6DoF视频分发与呈现中存在的关键问题解析
00 引言
6自由度(six degrees of freedom,6DoF)视频具体表现为在观看视频过程中,用户站在原地时头部与视频内容之间的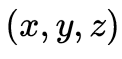 3个自由度的交互和用户位姿发生移动时与内容之间的另外3个自由度的交互(Boyce等,2021)。
3个自由度的交互和用户位姿发生移动时与内容之间的另外3个自由度的交互(Boyce等,2021)。
6DoF视频有多视点视频、多视点+深度视频、光场视频、焦栈图像和点云序列等多种数据表示方式(Wien等,2019)。用户可以通过体感、视线、手势、触控和按键等交互方式来选取任意方向和位置的观看视角。视频系统在获得用户交互参数后,通过虚拟视点绘制技术完成视角平滑切换,在沉浸式体验上更加出色。6DoF视频体现了用户与视频内容的高度交互性,全面打破了人们被动接受视频内容的传统模式,能够实现千人千面的视觉体验,是当前多媒体通信、计算机视觉、人机交互和计算显示等多个学科领域的交叉与前沿。
一方面,6DoF视频通过计算重构的方式向用户提供包括视角、光照、焦距和视场范围等多个视听维度的交互与变化,使千里之外的用户有身临其境之感,这与元宇宙所具有的感知、计算、重构、协同和交互等技术特征高度重合。因此,6DoF视频所涵盖的技术体系可用做实现元宇宙的替代技术框架。另一方面,6DoF视频从采集、处理、编码、传输、显示、交互和计算等方面改变了数字媒体端到端全链条的生产制作模式,给内容提供商、运营商、设备商和用户带来巨大的改变,因此也受到国防训练、数字媒体和数字教育的高度关注。
本文将围绕6DoF视频内容的生产、分发与呈现中存在的关键问题(如图1所示),从内容采集与预处理、编码压缩与传输优化以及交互与呈现等方面阐述国内外研究进展,并围绕该领域当下挑战及未来趋势开展讨论。

图1 6DoF视频系统中的关键问题
01 6DoF内容采集与预处理
6DoF视频以3维场景为观察对象,以3维时空分布的点云、图像等为数据表达,可用模型
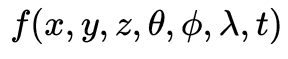
刻画,包含空间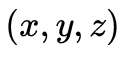 、角度
、角度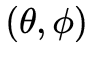 、光谱
、光谱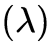 和时间
和时间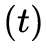 等。如何获取3维场景的视觉信息是6DoF视频采集与生成需要实现的任务与目标。相机一直以来作为获取视觉信息的主要工具,将分布在3维时空
等。如何获取3维场景的视觉信息是6DoF视频采集与生成需要实现的任务与目标。相机一直以来作为获取视觉信息的主要工具,将分布在3维时空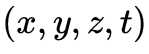 中的光降维到2维时空
中的光降维到2维时空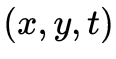 上形成图像或视频。基于相机的视觉获取无法得到深度
上形成图像或视频。基于相机的视觉获取无法得到深度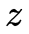 ,因此如何通过相机来实现3维场景的视觉信息获取,长期以来是一个挑战性的难题。从技术演进的角度,3维场景的视觉信息获取可分为多视点联合采集、多视点与深度联合采集这两个方向和阶段。
,因此如何通过相机来实现3维场景的视觉信息获取,长期以来是一个挑战性的难题。从技术演进的角度,3维场景的视觉信息获取可分为多视点联合采集、多视点与深度联合采集这两个方向和阶段。
