World Model与端到端,自动驾驶的革命性时刻到来了么?
World Model在自动驾驶领域内的应用,来自论文《World Models for Autonomous Driving: An Initial Survey》。World Model主要作用有两点,一是低成本生成海量接近真实的包含Corner Case多样化训练视频数据,二是采用强化学习的方法来达到端到端的效果,从视频直接输出驾驶决策。
自2015年就开始了World Model的研究,基本定型于2018年,2023年底开始火爆全网。基础理论主要来自谷歌,少量来自META。
特斯拉和Wayve都在去年提出了World model,这是端到端必备条件。端到端需要海量的包含尽量多的Corner Case的数据,目前智能驾驶数据库价值极低,能够公开得到的数据可以分为两种:
一种是简单工况下的正常行驶,千篇一律,不具备多样性,这种数据大概能占到公开数据的90%,有效性大概只有万分之一到十万分之一,特斯拉影子模式就是如此,马斯克承认这种数据价值很低,只有万分之一,实际更低。
再有一种就是事故数据,也就是错误示范。用这样的数据做端到端的训练,要么只能适应非常有限的工况,要么会出错。端到端是完全彻底的黑盒子,无法解释,不具备确定性,只具备相关性,这就需要数据尽量多样化、高质量,这样训练结果可能会好一点。
端到端首先要解决数据的问题,想要靠外界采集数据是不可能的,成本极高,效率极低,且欠缺多样化。还有就是缺乏交互,自车与其他车辆的交互,与环境的交互,这需要昂贵的人工标注才能完成,因此就引入了World Model,人工制造海量多样化数据,且无需人工标注,成本很低。
ChatGPT给了自动驾驶业界很大的启发,它采用无需标注的低成本的海量数据训练,人机互动,回答问题。自动驾驶仿照这种人机互动,输入环境提问,回答就是输出驾驶决策,这种模型就是World Model。
世界模型分成三段,感知,记忆和动作。
当AI领域中讲到世界(World)、环境(Environment)这个词的时候,通常是为了与智能体(Agent)加以区分。研究智能体最多的领域,一个是强化学习,一个是机器人领域。因此可以看到,world models、world modeling最早也最常出现在机器人领域的论文中。而如今world models这个词影响最大的,可能是Jurgen 2018年放到arxiv的这篇以“world models”命名的文章,该文章最终以 “Recurrent World Models Facilitate Policy Evolution”的title发表在NeurIPS'18。
该论文中并未定义什么是World models,而是类比了认知科学中人脑的mental model,引用了1971年的文献。人类是根据有限的感官来感受并理解这个世界, 我们所做的决策和行为其实都是基于我们自已内部建立的模型,学车和开车都是这个模型不断修正的行为,这个模型根据眼睛和耳朵输入的信息,让大脑做出对应的未来时间序列上的决策,再由手脚完成决策,不管老司机还是新手,大脑驾驶模型都有预测能力,即手脚执行决策后会出现什么样的场景,或者要达到什么样的场景,大脑驾驶模型已经做出了响应。这与自动驾驶是一致的,因为自动驾驶就是一个序列到序列的映射过程,输入的是一个传感器信号序列,可能包括多个摄像头采集到的视频、Lidar采集到的点云、以及GPS、IMU等各类信息,输出的是一个未来时间段驾驶决策序列,例如可以是驾驶动作序列、也可以输出轨迹序列再转为操作动作。这个过程与大部分AI任务基本一致,这种映射过程就相当于一个函数 y = f(x)。传统的自动驾驶将这个函数分解成诸多子函数,而端到端则只有一个。
该框架图有三个主要的模块组成, 即 Vision Model(V), Memory RNN(M)和 Controller (C)。首先是Vision Model (V),此模块的主要作用是学习视觉观测的表示,这里用的方法是VAE(变分自编码器),其主要作用是将输入的视频(早期是图片) 转成特征,Transformer兴起后则转换为Token,这个过程变成Tokenizer。

图片来源:论文《World Models for Autonomous Driving: An Initial Survey》
