有选择的后摩尔堆叠时代
台积电、英特尔等大厂近年来不断加大对异构集成制造及相关研发的投入。随着 AIGC、8K、AR/MR 等应用的不断发展,3D IC 堆叠和 chiplet 异构集成已成为满足未来高性能计算需求、延续摩尔定律的主要解决方案。
本文引用地址:不久前,华为公布了一项芯片堆叠技术的新专利,显示了该公司在芯片技术领域的创新实力。这项专利提供了一种简化芯片堆叠结构制备工艺的方法,有望解决芯片堆叠过程中的各种技术难题。堆叠技术可以提高芯片的效率,并更好地利用可用空间,进一步推动芯片技术的进步。尽管目前该专利与将两个 14nm 芯片堆叠成一个 7nm 芯片的传闻还未得到官方认可,但这一技术潜力巨大,可以为芯片制造商带来更多可能性。
后摩尔时代,堆叠已经大势。
计算堆叠需求
随着 AIGC、AR/VR、8K 等应用的快速发展,预计将产生大量的计算需求,特别是对能够在短时间内处理大数据的并行计算系统的需求。为了克服 DDR SDRAM 的带宽限制,进一步提升并行计算性能,业界越来越多地采用高带宽(HBM)。这一趋势导致了从传统的「+(如 DDR4)」架构向「芯片+HBM 堆叠」2.5D 架构的转变。随着计算需求的不断增长,未来可能会通过 3D 堆叠实现 、GPU 或 SoC 的集成。
9 月中旬根据韩国 The Elec 报道,三星电子和 SK 海力士两家公司加速推进 12 层 HBM 量产。生成式 AI 的爆火带动英伟达加速卡的需求之外,也带动了对高带宽存储器(HBM)的需求。HBM 堆叠的层数越多,处理数据的能力就越强,目前主流 HBM 堆叠 8 层,而下一代 12 层也即将开始量产。
报道称 HBM 堆叠目前主要使用正使用热压粘合(TCB)和批量回流焊(MR)工艺,而最新消息称三星和 SK 海力士正在推进名为混合键合(Hybrid Bonding)的封装工艺,突破 TCB 和 MR 的发热、封装高度等限制。
Hybrid Bonding 中的 Hybrid 是指除了在室温下凹陷下去的铜 bump 完成键合,两个 Chip 面对面的其它非导电部分也要贴合。因此,Hybrid Bonding 在芯粒与芯粒或者 wafer 与 wafer 之间是没有空隙的,不需要用环氧树脂进行填充。三星电子和 SK 海力士等主要公司已经克服这些挑战,扩展了 TCB 和 MR 工艺,实现最高 12 层。
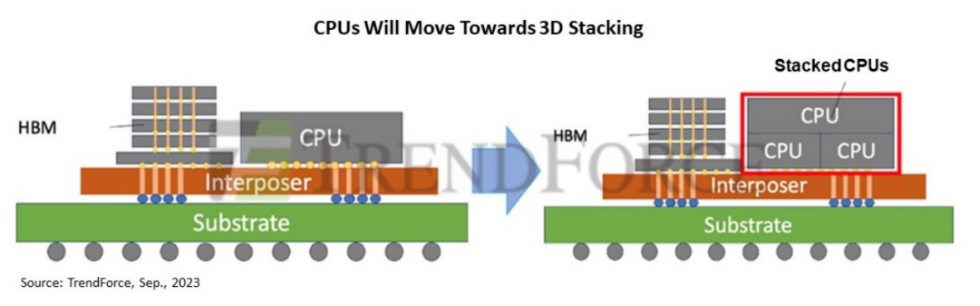
被堆叠「弃选」?
