






 技术咨询
技术咨询 代买器件
代买器件 商务客服
商务客服 研发客服
研发客服Waymo自2008年就开始研发自动驾驶,也是业内公认自动驾驶技术先行者,但在商业化道路上进展不利,只有软硬一体才是自动驾驶的出路,所以自研芯片后的Waymo或许能翻身,虽然自研芯片有点晚了。 有关Waymo的自动驾驶训练数据集(Waymo Open Dataset,简称WOD)或者说公开Benchmark有两篇论文,一篇是2020年5月的《Scalability in Perception for Autonomous Driving: Waymo Open Dataset》,另一篇是2021年4月的《Large Scale Interactive Motion Forecasting for Autonomous Driving:The WAYMO OPEN MOTION DATASET》。
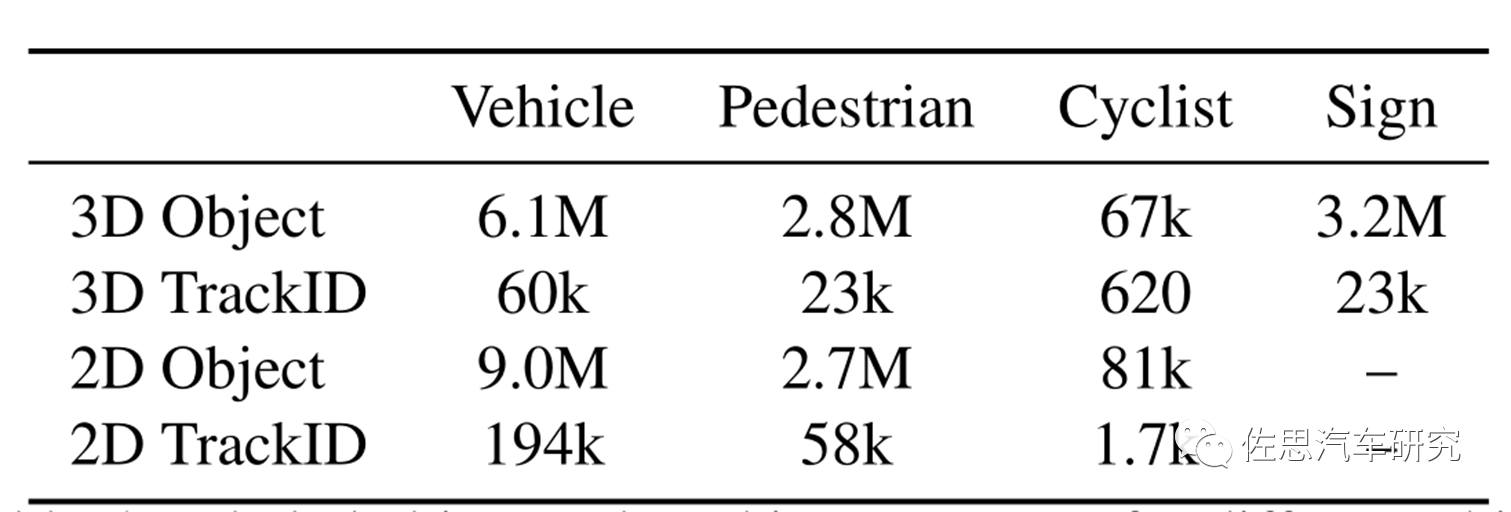
