(1) 我们提出了第一个即插即用的learning-based的视频深度框架NVDS。可以用于任意的单目图像深度预测模型,去除时域抖动增强帧间一致性。
(2) 我们提出的Video Depth in the Wild(VDW) 数据集,是当前体量最大场景最丰富的自然场景视频深度数据集。
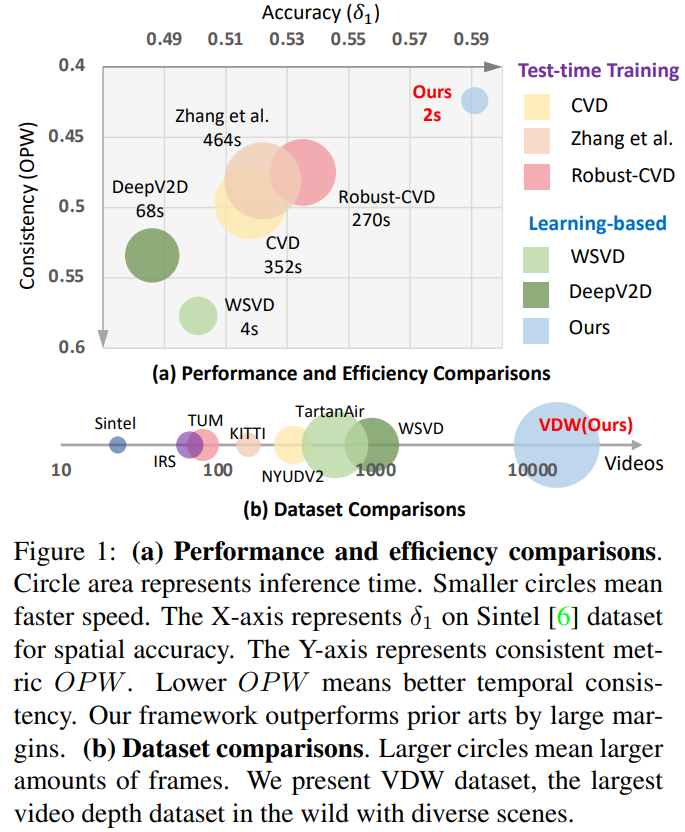
如下图,与之前的视频深度预测方法相比,本文方法NVDS在空间精度,时域平滑性,和推理效率上,均有提升显著。同时,本文提出的Video Depth in the Wild(VDW) 数据集,是当前体量最大场景最丰富的自然场景视频深度数据集。
1. 任务背景与动机
视频深度预测对许多下游任务(例如视频散景渲染,3D视频合成,视频特效生成等)具有重要的影响。理想的视频深度预测模型需要解决两个问题:(1) 深度的空间准确; (2) 帧间的时域一致。近些年来,单目图像深度预测算法已经显著提升了空间准确性,但如何去除抖动提升帧间时域的一致性仍是一个困难的问题。
主流的视频深度预测方法依赖于Test-time Training。他们在推理时,通过几何约束和相机参数,迫使一个单目图像深度预测模型过拟合当前特定测试视频的时域关系。这样做有两个明显的缺点:(1)鲁棒性差。相机参数在许多视频中往往难以做到准确可靠,而导致CVD,Robust-CVD等方法,产生明显的artifact和完全错误的预测结果; (2)效率很低。以CVD为例,其在四张Tesla M40 GPU上处理一段244帧的视频,需要超过四十分钟的时间。