HBM 于 2013 年推出,作为高性能 SDRAM 的 3D 堆叠架构。随着时间的推移,多层 HBM 的堆叠在封装中已经变得普遍,而 /GPU 的堆叠却没有看到重大进展。
造成这种差异的主要原因可归因于三个因素:
1、散热问题,CPU 在工作时会产生大量的热量,需要通过散热器将热量散发出去,否则会导致 CPU 温度过高而损坏。如果多个 CPU 堆叠在一起,热量积聚在一起会导致散热问题更加严重,从而影响 CPU 的稳定运行。
2、信号干扰问题,在 CPU 内部,不同的电路之间需要进行大量的信号传输,如果多个 CPU 堆叠在一起,信号干扰就会更加严重,从而影响 CPU 的正常工作。
3、电路设计问题,CPU 内部的电路设计非常复杂,需要严格的电路布局和连接方式,以保证 CPU 的正常工作。如果多个 CPU 堆叠在一起,电路设计就会更加复杂,可能会导致电路连接不良或者干扰等问题。IC 设计面临 工具缺乏的挑战,因为传统 CAD 工具不足以处理 3D 设计规则。开发人员必须创建自己的工具来满足工艺要求,而 3D 封装的复杂设计进一步增加了设计、制造和测试成本。
然后也不是没有解决办法。自从 2.5D/3D 封装、Chiplet、异构集成等技术出现以来,CPU、GPU 和内存之间的界限就已经变得逐渐模糊。例如 AMD 如今在消费级和数据中心级别 CPU 上逐渐使用的 3D V-Cache 技术,就是直接将 SRAM 缓存堆叠至 CPU 上。将在今年正式落地的第四代 EPYC 服务器处理器,就采用了 13 个 5nm/6nm Chiplet 混用的方案,最高将 L3 缓存堆叠至了可怕的 384MB。
在消费端,AMD 的 Ryzen 7 5800X3D 同样也以惊人的姿态出世,以超大缓存带来了极大的游戏性能提升。即将正式发售的 Ryzen 9 7950X3D 也打出了 128MB 三级缓存的夸张参数,这些产品的出现可谓打破了过去 CPU 厂商拼时钟频率、拼核心数的僵局,让消费者真切地感受到了额外的体验提升。
GPU 也不例外,虽然 AMD 如今的消费级 GPU 基本已经放弃了 HBM 堆叠方案,但是在 AMD 的数据中心 GPU,例如 Instinct MI250X,却依然靠着堆叠做到了 128GB 的 HBM2e 显存,做到了 3276.8GB/s 的峰值内存带宽。而下一代 MI300,AMD 则选择了转向 APU 方案,将 CPU、GPU 和 HBM 全部整合在一起,以新的架构冲击 Exascale 级的 AI 世代。
AMD CEO 苏姿丰说过下一步就是直接将 DRAM 堆叠至 CPU 上。这里的堆叠并非硅中介层互联、存储单元垂直堆叠在一起的 2.5D 封装方案,也就是如今常见的 HBM 统一内存方案,AMD 提出的是直接将计算单元与存储单元垂直堆叠在一起的 3D 混合键封装方案。
CPU 如何垂直堆叠
放缓的摩尔定律,内存上的限制,例如内存墙这样的性能瓶颈,不仅在限制 CPU 的性能发挥,同样限制了 GPU 的性能发挥。苏姿丰指出,从她这个处理器从业者的角度来说,这一路线有些反常理,但从系统层面来说,她也可以理解该需求存在的意义。而 AMD 这次提出的方案,则是从计算芯片出发,将存储器堆叠整合进去。