WOD也分成两部分,一部分是Perceptiondataset,有2030个场景,目前最新版为2022年6月升级的v1.4;另一部分是Motion dataset,有目标轨迹追踪和3D同步地图,有103354个场景,目前最新版为2021年8月升级的v1.1版。 谷歌举办过WayMo Open Dataset Challenge,响应者不少,3D Detection的第一名是国内知名芯片公司地平线,第二名是香港中文大学,第三名则是致力商用车无人驾驶的图森未来。2DDetection方面,图森未来、同济大学和中科院第一,地平线第二,中山大学和华为诺亚方舟实验室第三。Waymo在业内的地位可见一斑。
首先来看Perception dataset。
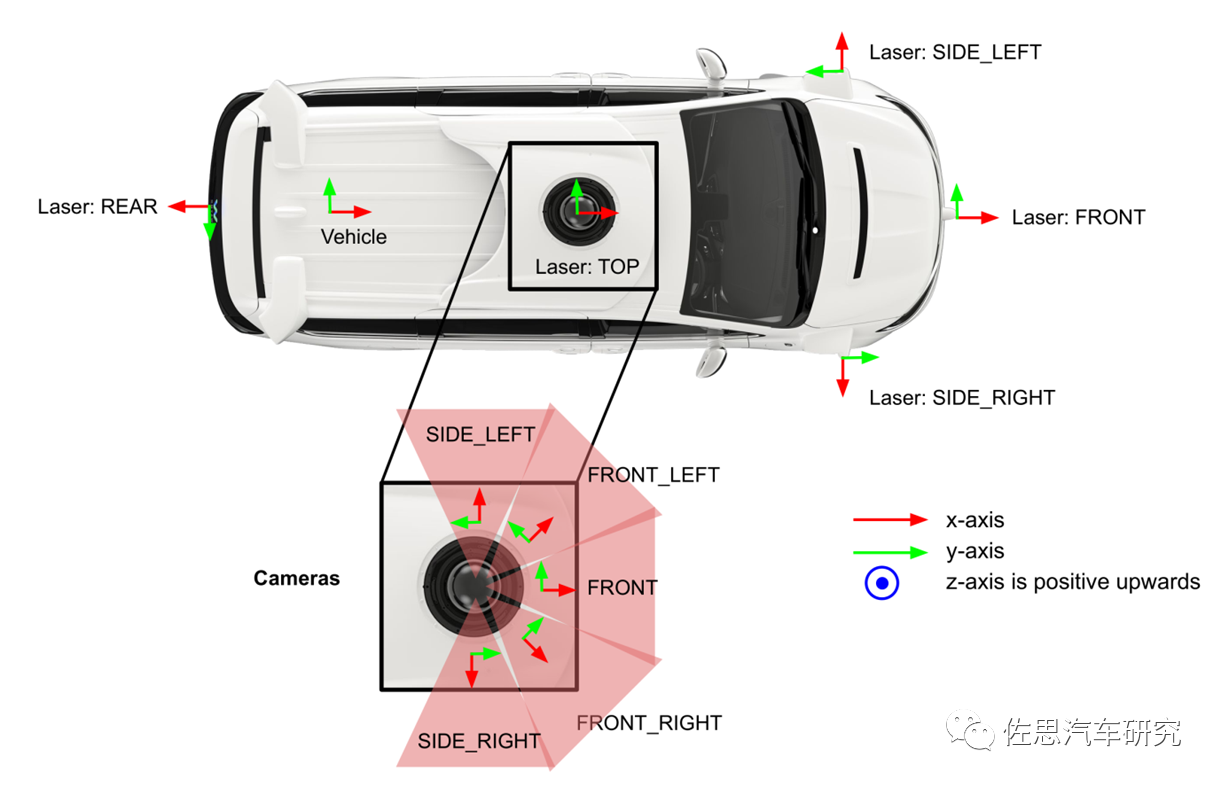
Waymo的传感器布局,有多达5个激光雷达,前面左中右各一个,车顶一个,车尾一个。5个摄像头也都在车顶。