1.1 多视点联合采集
虽然单相机的视觉获取只能得到平面图像,但是仿照人眼的双目视觉系统,只要能够利用2个及以上的相机进行多视点同步采集,就能够在得到的多视点图像基础上进行立体匹配,从而得到深度的信息(Marr和Poggio,1976)。为此,科研人员以6DoF视频为目标,研制出了不同类型的多视点视频采集系统。如图2所示,以影视内容制作为目标,工程技术人员于1999年首次搭建了由上百台相机共同构成的多视点联合采集系统。该系统在几何排布上具有线性环绕的特点,并形成了著名的“子弹时间”影视效果(Stankiewicz等,2018)。观众可通过这种方式在屏幕上直接得到立体的观感。通过该多视点联合采集系统所形成的交互式媒体内容具有非常震撼的视觉效果,但同时也有明显的缺陷,如不能拍动态的视频、几何排布复杂不利于后期视觉计算以及成本高昂难以商业推广等。因此,降低相机数量,简化几何排布方式,研发多相机标定方法成为多视点联合采集面临的关键需求。
为了解决上述问题,研究者提出了几种典型的几何排布模式,如图3所示。图3(a)所示的平行模式以直线分布、光轴平行的方式进行排布,视点之间的图像原则上不存在垂直偏移,在交互过程中体现为水平移动。稀疏的(间距20 cm及以上)平行模式是MPEG(motion picture expert group)中典型的多视点视频数据表达形式(Merkle等,2007),而稠密的平行模式则可较为方便地构成光线空间(ray space)(Tanimoto,2012),从而实现平移之外的纵向交互。图3(b)所示的发散模式是所有相机的光轴后延线共圆心,从形式上不局限于水平共心,也可以是球面发散的共心方式。这种模式可较方便地形成全景视频用于3自由度交互,并在许多商业应用中取得了成功。图3(c)所示的汇聚模式在排布模式上是平行模式的简单变化,在直线分布的基础上将光轴汇聚到一个点上,视点之间的图像原则上不存在垂直偏移,在交互过程中体现为具有弧度的水平移动。然而,在实际操作中汇聚模式有许多问题,如汇聚点的确定、相机间的几何标定问题等,导致大部分的汇聚模式最后退化到图2的模式,即交互只在真实相机之间做切换,较少通过视觉计算的方式去绘制虚拟视点。
图3(d)所示的围绕模式不局限于平面,也可以进一步拓展成半球体、圆球体的布置形式。与汇聚模式类似,同样面临着汇聚点确定、相机间几何标定的难题,而且难度更大,因为每一个相机一定会有另外一个相机与之完全相对,无法通过构建两个视点之间公共特征点的匹配关系以完成几何标定所需的有关参数。华中科技大学团队突破了这一限制,通过视点传递的方式克服了环绕相机阵列(Abedi等,2018)以及球面相机阵列(An等,2020)的几何标定问题,为后续720°交互奠定了基础。图3(e)所示的平面模式在几何分布上是平行模式的简单扩充,但是在实际应用中产生了许多变型,并逐步演化成光场采集系统,催生了许多交互式媒体之外的新型应用(Levoy和Hanrahan,1996)和亿像素采集系统(Brady等,2012)。
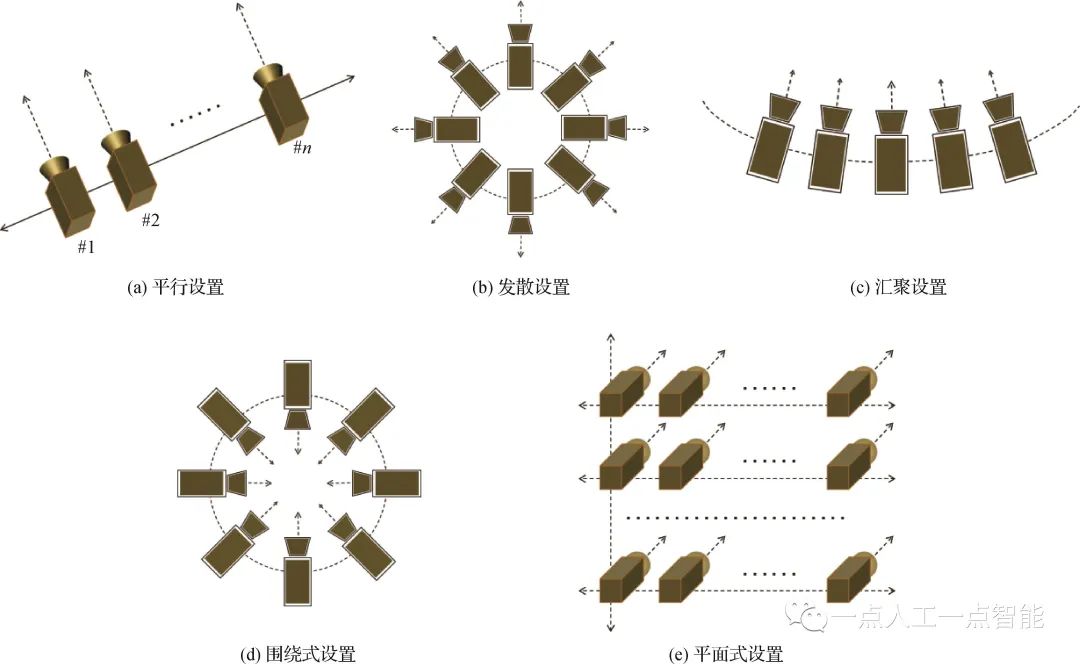
图3 几种典型的多视点视频采集系统的几何排布方式
1.2 多视点与深度联合采集