因此,很自然的一个想法是,我们能否建立learning-based的视频深度预测方法,能够直接在数据集上学习到时域一致性的能力和先验,直接预测得到较好的结果,而不需要Test-time Training。那与所有的深度学习算法一样,设计和实现这样的learning-based的视频深度方法,就需要处理两个核心问题:(1)合理的模型设计,能够建模帧间依赖关系,提升预测结果的一致性; (2) 充足的训练数据,训练和激发模型的最佳性能。遗憾的是,之前的learning-based视频深度方法,其性能仍不如Test-time Training的方法,结果设计的有效性仍需要继续研究和探索。由于标注代价很大,已有的视频深度数据集在数据体量和场景丰富度上仍然较为有限。
2. 方法与贡献
为了解决上述的两个核心挑战,我们做出了两点贡献:
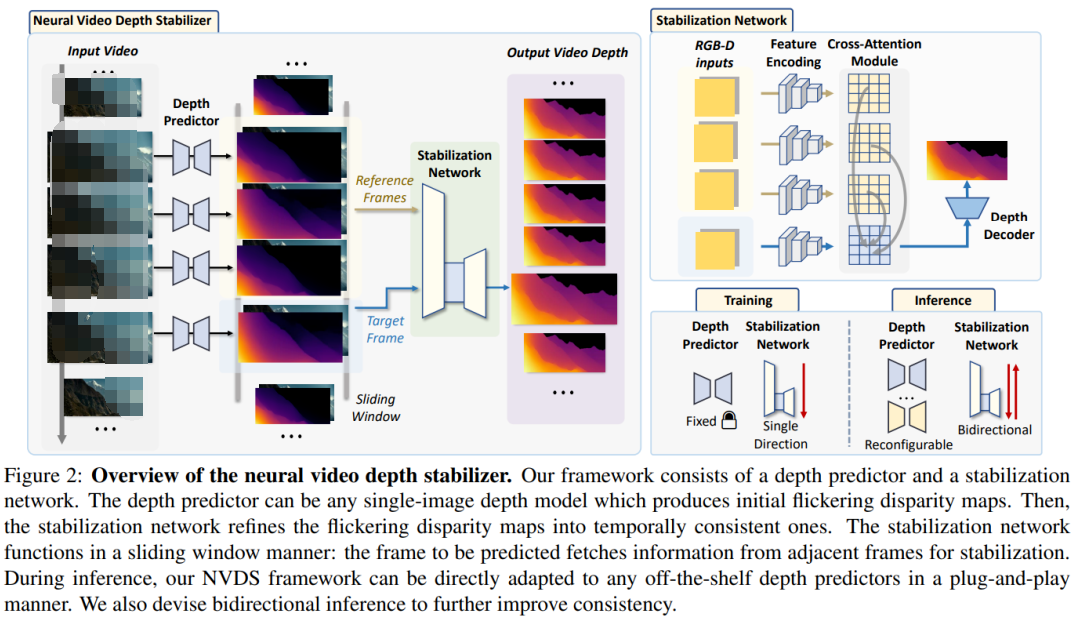
(1) 我们提出了第一个即插即用的learning-based的视频深度框架NVDS。NVDS包含一个depth predictor和一个stabilization network。其中,stabilization network可以直接被用到任意的单目图像深度预测模型上,去除时域抖动帧间一致性。之前所有的learning-based的视频深度预测模型都是独立的(stand-alone)模型,其空间性能无法受益于sota的单目图像模型,反之无法对大量已有的单目图像模型进行平滑稳定。而NVDS的方法,打破了单目图像深度预测和单目视频深度预测的壁垒,一方面能够受益于各种高精度的单图模型,反之能对任意的单图模型进行平滑稳定,实现了互相的促进和双赢。对于stabilization network ,我们采用了cross-attention建模关键帧(key frame)和参考帧(target frame)的帧间关系。同时,我们设计了双向预测的机制来扩大时域感受野,进一步提升一致性。