上图就是核心的世界模型World Model,它用了MDN,Mixture Density Networks,MDN非常古老,顺便说一句,AI的所有基础数学知识都在上世纪四十年代就完成了,如今的AI不过是这些基础数学的应用,本质上人类近百年来没有进步。早在1994年,Christopher M. Bishop就提出Mixture Density Networks,MDN 结合了常规的深度神经网络和高斯混合模型GMM。神经网络可以拟合任意连续函数,通过增加网络的隐藏层数量和隐藏层大小,你可以得到强大的学习网络,无论是二次三次函数,还是正弦余弦,都可以用你的网络进行无限逼近。当我们希望拟合的函数有多个输出值的时候,这时候就需要MDN,它输出的是连续的概率分布,即高斯分布。通过组合多个高斯概率分布,理论上我们可以逼近任意概率分布。
MDN在网络的输出部分不再使用线性层或softmax作为预测值,为了引入高斯分布模型的不确定性,每个输出都是一种高斯混合分布,而不是一个确定值或者单纯的高斯分布,高斯混合分布可以解决高斯分布不好解决的多值映射问题。以回归问题为例,输入和输出均是可能有多个维度的矢量。目标值的概率密度可以表示成多个核函数的线性组合。实际很接近强化学习,我们一般用的监督学习,输出单个确定值,自然需要标注训练数据,而强化学习输出概率值,可以不需要标注训练数据,大大降低数据成本。World Model的核心作用:反事实推理(Counterfactual reasoning),也就是说,即便对于数据中没有见过的决策,在world model中都能推理出决策的结果。这里的RNN后来演化成了LSTM (长短期记忆网络)。
最后一个环节是Controller,这部分的作用就是预测接下来的action,这里设计的非常简单,目的就是为了把重心移到前面的模块中,前面的模块可以基于数据来学习。
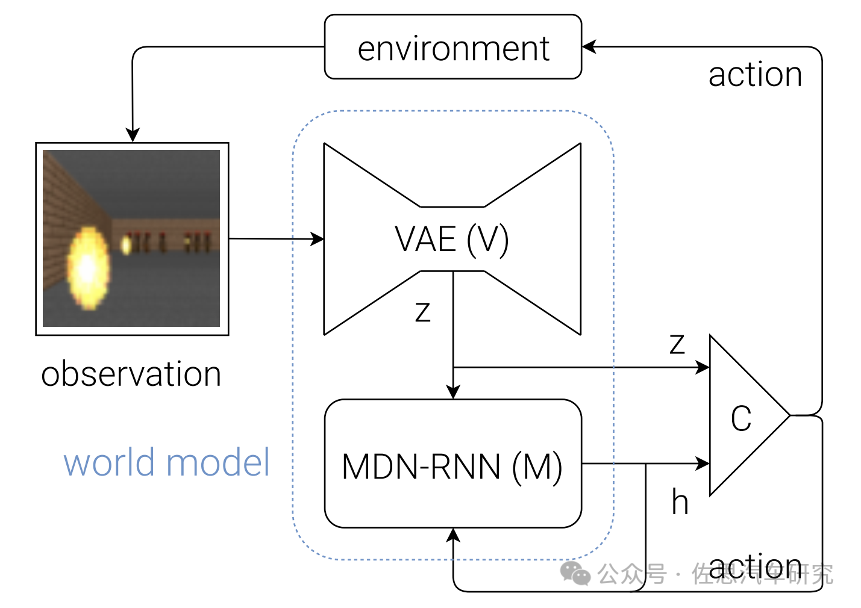
观测经过V提取feature, 然后经过M得到h, 最后观测和历史信息一块儿送给C得到动作, 基于动作会和环境交互产生新的观测....,这样可以不断地进行下去。对应微软、软银和英伟达投资的Wayve的GAIA-1,图中的VAE被改成了Tokenizer,参数是3亿,第二段的MDN-RNN演化为Transformer中的编码encoder,参数是65亿。第三段的C就是GAIA-1的第三段,视频解码decoder,参数是26亿。合计94亿参数。
世界模型的框架自2018年就定型了。2019年进一步演化出了RSSM。
RSSM将确定和随机结合,既有确定部分防止模型随意发挥,又有随机部分提升容错性。
另外演化出了JEPA,RSSM和JEPA是目前的主流世界模型核心架构。JEPA是在2023年才提出的,目前也有了多个版本,JEPA是META提出的,作者中包括了AI三巨头之一的杨立昆,Yann LeCun,CNN之父,纽约大学终身教授,与Geoffrey Hinton、Yoshua Bengio并成为“深度学习三巨头”。前Facebook人工智能研究院负责人,IJCV、PAMI和IEEE Trans 的审稿人,他创建了ICLR(International Conference on Learning Representations)会议并且跟Yoshua Bengio共同担任主席。
上图是从2022年开始World Model的关键模型技术类型分布,特斯拉的可能比较接近OccWorld,因为特斯拉的Occupancy Network做得比较好,用Occupancy Network输入,算力和存储要求都会降低很多,HW4.0能够运行。
当然,端到端不一定非要用World Model,也有其他方法,但低成本生成海量接近真实的包含Corner Case多样化训练视频数据非World Model莫属。从数据领域来说这是革命性的,从模型训练来说,算不上革命性,黑盒子的属性更强了。相对经典分段式做法,谁性能更好还无法评估,只是换了一种思路。自动驾驶,依然前路漫漫,任重道远。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。