激光雷达的春天何时到来?华为的融合算法揭秘
激光雷达的春天何时到来取决于点云数据应用算法的效率和性能,而非激光雷达本身。对于点云这种稀疏特征数据,人类目前还未找到合适的应用算法,而摄像头这种稠密矩阵数据,人类已找到了很多高效高性能的应用算法。这正是激光雷达尴尬之处,没有合适的算法发挥不出激光雷达的优势。
目前的算法都是针对或对视觉系统优化的算法,而开发合适的算法需要大量的人员投入,这不是激光雷达厂家所能完成的,而在计算机视觉领域,有几百万乃至上千万研发人员,每天都有大量的研究论文发表。此外,激光雷达目前的应用都集中在点云上,而针对激光雷达强度数据应用的研究几乎为零,激光雷达最独特的领域无人问津,这是纯视觉声势越来越强大的主要原因。
激光雷达行业正处于寒冬中。在激光雷达企业中,无论是出货量还是收入均稳居第一名的激光雷达厂家是禾赛科技,2023年2季度禾赛ADAS激光雷达出货量达45694个,自动驾驶激光雷达出货量为6412个。

图片来源:禾赛财报
2023年2季度禾赛收入翻番,出货量也大幅增加,然而毛利率却大跌。
图片来源:禾赛财报
虽然亏损幅度有所收窄,但2023年2季度的毛利率只有29.8%,较去年同期大幅下滑,并且去年同期正值疫情严重时期,禾赛的生产基地位于封城中的上海。实际自2020年禾赛的毛利率就呈下滑趋势,2020年的毛利率为57.5%,2021年为53.0%,2022年是39.2%,估计2023年大概率低于30%。依靠理想这个大客户,禾赛稳居激光雷达第一名,但我们不难算出,针对ADAS的激光雷达也就是理想车上用的激光雷达毛利率很低。随着自动驾驶热潮逐渐褪去,高毛利率的自动驾驶激光雷达出货量必然持续降低。
相对而言,禾赛还是表现最好的激光雷达公司,至少毛利率是正的。之前的激光雷达明星公司Luminar的毛利率一直是负数,2023年2季度Luminar收入为1620万美元,毛亏损1830万美元。股市上激光雷达公司都表现很差,Luminar自2021年2月达到37.73美元的高点后一路下滑,2023年10月6号收盘仅有4.30美元,蒸发了约90%。对比来看,禾赛的跌幅就小多了,2023年2月上市,2月17日达到最高的22.10美元,10月6号收盘是9.62美元,跌幅56.67%。其他激光雷达公司差不多都是上市即最高点,一路跌势,跌幅普遍都在90%以上,跌幅95%以上的也比比皆是。
以禾赛的出货量而言,激光雷达的出货量已经不能算低了,但未见到规模效应带来的成本下降。
激光雷达最大的敌人就是特斯拉。随着Waymo之流的声音渐渐消失,特斯拉已是公认的自动驾驶翘楚,至少在普通消费者心中是这样,并且Waymo等也确实不争气,而特斯拉软硬一体,不仅有FSD芯片,连训练用芯片Dojo
D1也颇有声势,特斯拉已引领潮流,且遥遥领先,同时特斯拉是坚持纯视觉的,一直未用激光雷达,且相当鄙视激光雷达。
理论上激光雷达有各种优势,但实际表现是特斯拉的纯视觉不比用激光雷达的差。这就是牵涉到传感器融合的问题和点云算法的问题。
根据奥卡姆剃刀原则,如无必要,勿增实体。也就是简洁至上(Simple Is Best),能简单就不要复杂,大道至简,效率至上,自然界中的进化方向就是如此,越简单一般效率就越高。传感器融合就违背这个原则,传感器融合一直是难点,在nuScenes和Waymo 3D目标检测数据集上,LiDAR-only 方法要比传感器融合多模态的方法效果好得多。
目前,激光雷达与摄像头融合可以分为三大类:结果级、提案级和点级。
结果级result-level:FPointNet,RoarNet等。粗粒度融合,结果是漏检的可能性更高,反而不如不融合。
