2019年,英特尔推出了CXL技术,短短几年时间,CXL便成为业界公认的先进设备互连标准,其最为强劲的竞争对手Gen-Z、OpenCAPI都纷纷退出了竞争,并将Gen-Z协议、OpenCAPI协议转让给CXL。
目前业界对于CXL的熟识程度远远不及PCI-e、HBM等新型存储技术,主要是因为目前PCIe还有其适用性,而归根结底是因为该技术发展过于新、发展过于迅速。CXL全称Compute Express Link,是一个全新的得到业界认同的互联技术标准,其可以有效解决内存墙和IO墙的瓶颈。PCI-e技术是CXL技术的底层基础,CXL则可视为PCI-e技术的再提高版本,并且,CXL延伸了更多变革性的功能。
2019年至今,CXL已经发表了1.0/1.1、2.0、3.0/3.1五个不同的版本,CXL2.0内存的池化(Pooling)功能较好的实现了以内存为中心的构想;CXL3.0则实现Memory sharing(内存共享)和内存访问,在硬件上实现了多机共同访问同样内存地址的能力;而CXL3.1,则具备开启更多对等通信通道的能力,实现了对内存和存储的独立分离,形成独立的模块。并且新规范将支持目前仍在研发中的DDR6内存。
并且对于未来,CXL有着非常清晰的技术发展路线图,业界也对它的未来充满期待。关于CXL技术为何物,读者可以看《大内存时代振奋人心的CXL技术(上)》、《大内存时代振奋人心的CXL技术(下)》,本文将对最新的CXL 3.1进行补充。
关于CXL 3.1
11月末,CXL 3.1新版本正式发布。本次CXL 3.1是对CXL 3.0版本的渐进性的更新,新规范对横向扩展 CXL 进行了额外的结构改进、新的可信执行环境 ehnahcments 以及对内存扩展器的改进。
CXL 3.0于2022年8月推出,CXL 2.0则于2020年推出。总体来看,CXL 3.1的推出速度更快了,也更为适配当前AI浪潮等数据中心的海量存储及运算需求。这次更新不仅提供了更为迅捷、更为安全的计算环境,同时也为将数据中心打造成规模宏大的服务器奠定了更加牢固的技术基础。
国外专业评测网站ServeTheHome发表的《CXL 3.1 Specification Aims for Big Topologies》中,对CXL 3.1技术进行了解析。

基于 CXL 3.1 结构端口的路由( 图片来源:CXL联盟,下同)
CXL 3.1 在底层进行了许多重大更改,主要是为了解决团队构建更大的 CXL 系统和拓扑时发生的问题。

CXL 3.1 结构增强概述
CXL 3 带来了基于端口的路由 (PBR) 等功能,这与基于层次结构的路由不同,后者更类似于 PCIe 树形拓扑。这是促进更大的拓扑和任意通信所必需的。
CXL 3.1 的一项增强功能是支持使用全局集成内存 (GIM) 通过 CXL 结构进行主机到主机通信。

CXL 3.1 Fabric 主机托管全局集成内存
另一大问题是通过CXL对 .mem 内存事务的直接P2P支持。所有关于GPU内存容量的讨论都是AI的限制因素,这将是一种可以将CXL内存和加速器添加到CXL交换机上并让加速器直接使用Type-3 CXL内存扩展设备的用例类型。

通过PBR交换机对加速器的CXL 3.1 Fabric直接 P2P Mem支持
还有针对基于端口的路由 CXL 交换机的 Fabric Manager API 定义。结构管理器最终可能会成为 CXL 生态系统的关键战场,因为它需要跟踪集群中发生的许多事情。
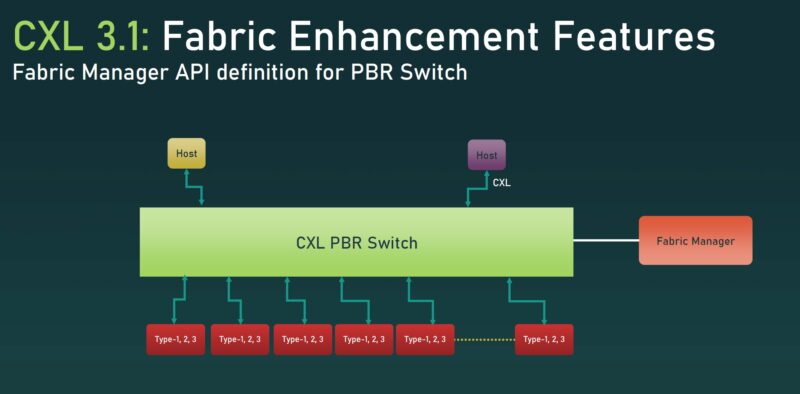
CXL 3.1 结构管理器 API
CXL 3.1 可信安全协议 (TSP) 是处理平台安全性的下一步。想象一下,云提供商拥有多租户虚拟机共享通过 CXL 连接的设备。
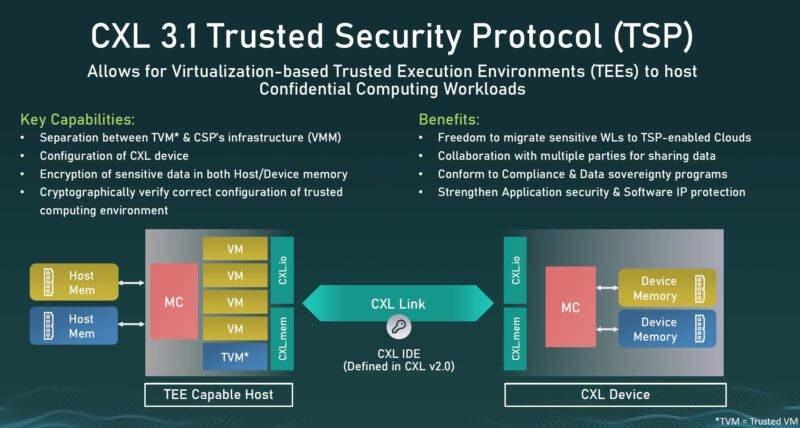
CXL 3.1 安全可信安全协议 TSP
因此,诸如机密计算之类的当今云虚拟机中的热门话题需要扩展到服务器和连接到结构的设备的范围。