上表的“Ours”就是Waymo的数据集,这是4个数据集的对比,KITTI用的是一台Velodyne的HDL-64E 64线激光雷达,早期产品单回波下其每秒有130万点输出,后来的HDL-64E S3双回波是220万点每秒输出。未知KITTI是用的单回波还是双回波,早期激光雷达单回波的可能性大一点。尽管Waymo用了5个激光雷达,但每帧平均点数比KITTI没高太多,并且Waymo的5个激光雷达均是双回波。

上表为Waymo激光雷达的参数,并未公布每秒输出点数,Waymo自制的激光雷达应该不如Velodyne的HDL-64E 。HDL-64E的VFOV是+2°至-24.8°,垂直角分辨率是0.4°,Waymo的VFOV是20°,如果也是64线的话,那么垂直角度分辨率应该是0.3°。

上表为Waymo 5个摄像头参数,最高只有200万像素,而Waymo声称自己的无人车用了500万像素的摄像头,并且有些媒体声称使用了14个500万像素摄像头,显然是夸张了,Waymo不会为测试数据集单独搞一套传感器配置,Waymo无人车的实际像素应该就是200万。
坐标系方面,采用右手规则。全局坐标是East-North-Up体系,车辆姿态与全局坐标系定义为4*4变换矩阵。A vehicle pose is defined as a 4x4 transform matrix from the vehicleframe to the global frame。相机坐标系方面,使用外参矩阵,即从全局(世界)坐标系到相机坐标系的变换。激光雷达使用直角坐标系。
标注方面,每一个3D物体都有7自由度的标注,包括基于中央坐标点的长宽高以及3D Box的长宽高,还有航向角。当然还有物体的ID和分类。对于鸟瞰(BEV)3D目标,设置为5自由度,不需要基于中央坐标点的长宽高。
标注方面,考虑到了人工标注费时费力,和华为一样,Waymo也有半监督学习,也就是伪标签学习,也有叫自动标签系统,这些非人工标注的自然是伪标签,但其也并非完全的毫无根据。首先,在人工标注真值的数据上训练模型,然后使用经过训练的模型来预测无标签数据的标签,从而创建伪标签。此外,将标签数据和新生成的伪标签数据结合起来作为新的训练数据。大量使用自动标签或伪标签就是半监督学习。这样的结果肯定不如全人工标注来得好,可是就算Waymo财大气粗也得考虑成本,这种3D目标标注是需要标注工具的,且异常枯燥无味,至少要理科院校的大一学生才能胜任,同时还要心细,不嫌枯燥,这种人是不好找的,成本不低。

Waymo的3D自动标签管线
与其他家不同的是Waymo使用非板载系统进行自动标签,Waymo认为板载系统资源受到限制,效果不会太好,所以称之为《Offboard 3D Object Detection from Point Cloud Sequences》。

感知WOD有2030个场景,分训练和评估两部分,主要在凤凰城、山景城和旧金山采集,大部分为白天,天气晴好。训练集解压缩后大小为812.7GB,验证集为204.9GB。
感知WOD分4大类,3D目标检测与追踪,2D目标检测与追踪。
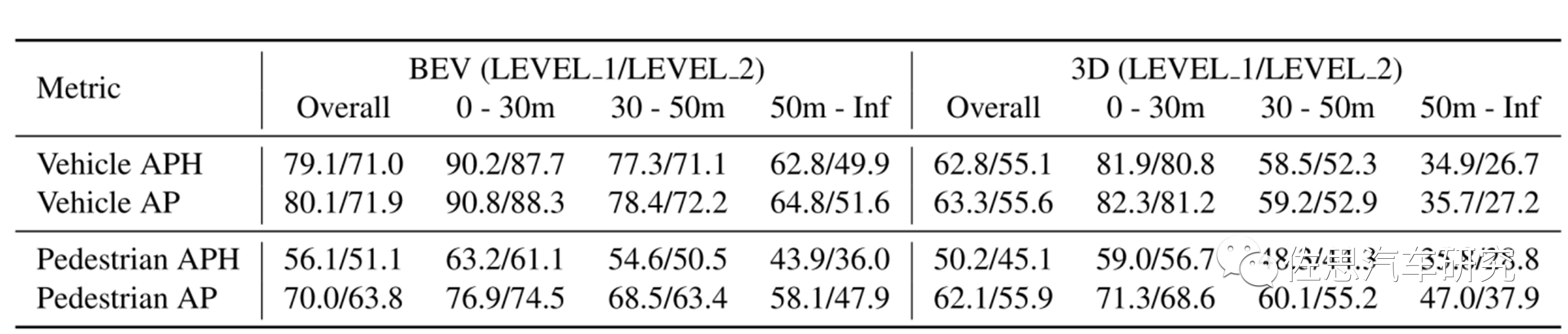
单一目标的测试基准线