(2) 我们提出了Video Depth in the Wild(VDW) 数据集,是当前体量最大场景最丰富的自然场景视频深度数据集。由于巨大的标注代价,当前已有的视频深度数据集大多数都是封闭场景的。而少数的几个自然场景的视频深度数据集,其体量和丰富度还远远不足。例如Sintel只包含23段动画视频。我们的VDW数据集,采集自电影、动画、纪录片、网络视频等多种数据源,包含超过200小时的14203段视频,总计223万帧。我们还设计了天空分割投票等机制,以及严格的数据筛选和标注流程,来保证我们数据的精度。下图包含数据集的部分示例,分别来自网络视频、纪录片、动画、电影。

3.实验概述:方法部分
在实验方面,我们在VDW数据集,以及公开的Sintel和NYUDV2数据集上,均取得了SOTA的空间精度和时域一致性。其中VDW和Sintel为自然场景数据集。对于封闭场景数据例如NYUDV2,不使用我们的VDW数据集而只用统一的NYUDV2训练集进行训练,已经能取得SOTA的性能;而用我们的VDW数据集预训练,再在封闭场景的NYUDV2进行finetune,则能够进一步提升模型的性能表现。
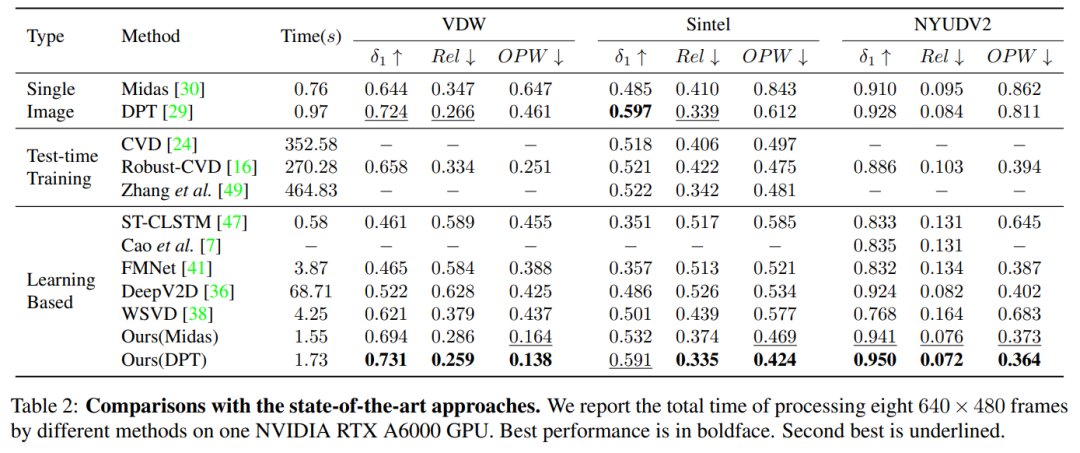
同时为了证明我们即插即用的有效性,我们采用了三个不同的depth predictor进行实验,我们的NVDS均取得了显著的提升。

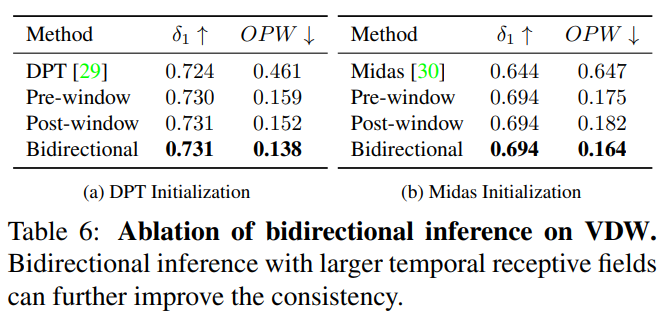
