上回系列文章《基于ODX诊断测试开发(1): ODX数据库剖析》简单介绍了ODX文件类型及各个文件层级结构,本期我们来详细介绍下ODX数据库如何解析。
在展开正文之前,先说明一下,此文介绍的解析ODX数据库的目的所在。针对涉及诊断功能类(如DTC等)测试的项目,实现过程大致为两步:先通过CANoe-CAPL完成通用的诊断功能测试脚本的开发;当针对具体ECU实施测试时,依据该ECU的诊断数据表,完成上述通用脚本的参数配置,可以手动配置(效率较低)或通过解析诊断数据表完成自动配置。过往项目中,诊断数据表既有Excel表格也有ODX格式。为此,北汇开发了诊断数据表的解析模块(支持Excel和ODX格式),实现对测试脚本参数的自动配置,从而提高效率。
01ODX实现方式
ODX使用统一建模语言UML类图来描述的,ODX数据又是通过XML文件格式来储存的。我们知道类包含属性和方法,同时具有封装、继承、多态等特点。那么如何将UML映射为XML呢?ISO22901-1规范做出如下规定:
规 定
将UML类映射为XML的元素; 如果UML中类的属性有《attr》标记,则将该属性映射为XML元素的属性;如果UML中类的属性无《attr》标记,则映射为XML元素的子元素。如果UML属性有《content》标记,则映射为XML元素的内容; 如果类B通过Aggregation和composition和类A建立联系,则类B映射为XML 类A元素的子元素; 