典型的多视点联合采集需通过后期计算的方式得到深度,如果能够直接得到深度信息,则可以大幅提升采集效率。然而,直接获得场景的深度信息并不是一件容易的事情,进而在获取深度信息的基础之上是否能够多视点获取,又是另外一个难题。 直接获取场景深度信息的方式大体分为被动式和主动式两个技术方向。被动式探测以双目立体匹配为代表(Zhang,2012)。主动式探测方法以结构光技术为代表,并根据光源的不同又分为点扫描(Franca等,2005)、线扫描(Scharstein和Szeliski,2002)和面结构光(Van der Jeught和Dirckx,2016)。点扫描和面扫描中激光器发出点状或条状光束,进而通过旋转或平移,实现完整的3维测量。面结构光方法投射2维编码图案,无需移动投影设备即可重建目标表面,具有更高的效率(苏显渝 等,2014)。此外,面结构光中投影图案通常与编码技术进行结合,提取块级/像素级/亚像素级的码字用于视差匹配,以获得更高的精度和效率。面结构光的编码通常包括空域编码、时域编码和相位编码,通过多个编码对场景进行多次扫描来获得目标场景的深度。上述模式都是通过扫描的方式才能得到场景的深度信息,因此不适宜动态场景的深度获取。
采用点—面结合技术的Kinect深度传感器克服了这个难题(Lilienblum和Al-Hamadi,2015),虽然深度图的质量、图像分辨率、时间分辨率和探测距离等基本参数还有很大的提升空间,但是该设备的出现首次将场景的深度感知从静态提升至了动态,给产业界和学术界同时带来一轮新的研究热潮。后来出现了基于光调制的ToF(time of flight)技术及相关设备,包括ToF相机和激光雷达(laser radar,LiDAR)等,大幅度提升了探测距离,但是在深度图质量、图像分辨率和时间分辨率等参数上也都与Kinect一样面临相同的问题。 将多个深度传感器与多个彩色相机相互配合对场景进行视觉采集,则形成了多视点与深度联合采集方案。在这些方案中,几何排布上可以借鉴多视点联合采集方案。多视点与深度联合采集的关键难点在于多深度采集中所出现的视点间干扰、彩色视频与深度视频时间分辨率不匹配以及空间分辨率差距过大等问题。多深度相机之间的干扰来自其成像原理本身,如不同视角的Kinect会使用相似甚至相同的点—面结构光,不同视角的ToF相机对同一波长的光进行相同的调制,这些都会导致解码失败。为了解决这个问题,华中科技大学团队从机理层面进行了探索,针对多种原理的深度传感器分别设计了包括M-序列等方法在内的多深度相机联合采集方案,较好地解决了上述难题(Yan等,2014;Li等,2015;Xiang等,2015)。此外,还进一步针对深度视频与彩色视频时间分辨率不匹配的问题,以及由此导致的深度图运动模糊问题,提出了时域上采样法(Yang等,2012)和时域校正法(Yang等,2015c; Gao等, 2015)等多种方法,为运动场景的立体感知提供了丰富的工具集。
1.3 深度图与点云预处理
如前所述,动态场景的深度图或点云数据往往具有空间分辨率低、时间分辨率低、画面噪声多等问题。为了保证下游任务的精度,需要进行预处理。从处理技术上来分,主要包括深度图预处理和点云数据预处理两个类型。
1.3.1 深度图预处理
深度信息不直接用于人眼观测,而是作为辅助信息帮助参考视点图像映射到正确的虚拟视点上。深度图像上的失真会传播至虚拟视点图像,造成主客观质量的下降。因此,在虚拟视点内容生成前,需通过深度预处理技术尽可能获得最接近场景实际距离的深度图像。Ibrahim等人(2020a)较详细地对深度图预处理技术工作进行了系统性的梳理。总体而言,深度图、点云的去噪与图像去噪技术是同步发展的,但同时也有自身的一些特点。典型的图像滤波器,如多边滤波器(Choudhury和Tumblin,2005)、流型滤波器(Gastal和Oliveiray,2012)和非区域均值(Buades等,2005)等都可以直接作用于深度图的去噪,但这些滤波器都只能解决以像素为单位的深度图噪声。一旦噪声区域过大,如Kinect深度传感器的噪声多以成片区域深度值缺失为特点,则传统的滤波器都会失效(Xie等,2015)。