提案或特征级proposal-level:MV3D,AVOD等。由于感兴趣区域通常含有大量的背景噪声,效果也不佳。
点级point-level :分割分数:PointPainting,FusionPainting,CNN特征:EPNet,MVXNet,PointAugmenting等。
目前,学术界主要研究点级,效果比前两种要好,但要增加不少硬件成本(如FPGA)和计算成本;产业界则集中在前两个领域内研究,因为基本不增加硬件成本。
激光雷达和摄像头是两种实际差异很大的传感器,点级融合方法仍存在多个主要问题:
首先,它们通过元素级联或相加将激光雷达特征与图像特征融合,在图像特征质量较低的情况下,性能严重下降。
其次,寻找稀疏的LiDAR点与密集的图像像素之间的硬关联,不仅浪费了大量具有丰富语义信息的图像特征,而且严重依赖于两个传感器之间的高质量校准,而由于固有的时空偏差,这种高质量校准永远无法实现。例如FOV,大部分主摄像头的FOV是80-100度,而激光雷达一般是120-140度。激光雷达的帧率一般是10Hz,摄像头是25-30Hz,激光雷达的角分辨率和帧率是反比关系,帧率越低,角分辨率就越高。两者的中心点必然有明显水平或垂直距离,摄像头可以看成一个圆球形接收光线的传感器,激光雷达是一个矩形扫描发射与接收光线的传感器。高精度,完全统一到一个坐标系下是不可能的。
再次,点云信息的结构性不强,如反射率不同的物体,得到的激光反射点差别较大,极端的例子如金属镜子与黑色车辆,同样的距离,点云数可能相差十倍以上。
最后,激光雷达的点云信息是典型的稀疏矩阵,而摄像头是典型的稠密矩阵。人类对于稠密矩阵的加速计算已经非常成熟,但对于稀疏矩阵,目前还是处于摸索状态。
目前,产业界还是使用非常古老的pointpillars算法(基于平视Boundingbox),自从特斯拉引入语义分割和occupancy network,这个算法显然已落后不少。加上激光雷达的效果还不如纯视觉效果好。
目前的研究方向是在BEV框架下的激光雷达与摄像头融合,并导入transformer。其中有三篇论文值得一提,即:
北京大学王勇涛课题组与阿里巴巴达摩院自动驾驶实验室合作完成的《BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework》
华为智能驾驶IAS与香港科技大学的《TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers》
MIT韩松团队与上海交大的论文《BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation》
需要指出,由于深度神经网络的不可解释性,这些研究都是基于nuScenes和Waymo 3D目标检测数据集的,换一个中国路况的数据集可能会得出完全相反的结果,而这种现象无法解释。只能说基于这两个数据集,这两种方法效果较好。
下面来看华为的TransFusion。
TransFusion的整体管线

图片来源:《TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers》
TransFusion使用LiDAR-camera融合与软关联机制,以处理低劣的图像条件。具体来说,TransFusion由卷积骨干(为什么不用更好的transformer做骨干?因为计算成本会至少增加几十倍乃至百倍,汽车领域是不可能用transformer做骨干的,至少5年内如此)和基于Transformers解码器的检测头组成。