如果类B通过association和类A产生关联,则在XML中通常以引用的方式实现,如《snref》,《snpathref》或《odxlink》; UML类图中的继承关系,在XML中以的方式实现;注:Aggregation、composition和association为UML类图之间的关系,在这里不做详细介绍。
图1和图2就是根据以上规则,将UML转化为XML的例子。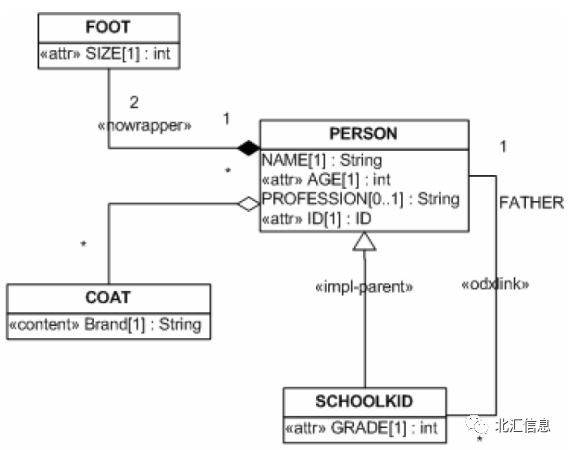
图1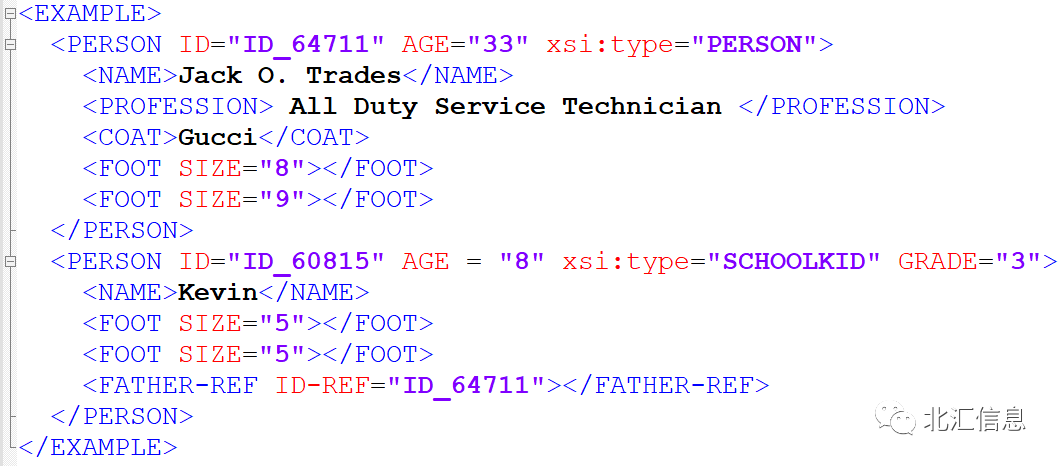
图2
02ODX继承-值继承
值继承属于ODX中的核心概念,面向对象继承的概念用于诊断数据模型具有如下优点:
多个ECU变体对诊断数据的复用;
对于ECU应用于多个项目的情况,可以提取公共数据,ECU变体中只保留不同的数据,从而减少数据冗余;
提供了数据安全和可集成性。
在上一期我们简单介绍了下ODX继承,为了避免数据的重复冗余,ODX将诊断层分为了5个层级。如图3所示,其中,Protocol具有一般性,ECU Variant具有特殊性,ECU Shared Data类似一个library,可以为其他层提供数据和服务。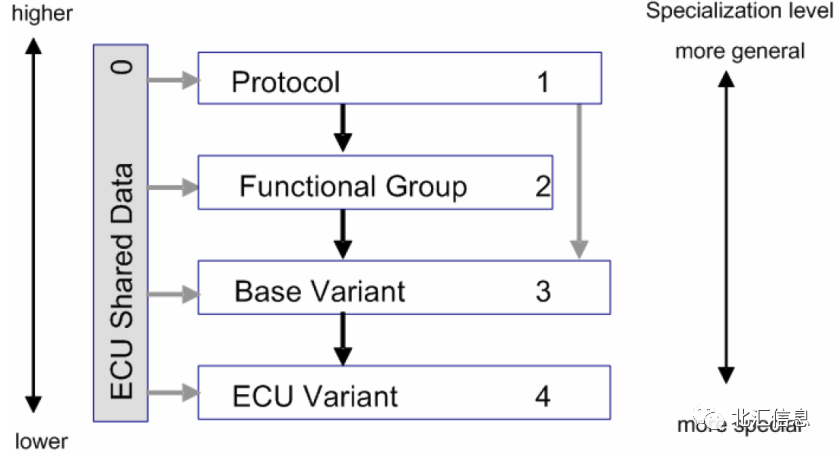
图3
我们知道,ODX中的继承关系,在XML中以的方式实现的,如果继承的数据中有部分数据不适用,可以通过去除不适用的数据。从图4的例子中可以看出,该ECU不支持level3和level4解锁等级。