CXL 3.1 TSP 的安全要素
CXL 附加内存还获得了许多 RAS 功能以及元数据的附加位。同样,随着拓扑变得越来越大以确保可靠性,这一点很重要。
CXL 3.1支持DDR6
CXL技术的应用场景非常广泛,其中包括数据中心、人工智能和处理器互联等领域。而在数据中心领域,严重的内存问题一直是业界十分头疼的问题。当下存储成本不断增加,以及更为现实的计算和带宽失衡现状使得我们愈加关注内存问题的解决上。
CXL 的主要优点是它允许对直接连接到不同端点的内存进行加载/存储,如此前所述,CXL2.0版本推出了三个十分重要的新功能,分别是可以改变服务器业界生态构型的Switching,以及它带来的加速卡(AI、ML和Smart NIC)和内存的池化(Pooling)。

CXL2.0 Switching及内存的池化
如上所述,它使得Memory Polling(内存池)成为可能,你可以跨系统设备实现共享内存池,这就增加了很多的灵活性。比如,如果有机器内存不够时,就可以灵活地在这个池子里寻找内存空间;如果这台机器不需要这些内存了还可以随时还回来。也就是说越靠近CPU的存储器(如DRAM)将被用来处理更为亟需的工作,这无疑将大大提高内存的使用率,或者降低内存的使用成本。
而CXL 3.0又在物理和逻辑层面进行了升级,在物理层面,CXL3.0将每通道吞吐量提升了一倍,达到64GT/s。逻辑层面上,CXL3.0扩招了标准逻辑能力,允许更复杂的连接拓扑,以及一组CXL设备内可以灵活实现Memory sharing(内存共享)和内存访问。比如,它可以使得多个Switch互相连接,可以使得上百个服务器互联并共享内存。

CXL3.0 Memory sharing
Memory sharing是非常大的一个亮点,这种能力突破了某一个物理内存只能属于某一台服务器的限制,在硬件上实现了多机共同访问同样内存地址的能力。可以说,CXL的内存一致性得到很大的增强,因为此前的CXL2.0只能通过软件实现Memory sharing。
到了最新的CXL 3.1新规范,据悉,其将支持目前仍在研发中的DDR6内存。目前,JEDEC对DDR6并没有进行详细的讨论。
CXL 3.1 协议可以开放更多点对点通信,将内存和存储分解到单独的盒子中。通过传统网络和互连技术进行分解已经讨论了十年,但 CXL 提供了提供广泛的计算资源所需的可扩展性。
其一,CXL 3.1 规范提供了支持新型内存的机会,并且还可以更有效地将数据重新路由到内存和加速器。
一项重要的进步涉及将结构上的内存资源集中在一个全局地址下。该功能称为全局集成内存,对于在内存和其他资源之间建立更快的连接非常重要。
加速器还能够直接与内存资源通信。基于端口的路由的新功能有助于更快地访问内存资源。

CXL 3.1 内存增强
在《CXL 3.1 Specification Aims for Big Topologies》一文中,该作者表示,对于未来的发展,CXL 3.0/ CXL 3.1 就产品而言仍然远远不够,因为该规范是为连接数千个CXL设备而设计的,而现状是我们今天正在用数万个加速器构建人工智能集群。在CXL 世界中,连接的CXL设备可能比当今的加速器更多,其认为CXL在未来或需要扩展。
封面图片来源:拍信网