所需要的地址对齐方式吻合。
以上面的 RAM 分配方式为例,非对齐访问时会导致 MCU 进入 HardFault 。
volatile uint32_t Test_Var;
Test_Var = *(uint8_t *)(&My_Struct.Var_B); // 这句是可以正确执行的
Test_Var = *(uint16_t *)(&My_Struct.Var_W0); // 非对齐访问,进入 HardFault
Test_Var = *(uint32_t *)(&My_Struct.Var_DW); // 非对齐访问,进入 HardFault
对于变量的定义,我们还可以用下面的伪指令把变量以 n 字节对齐:
__align(n)
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。