为了解决这个问题,Kopf等人(2007)提出了联合双边滤波方法。该方法是对双边滤波的改进,引入了参考图像为指导,能够较好地处理大面积深度值缺失的难题,但同时也引入了彩色图中的边缘和纹理信息,给去噪后的深度图带来了伪纹理。Liu等人(2017)利用对齐彩色图像特征来引导深度图像修复,通过彩色信息引导权重并结合双边插值方法来进行深度图空洞修复。Wang等人(2015)提出一种面向Kinect深度图像恢复的三边约束稀疏表示方法,在惩罚项上考虑了参考块与目标块间的强度相似度和空间距离的约束,在数据保真度项下考虑了目标块质心像素的位置约束,通过对纹理图像的特征学习,预测出深度图像空洞恢复的最优解。为了有效克服伪纹理的问题,Ibrahim等人(2020b)引入条件随机场方法以抑制在彩色图引导过程中的纹理干扰问题。
随着深度学习技术的发展,人们也开始探索单一深度图(张洪彬 等,2016)、彩色与深度图联合(Zhu等,2017)的滤波方案,总体上遵循了彩色图滤波的基本架构,包括特征提取、图像重建等模块。基于深度学习框架的深度图滤波虽然能够取得较好的去噪效果,但是目前仍面临物体边缘滤波模糊的难题。 多视点联合滤波也是一个值得关注的课题。如果将每一个视点的深度图单独处理,势必会导致视点间深度不稳定的问题,为此需要将多个视点联合在一起考虑。华中科技大学团队He等人(2020b)提出了跨视点跨模态的联合滤波框架,建立了视点之间的映射模型与关联方式,能够较好地克服多种类型的噪声在不同视点间的蔓延。针对平面相机阵列,Mieloch等人(2021)考虑到纹理信息的使用会在深度修正中引入误差,仅用多个视点的深度信息对所选视点的信息进行交叉验证,通过多次迭代,增强了多个深度图像的视点间一致性,且可以自由设置需要修正的视点位置和数目。
1.3.2 点云预处理
深度相机和激光雷达传感器产生的原始点云通常是稀疏、不均匀和充满噪声的,需要进行去噪或补全。现有的点云补全的方法大致分为基于几何或对齐的方法和基于表示学习的方法两类。 基于几何或对齐的方法包括基于几何的方法和基于对齐的方法。基于几何的方法通过先前的几何假设,直接从观察到的形状部分预测不可见的形状部分(Hu等,2019)。更具体地,一些方法通过生成平滑插值来局部填充表面孔。例如拉普拉斯平滑(Nealen等,2006)和泊松表面重建(Kazhdan和Hoppe,2013),这些方法直接从观察区域推断缺失数据并显示出令人印象深刻的结果,但是需要为特定类型的模型预定义几何规则,并且仅适用于不完整程度较小的模型。基于对齐的方法在形状数据库中检索与目标对象相似的相同模型,然后将输入与模型对齐,随后对缺失区域进行补全。
目标对象包括整个模型(Pauly等,2005)或其中的一部分(Kim等,2013)。除此以外,还有一些方法使用变形后的合成模型(Rock等,2015)或非3D几何图元,例如平面(Yin等,2014)和二次曲面(Chauve等,2010)代替数据库中的3D形状。这些方法在3D模型的类型上具有较强的泛化性,但在推理优化和数据库构建过程中成本高,且对噪声敏感。 基于表示学习的方法是一种点云补全的方法。Dai等人(2017)提出了基于3D体素的编码器—解码器架构3D-EPN(3D-encoder-predictor)。尽管基于3D体素化的表示学习方法可以直接扩展使用定义在2D规则网格上的神经层或算子,但精细对象的重建需要消耗大量显存和算力。随着基于点表示学习的PointNet(Qi等,2017a)和PointNet++(Qi等,2017b)等模型的出现,人们提出了TopNet(Tchapmi等,2019)、PCN(point cloud net)(Yuan等,2018)和SA-Net(shuffle attention net)(Wen等,2020a)等基于点编码器—解码器框架的点云修复模型。该类模型首先通过编码器从不完整的点云中提取全局特征,再利用解码器根据提取的特征推断完整的点云。