3 月 22 日,AMD 宣布全面推出世界首款采用 3D 芯片堆叠的数据中心 CPU,即采用 AMD 3D V-Cache 技术的第三代 AMD EPYC(霄龙)处理器,代号「Milan-X(米兰-X)」。这些处理器基于「Zen 3」核心架构,进一步扩大了第三代 EPYC 处理器系列产品,相比非堆叠的第三代 AMD EPYC 处理器,可为各种目标技术计算工作负载提供高达 66% 的性能提升。
全新推出的处理器拥有业界领先的 L3 缓存,并具备与第三代 EPYC CPU 相同的插槽、软件兼容性以及现代安全功能,同时还可为技术计算工作负载提供卓越的性能,如计算流体力学(CFD)、电子设计自动化()和结构分析等。这些工作负载均是那些需要对复杂的物理世界进行建模以创建模型的公司的关键设计工具,从而为世界上那些极具创新性的产品进行测试或验证工程设计。
AMD 高级副总裁兼服务器业务部总经理 Dan McNamara 表示:「基于我们在数据中心一直以来的发展势头以及我们的多项行业首创,采用 AMD 3D V-Cache 技术的第三代 AMD EPYC 处理器展示了我们领先的设计与封装技术,使我们能够带来业界首个采用 3D 芯片堆叠技术且专为工作负载而生的服务器处理器。我们最新所采用的 AMD 3D V-Cache 技术的处理器可为关键任务的技术计算工作负载提供突破性性能,从而带来更好的产品设计以及更快的产品上市时间。」
Micron 公司高级副总裁兼计算与网络事业部总经理 Raj Hazra 说:「客户正在越来越广泛的采用数据丰富的应用,这对数据中心的基础设施也提出了新的要求。Micron 和 AMD 的共同愿景是为高性能数据中心平台提供领先的 DDR5 内存的全部能力。我们与 AMD 之间的深度合作包括为基于 Micron 最新 DDR5 解决方案的 AMD 平台做好准备,以及将采用 AMD 3D V-Cache 技术的第三代 AMD EPYC 处理器引入我们自己的数据中心,我们已经看到了在特定的 工作负载中,与未采用 AMD 3D V-Cache 的第三代 AMD EPYC 处理器相比,性能提高了多达 40%。」
一直以来缓存大小的提升都是性能改进的重中之重,特别是对于严重依赖大数据集的技术计算工作负载。这些工作负载受益于缓存大小的提升,但 2D 芯片设计却对 CPU 上可有效构建的缓存量有着物理上的限制。AMD 3D V-Cache 技术通过将 AMD「Zen 3」核心与缓存模块结合,解决了这些物理上的挑战,不仅增加了 L3 缓存数量,同时还最大程度减少了延迟并提高吞吐量。这项技术代表了 CPU 设计和封装方面的又一创新,并为目标技术计算工作负载带来了突破性性能。
英伟达的专利
早在 2017 年,英伟达就在国际计算机体系结构研讨会 (ISCA) 上展示了其 MCM-GPU 设计。英伟达计划使用多个逻辑芯片来互连大量内核,并开发具有持续性能改进的新 GPU,同时管理成本。随着 GPU 芯片越来越大,它们的成本呈指数级增长,因此制作一些相互连接的较小芯片是更具成本效益的解决方案。MCM-GPU 封装方法解决了这个问题,因为它连接多个芯片,从而提供巨大的性能提升作为回报。