解码器的第一层使用稀疏的object queries集预测来自LiDAR点云的初始边界框,其第二层解码器自适应地将object queries与有用的图像特征融合,充分利用空间和上下文关系。Transformers的注意力机制使模型能够自适应决定从图像中获取什么信息和从什么位置获取信息,从而形成一个鲁棒和有效的融合策略。
此外,论文还设计了一种图像引导的query初始化策略来处理点云中难以检测的对象。
具体过程:
(1)3D点云输入3D backbones获得BEV特征图。
(2)初始化Object query按照Transformer架构输出初始的边界框预测。
(3)上一步中的3D边界框预测投影到2D图像上,并将FFN之前的特征作为新的query features通过SMCA选择2D特征进行融合。
(4)输出最终的BBOX。
(5)为利用高分辨率的图像,提高对小物体检测的鲁棒性,增加了图像引导的Object query初始化。对步骤(2)进行增强。
来看BEVFusion,学术圈内影响力比较大的还是MIT的那篇BEVFusion,阿里和北大的BEVFusion影响比较小,或许也是阿里达摩院裁撤自动驾驶研究团队的原因之一。

图片来源:《BEVFusion: A Simple andRobust LiDAR-Camera Fusion Framework》
阿里与北大的BEVFusion有点近似提案级的融合,其最独特之处是考虑了激光雷达失效的状况。激光雷达的反射率取决于物体表面光滑程度、物体密度和物体颜色,在某些情况下,如黑色车辆或物体,其表面不够平滑,激光雷达第一次直接反射点稀少,激光雷达可能出现漏检,这样融合就失去意义了。BEVFusion作者认为LiDAR-相机融合的理想框架应该是:无论其他模态是否存在,单一模态的感知不应该失效,但同时拥有两种模态能够进一步提高感知准确性。为此,作者提出了一个简单而有效的框架BEVFusion,它解决了当前方法的LiDAR-相机融合的依赖性。

图片来源:《BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework》
该框架有两个独立的流,它们将来自相机和LiDAR传感器的原始输入编码至同一BEV空间内的特征。在这两个流之后,作者设计了一个简单模块来融合这些BEV特征,以便最终的特征可以传递到下游任务架构中。由于BEVFusion是一种通用框架,当前用于相机和LiDAR的单模态BEV特征提取模型都可以合并到该框架中。
BEVFusion采用Lift-Splat-Shoot作为相机流,它将多视图图像特征投影到3D车身坐标特征以生成相机BEV特征。对于LiDAR流,BEVFusion选择了三个流行的模型,两个基于超体素(voxel)的模型和一个基于柱子(pillar)的模型,将LiDAR特征编码到BEV空间中。
这种融合还是后融合,虽然考虑到了激光雷达失效,但激光雷达的噪音虚像鬼影则没有提及,点级融合还是目前学术圈的主流。早期点级融合,一种是将camera数据投影到点云上,然后用点云检测算法进行检测,如PointNet,SparseConvNet;这种方法丢失了图像的语义信息;另一种是将点云投影到图像上,用图像检测算法进行检测,但是这种方法丢失几何信息,比如现实世界比较远的物体,投影到图片上却比较近。

图片来源:《BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation》
BEVFusion将两者统一到BEV下,既不损失几何信息也不损失语义信息。