现有基于表示学习的点云补全任务的相关研究主要分为两类。1)基于先进的深度学习框架。为了提高点云生成的完整形状的真实性和一致性,人们提出了基于对抗生成网络的RL-GAN-Net(reinforcement learning generative adversarial network)(Sarmad等,2019)、基于变分自动编码器的VRCNet(variational relational point completion network)(Pan等,2021)和基于注意力机制的PoinTr(Yu等,2021)、SnowflakeNet(Xiang等,2021)、PCTMA-Net(point cloud transformer with morphing atlas-based point generation network)(Lin等,2021)、MSTr(Liu等,2022)等模型,这些模型能更好地挖掘3D形状的全局和局部几何结构,从而更有利于补全点云中的不完整部分。2)基于任务特性的算子。为了保留更多的精细特征信息,SoftPool++(Wang等,2022a)设计了softpool算子替代PointNet中的最大池化算子。Wu等人(2021)提出基于密度感知的倒角距离,以改善原有损失函数对点云局部密度不敏感或精细结构保护不足等缺陷。 考虑实际应用需求,渐进式点云补全任务也开始得到关注,人们提出了CRN(cascaded refinement network)(Wang等,2022b)、PF-Net(point fractal network)(Huang等,2020b)、PMP-Net++(point cloud completion by transformer-enhanced multi-step point moving paths)(Wen等,2023)等模型,以实现3D点云的渐进细化。总体而言,基于学习的点云补全方法在性能提升上效果显著,但在模型泛化上仍有很大的提升空间。如何结合几何先验以提升模型的泛化性是一个潜在的研究方向。
02 6DoF视频压缩与传输
6DoF视频有多视点视频、多视点+深度视频、光场图像、焦栈图像和点云序列等多种数据表示方式,本节根据各种数据表示方式的特点,对6DoF视频压缩与传输的研究进展展开介绍。
2.1 多视点视频编码
自从1988年CCITT(Consultative Committee International for Telegraph and Telephone)制定了视频编码标准H.261后,视频编码技术的应用越来越广泛,并涌现出大量的视频编码标准,包括H.264/AVC(Wiegand等,2003)、H.265/HEVC(high efficiency video coding)(Ohm等,2012)和H.266/VVC(versatile video coding)(Bross等,2021)。最简单的多视点视频编码MVC(multi-view video coding)方案是独立地对各个视点进行编码,但是这样不能充分去除视点间冗余,于是产生了时域—视点域结合的编码压缩方案研究。 1)多视点视频扩展国际编码标准。MPEG-2标准中已采用了多视点视频配置来编码立体或者多视点视频信号。由于压缩标准的局限性、显示技术和硬件处理能力的限制,MPEG-2的多视点扩展没有得到实际应用。