芯片设计不限于二维缩放,而这正是英伟达今天所获得的专利。英伟达提出了「使用扩展 TSV 增强功率传输的面对面 die」,提出了半导体 die 的 3D 堆叠,并特别说明了使用超长硅通孔 (TSV) 增强功率传输。
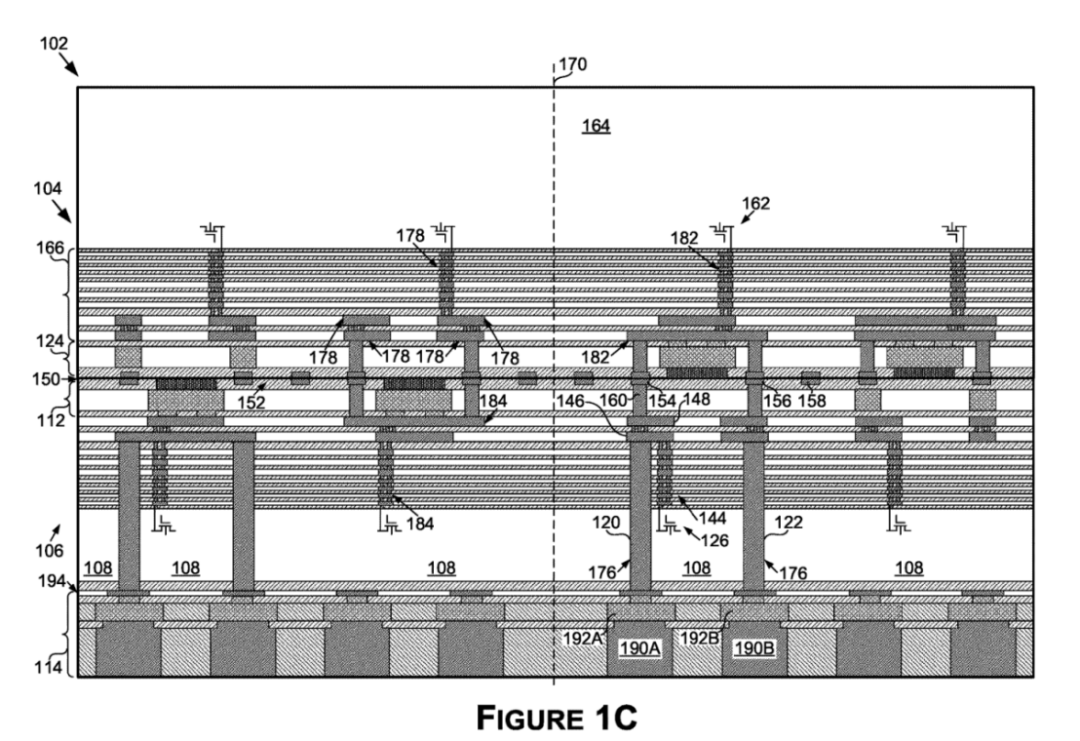
这种设置的工作方式是首先使用芯片表面上的探针垫测试基础芯片。之后,在第一个 die 的表面上形成界面层,覆盖在已经存在的探针焊盘上。最后,取出第二个 die 并将其安装在界面层上,将 die 间接口的焊盘连接到其他 die 上的互补连接。这创建了裸片的面对面安装,3D 芯片诞生了。
英伟达的专利专注于使用超长 TSV 增强电力传输。当像这样将芯片堆叠在一起时,您可以连接从逻辑(处理核心)到内存的任何东西。通常,连接内存不需要太多电力,因此提及增强的电力传输使我们得出结论,英伟达计划执行处理内核的堆叠,为 3D 处理器创建面向计算的方法。
EDA 的进击
Cadence 在 LIVE 中国台湾 2023 年用户年会上强调了其多年来在开发解决方案方面的努力。他们推出了 Clarity 3D 解算器、Celsius 热解算器以及 Sigrity Signal and Power Integrity 等工具,可以解决热传导和热应力模拟问题。当与 Cadence 的综合 EDA 工具相结合时,这些产品有助于「Integrity 3D-IC」平台的发展,有助于 3D IC 设计的开发。
Intgrity 3D-IC 平台是 Cadence 广泛 3D-IC 解决方案的组成部分,在数字技术之上同时集成了系统、验证及 IP 功能。广泛的解决方案支持软硬件协同验证,通过由 Palladium Z2 和 Protium X2 平台组成的 Dynamic Duo 系统动力双剑实现全系统功耗分析。平台同时支持基于小芯片的 PHY IP 互联,实现面向延迟、带宽和功耗的 PPA 优化目标。Intgrity 3D-IC 平台支持与 Virtuoso 设计环境和 Allegro 技术的协同设计,通过与 Quantus Extraction Solution 提取解决方案和 Tempus Timing Signoff Solution 时序签核解决方案提供集成化的 IC 签核提取和 STA,同时还集成了 Sigrity 技术产品,Clarity 3D Transient Solver,及 Celsius Thermal Solver 热求解器,从而提供集成化的信号完整性/功耗完整性分析(SI/PI),电磁干扰(EMI),和热分析功能。全新 Integrity 3D-IC 平台和更广泛的 3D-IC 解决方案组合,建立在 Cadence SoC 卓越设计和系统级创新的坚实基础之上,支持公司的智能系统设计(Intelligent System Design)战略。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。