图片来源:《BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation》
Fusion是由Image和PointCloud 两个支路在中间合并而成。合并看起来像是直接叠起来简单融合。而后的BEV Encoder对CAT后的特征进行编码、特征融合。最后是一个多任务的检测头。
Image支路。很明显这条支路借鉴了LSS(英伟达在2020年8月发表的一篇有关BEV的论文,提出Lift,Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D,简写为LSS)的视锥变换view Transform,进一步卷积转变为BEV下的特征。论文中认为每个相机的特征像素都投回一个3D空间下的射线,从而在BEV下保留了大量的语义信息。
PointCloud支路。该路径下似乎是直接通过z轴方向的压缩,把3维点云特征变换为BEV下点云特征。论文中说这样避免了几何信息失真,不过这点非常值得怀疑。
合并。合并后通过BEV Encoder实现特征编码(融合)。通常编码器可以是ResNet(BEVdet)、EfficientNet或者利用Tranformer结构也未尝不可。
nuScenes 3D目标检测数据集上的成绩对比
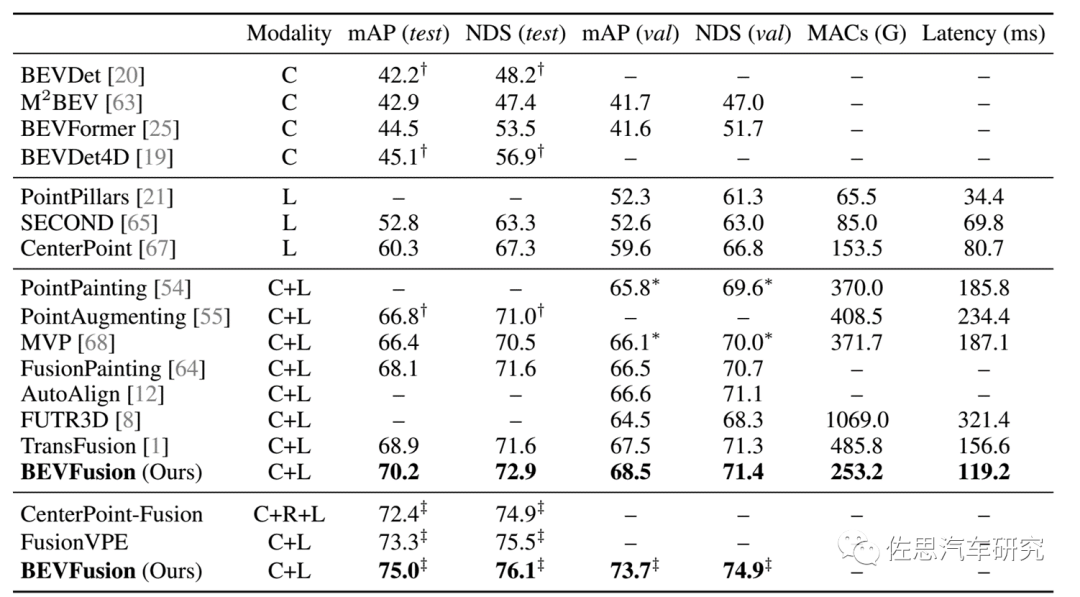
上表中,C指摄像头,L指激光雷达,R指毫米波雷达,这里的BEVFusion是MIT的,TransFusion就是华为的。目前业内常用的是PointPillars,延迟最小,消耗算力最低,硬件成本最低,性能比纯视觉要好不少。华为的TransFusion与MIT的BEVFusion相差甚微,可以说是旗鼓相当,但华为消耗的算力几乎是MIT的两倍。
还有一点要指出,这里的算力消耗是浮点运算算力的消耗。汽车产业目前都是用的INT8即8位整数算力,很多汽车产业AI硬件是无法应对浮点运算或浮点运算效率下降近百倍,如英伟达的顶配Orin,其号称254TOPS的算力是INT8格式下的算力,其中170TOPS是纯粹的张量核,是针对INT8的,其GPU部分才能对应浮点运算,算力大约5.3TOPS@FP32。
最后说一下激光雷达的稀疏矩阵,即便是128线激光雷达,其点云数据也是稀疏的。在AI时代就是稀疏矩阵,即矩阵中含有大量的0,工业界针对稠密张量的硬件设计已接近成熟,一些具有代表性的DSA已经达到较高的运算效率,如tensor core,systolic array。而稀疏张量的带宽和算力要求与稠密张量不同,零元素与任意元素相乘的结果总是零,零元素出现的乘法项对多项式的结果没有贡献,因此,以矩阵或向量乘法为核心的稀疏张量算子中,存在大量的冗余存储和无效计算。稀疏矩阵有着自己独特的坐标系表示,负载差异较大,导致硬件加速设计难度较大或者效果欠佳。需要指出谷歌TPU V4所谓的稀疏核不是针对稀疏矩阵的,它是针对Transformer嵌入层的稀疏计算的。
尽管纯激光雷达模式明显比纯视觉在3D目标检测上要更好,但不要摄像头的智能车显然不可能存在,必须走融合模式,融合必然带来计算成本和硬件成本的增加。融合模式必须证明自己较纯视觉模式更有价值,更具性价比,激光雷达才能迎来春天。然而,深度神经网络的不可解释性以及高度依赖数据集的特性让算法与算法之间真正的对比是无法实现的,胜出的关键就在于消费者的主观感受,显然特斯拉的纯视觉更受推崇。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。