2005年,MPEG组织在H.264/AVC的基础上提出了MVC扩展标准(Vetro等,2011),并形成了联合多媒体模型(joint multiview model,JMVM)。该模型集成了视点间亮度补偿、自适应参考帧滤波、MotionSkip模式以及视点合成预测等基于宏块的编码工具。类似于H.264/AVC的MVC,JCT-3V在H.265/HEVC的基础上提出了扩展编码标准MV-HEVC(multi-view HEVC)(Tech等,2016)。我国从1996年开始参加MPEG专家组的工作,不断有提案被接受,在视频压缩的技术成果逐渐具备了国际竞争力。2002年6月,我国成立了数字音视频编解码技术标准工作组AVS(audio-video standard),目标是制定一个拥有自主知识产权的音视频编码标准。至今,其版本已经发展到AVS3。基于国际编码标准,国内学者在MVC快速算法、率失真控制和基于深度学习的多视点编码等方面进行了深入研究,取得了极大的进展。 除了高效的压缩编码标准之外,精心设计的预测编码结构能充分利用多视点视频信号中的时空相关性和视点间的相关性。目前,MVC中广泛采用的分层B帧编码结构(hierarchical B pictures,HBP)结合运动估计和视差估计,获得了较高的压缩效率和优秀的率失真性能。
2)面向编码的多视点视频预处理。
利用多视点视频扩展编码标准压缩多视点视频信号时,能在编码标准框架下同时消除时空冗余和视点间冗余。然而,多视点视频信号往往存在几何偏差和颜色偏差,影响了编码压缩效率。因此,多视点视频信号的预处理也能提升压缩性能。Doutre和Nasiopoulos(2009)对多视点视频信号进行颜色校正,提升了视点之间颜色一致性和MVC的视点间预测性能。Fezza等人(2014)提出了基于视点间对应区域直方图匹配方法的多视点颜色校正算法,以提升压缩性能。福州大学团队Niu等人(2020)针对多视点视频信号中存在的全局、局部和时间颜色差异,提出了由粗到细的多阶段颜色校正算法。
3)多视点视频快速编码。
由于各种编码标准集成了多种复杂技术,且多视点视频巨大的数据量也会带来巨大的时间开销。因此,多视点彩色视频编码的计算复杂度问题长期以来都是难题。针对各种编码标准和多视点扩展编码标准,学者们广泛地开展了快速编码算法研究。典型的手段包括减少搜索点数(Cernigliaro等,2009)、利用MVC的编码模式的时空相关性和视点相关性减少当前编码宏块的搜索数量(Zeng等,2011)以及基于像素级与图像组级的并行搜索算法(Jiang和Nooshabadi,2016)等。 国内学者也提出了若干快速编码算法。Li等人(2008)通过减小搜索范围和参考帧数目来提高MVC速度。在MVC快速宏块模式选择方面,Shen等人(2010)利用相邻视点的宏块模式辅助当前视点的宏块模式选择,提高编码速度。Ding等人(2008)通过共享视点间编码信息(例如率失真代价、编码模式和运动矢量)来降低MVC的运动估计的计算复杂度。MVC中,大量宏块的最优模式为DIRECT/SKIP模式。根据此特性,Zhang等人(2013b)提出了Direct模式的提前判断方法,从而避免所有宏块模式的搜索过程。Yeh等人(2014)利用已编码视点的最大和最小率失真代价形成阈值条件,用于提前终止当前编码视点的每个宏块编码模式选择过程。Pan等人(2015)提出了一种Direct模式的快速模式决策算法,并利用MVC特性,设计了运动和视差估计的提前终止算法。Li等人(2016b)利用宏块模式的一致性和率失真代价的相关性,提出了Direct模式的判定方法。
4)MVC的码率控制。