我们还通过ablation证明了双向inference的有效性。单向的(Forward或backward)预测已经能够得到令人满意的一致性,而双向inference能够进一步扩大时域感受野,提升一致性。
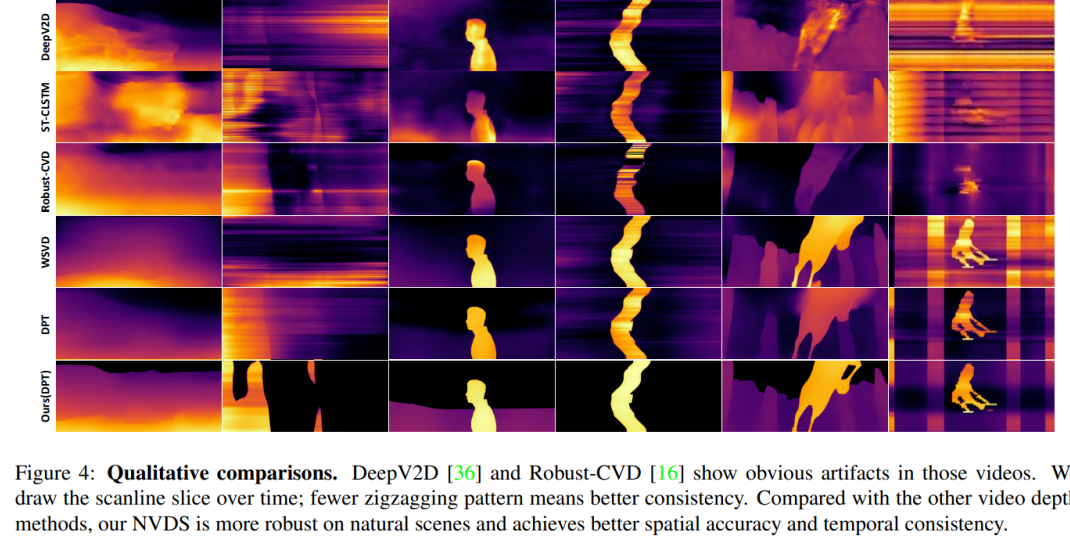
部分定性结果如下图所示,我们NVDS的方法取得了显著的提升。每组例子左侧为RGB帧,右侧为视频时域切片。切片中更少的条纹表征了更好的一致性和稳定性。更多可视化结果请参考我们的论文、补充材料、成果视频。
4. 实验概述:数据集部分
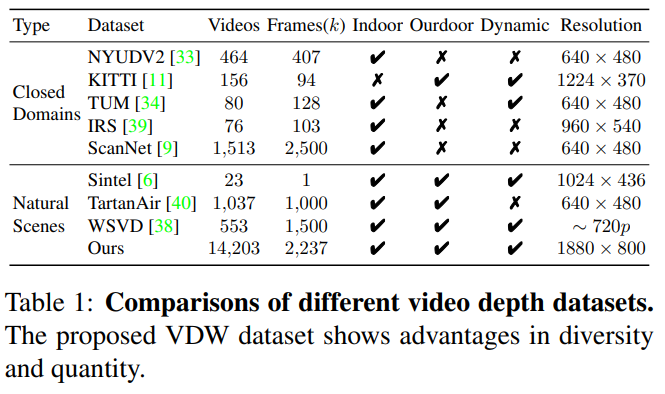
对于VDW数据集,我们比较了当前已有的视频深度数据集。我们的VDW数据集是目前体量最大、场景最丰富的自然场景视频深度数据集。
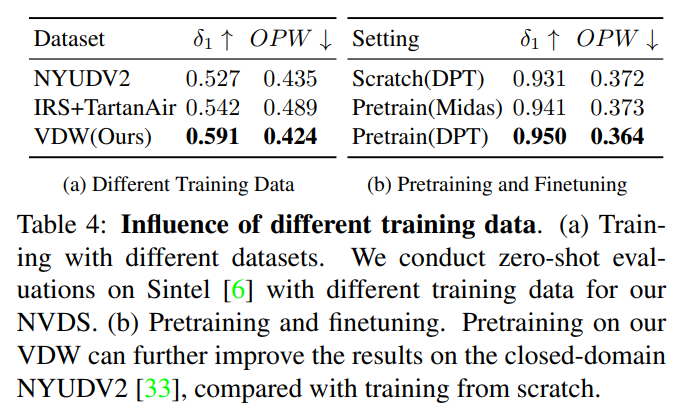
我们还探究了使用不同数据对模型进行训练的效果,由于我们的VDW数据集具有最佳的体量和场景丰富度,因此对于相同的模型,使用VDW数据集进行训练取得了最优性能。
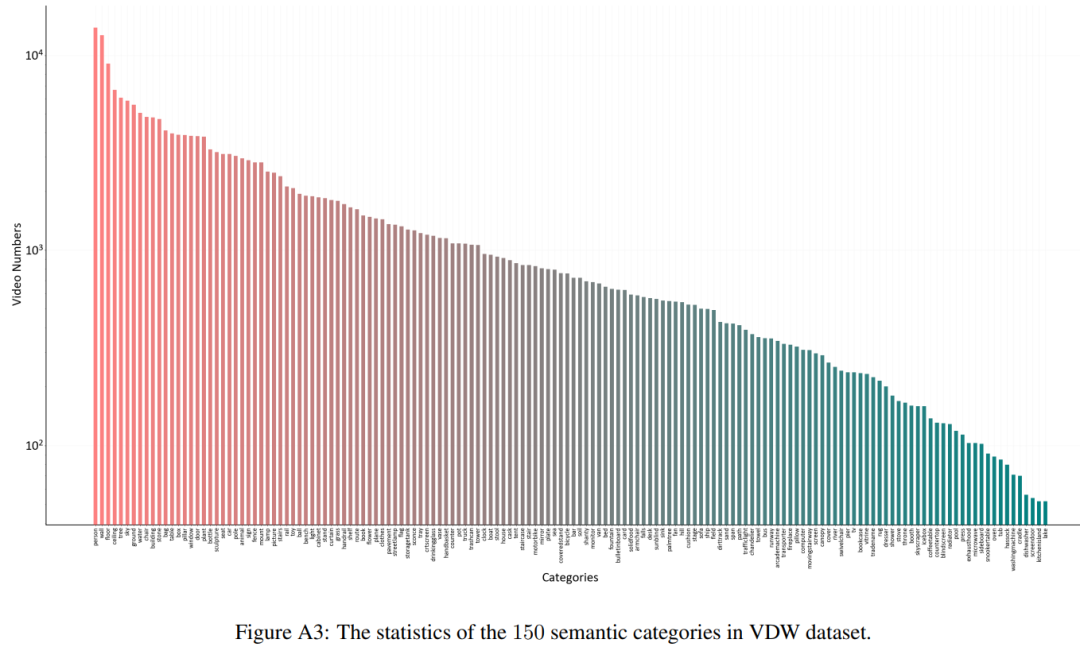
而对于数据集的统计实验,我们绘制了数据集的物体类别词云,以及语义类别统计图等。更多的数据集统计结果和示例请见论文和补充材料。

5. 代码与数据集开源
我们的代码已经开源:
https://github.com/RaymondWang987/NVDS
数据集正在搭建VDW的官方网站,并拟定相应的开源协议,准备好后会马上进行发布。我们的数据集体量较大,因此网站搭建和数据传输仍需要一定的时间,我们会对数据进行分割并逐步上传。VDW数据集可以被用于学术和研究用途,但不能用于商业用途。