图4
03ODX解析思路简介
当我们拿到一份ODX或者PDX(PDX是将一系列ODX文件打包)时,如何开展解析工作呢?
首先找到ECU的Base Variant文件。
在Base Variant中查找继承关系。
在Base Variant文件中查找对应的ECU变体即ECU Variant。
在ECU Variant文件中查找对应的诊断服务和数据。
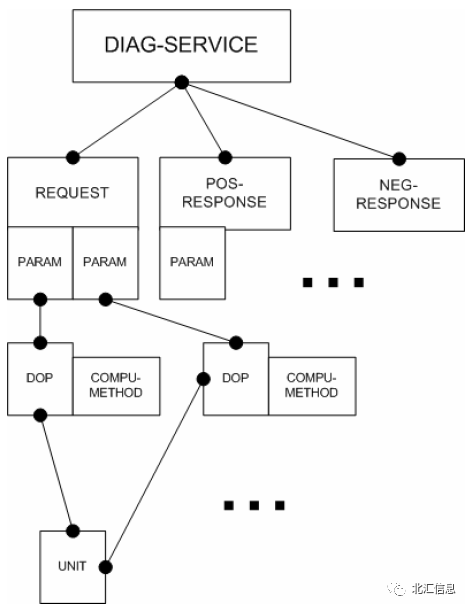
图5
04ODX解析实践
根据章节3的ODX解析思路,获得的解析结果见图6、7和8。其中ECU Shared Data作为library,提供了通用的诊断服务,见图6;而ECU变体BCM 88890251 A除了继承Base Variant的通用诊断服务,还增加了多个DID、RID、IO Control,同时去除了19 15、27 05和27 06这些不适用的服务。图8展示了ODX中包含的多种数据类型,这里不再详细介绍。
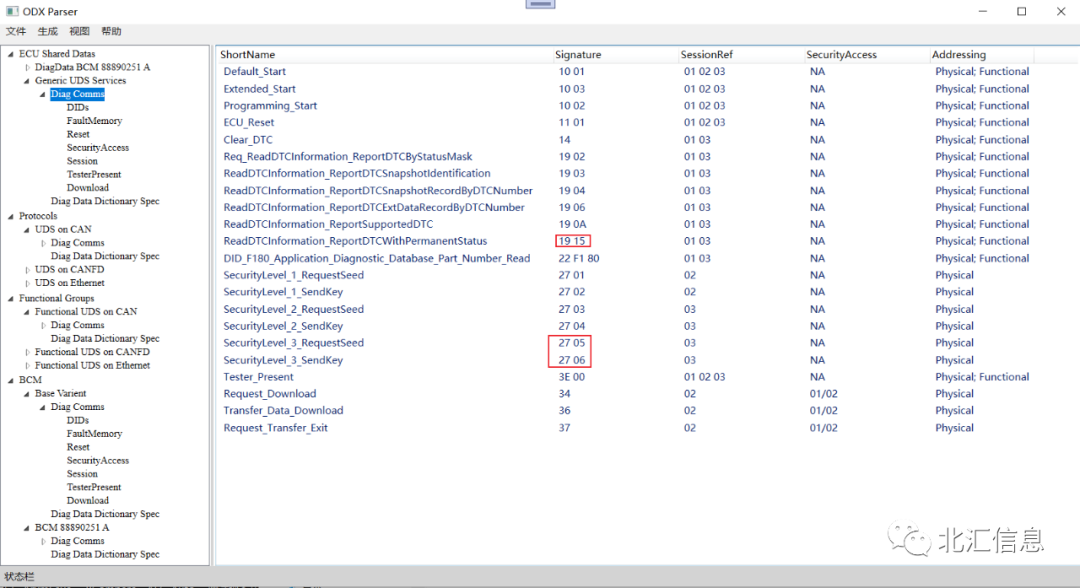
图6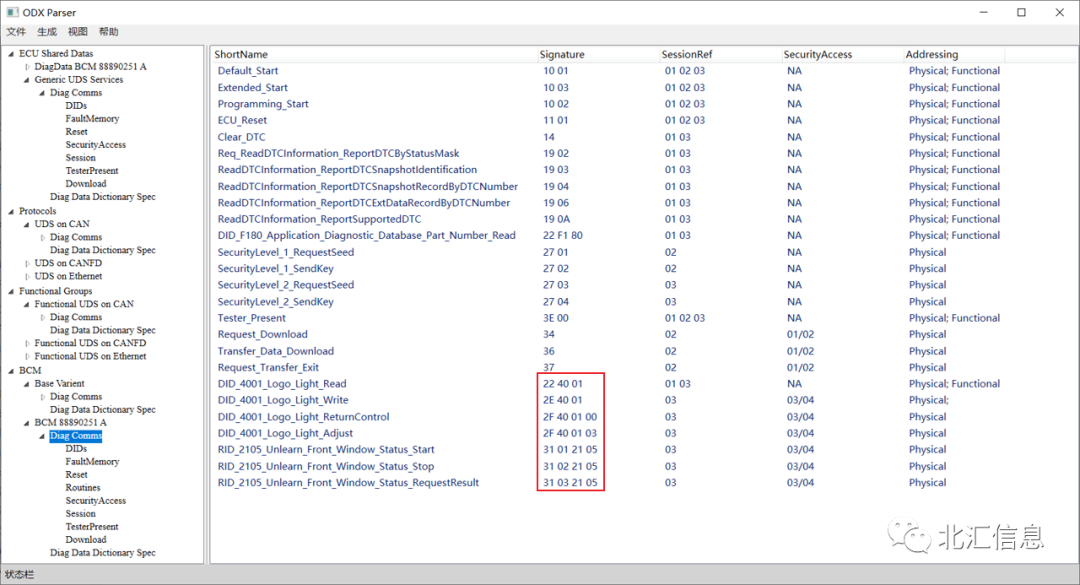
图7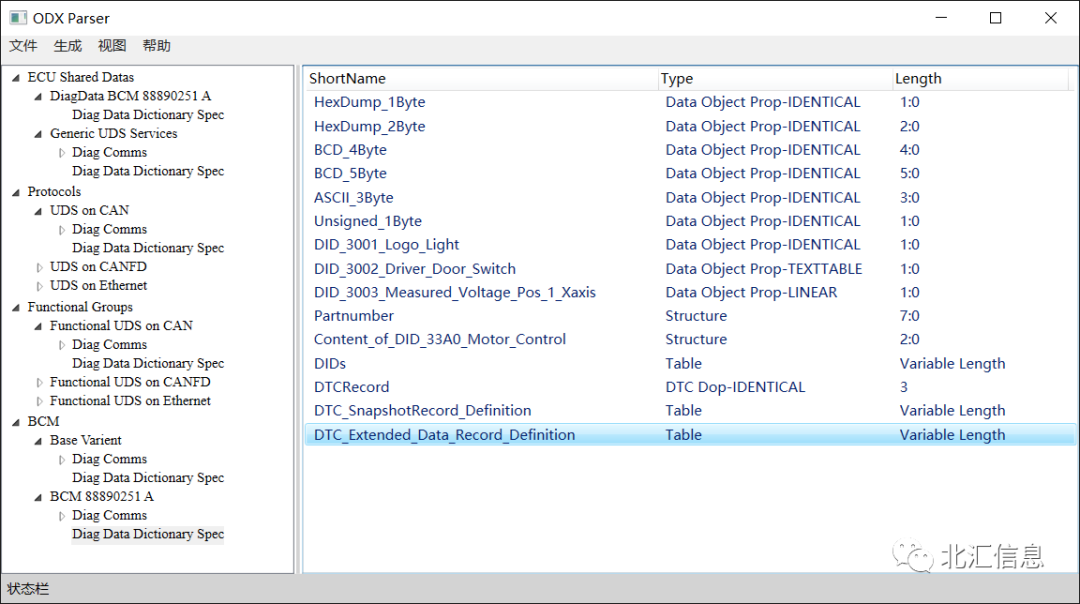
图8
05总结
相较于传统的Excel格式的诊断数据交换的不便性,ODX统一了诊断文件的格式,在研发、测试、生产和售后等部门传递交换时,不需要进行格式转换,因此,很多OEM开始使用ODX。