码率控制旨在提高网络带宽利用率和视频重建质量。与单视点视频编码的码率控制不同,MVC的码率控制需要考虑视点级的码率分配。Vizzotto等人(2013)在帧级和宏块级实现了一种分层MVC比特控制方法,该方法充分利用了当前帧和以编码相邻帧比特分布的相关性。Yuan等人(2015)提出了视点间编码依赖关系模型,认为视点间的依赖关系主要由编码器的跳跃(SKIP)模式导致,并据此提出了理论上最优的多视点视频码率分配与控制算法。
5)基于深度学习的MVC。
Lei等人(2022)提出了基于视差感知参考帧生成网络(disparity-aware reference frame generation network,DAG-Net)生成深度虚拟参考帧。该网络包含多级感受野模块、视差感知对齐模块和融合重建模块,能转换不同视点之间的视差关系,生成更可靠的参考帧。这些参考帧插入到3D-HEVC的参考帧列表中,能提升MVC的编码效率。Peng等人(2022)提出了基于多域相关学习和划分约束网络的深度环路滤波方法。其中,多域相关学习模块充分利用多视点的时间和视点相关性来恢复失真视频的高频信息,分割约束重建模块通过设计分割损失减少压缩伪影。
2.2 多视点+深度视频编码
多视点彩色加深度(multiview video plus depth, MVD)是一种典型的场景表示方式,MVD信号包括多视点视频信号和对应的深度视频信号。多视点视频信号是利用相机阵列对在同一场景从不同位置采集得到,而对应深度视频可采用深度相机获取或者利用软件估计得到。与传统的视频信号相比,MVD的数据量随着相机数目的增加而成倍增加。
1)多视点+深度视频国际编码标准。
为了编码MVD信号,JCT-3V基于HEVC提出了3D-HEVC的扩展编码标准(Tech等,2016),该标准能充分利用深度视频的特性和视点之间的相关性,提升MVD信号的编码性能。针对沉浸式视频的最新编码压缩标准为ISO/IEC MIV(MPEG immersive video),该标准定义了比特流格式和解码过程。沉浸式视频参考软件TMIV(test model for immersive video)包括编码器、解码器和渲染器等,并提供了测试用例、测试条件、质量评估方法和实验性能结果等。在TMIV中,多个纹理和几何视图使用传统的2D视频编解码器编码为补丁的图集,同时优化比特率、像素率和质量。
2)多视点+深度视频快速编码。
在基于H.265/HEVC及多视点视频扩展标准方面,学者们提出了基于MV-HEVC和3D-HEVC标准的多视点深度视频快速编码算法(张洪彬 等,2016)。由于深度视频编码深度视频信息反映3D场景的几何信息,最简单的方法是对深度视频下采样,降低编码复杂度和降低码率,代价为丢失场景信息,导致绘制失真。Tohidypour等人(2016)利用已编码信息,结合在线学习的方法,调节3D-HEVC编码中非基础视点彩色视频的运动搜索范围和降低模式搜索的复杂度。Chung等人(2016)提出了新的帧内/帧间预测和快速四叉树划分方案,既提高了3D-HEVC的深度视频的压缩率,又提高了压缩速度。Zhang等人(2018)针对3D-HEVC中深度视频编码模式引入的额外编码复杂度,提出了两种深度视频的帧内模式决策方法。Xu等人(2021)基于MV-HEVC编码平台,提出了复杂度分配和调节,实现了MVC的编码复杂度优化,已适应于不同的视频应用系统。在多视点深度视频方面,Lei等人(2015)利用MVD视频信号中的视点相关性、彩色和深度视频的相关性,提出了多视点深度视频快速编码算法。Peng等人(2016)和黄超等人(2018)基于3D-HEVC提出了联合预处理和快速编码系列算法,增强了MVD信号中深度视频的时间不一致性,提高了压缩效率和编码速度。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。