多目标包含追踪的测试基准线
高于基准线就可算优秀,Waymo对车辆检测IoU设置为0.7,行人为0.5,行人的阈值较低,这也可看出行人检测难度很高。 WOD的感知测试数据集平平无奇,不过动作预测测试数据集可谓独树一帜,非常有水平。它包含103,354 segments,每个segment长度为20s,10Hz,包含object tracks和map data,这些segment又被分成9s的窗口,包括1s历史和8s未来。覆盖6个城市,1750公里的里程,570小时的驾驶时间。
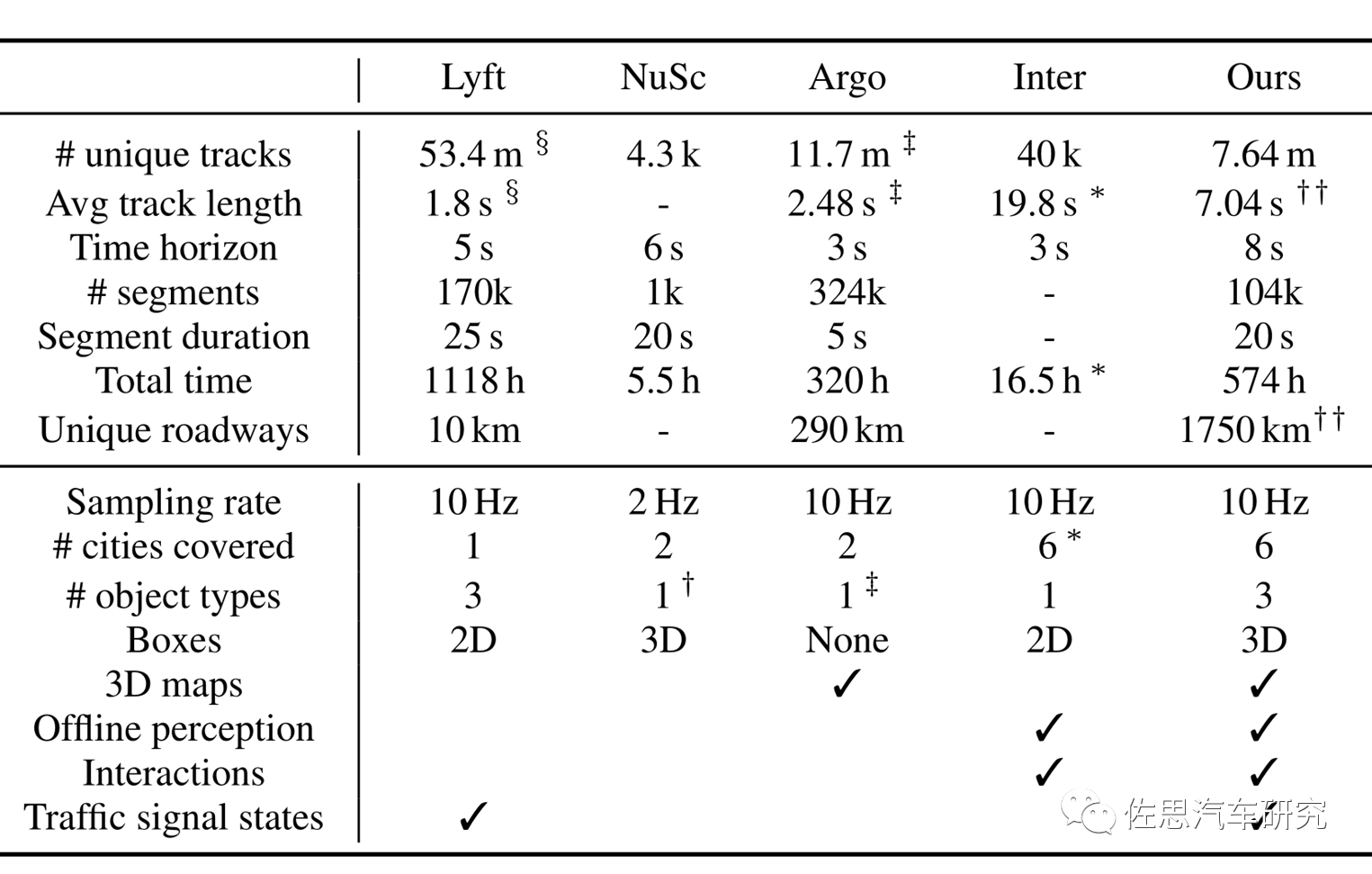
包含场景预测和动作预测的数据集对比,“Ours”就是Waymo,Lyft虽有1118小时,但只有10公里,样本量太少了。Argo的时间太短,只有5秒,前后关联性不明显,缺乏预测的意义。有3D Box标注的只有Waymo和安波福,但安波福的帧率太低了,只有2Hz,就算市区低速场景也太低。综合看只有Waymo的场景预测和动作预测的数据集才真正有意义。Waymo覆盖六个城市,包括凤凰城、旧金山、西雅图、山景城、底特律和洛杉矶。 对于无人驾驶来说,最难的就是预测行人或车辆的下一步轨迹,即行为预测或动作轨迹预测。这已经超越了感知那个地步,但需要良好的3D感知和轨迹追踪能力做基础,行为预测通常都使用LTSM,而不是CNN。绝大多数数据集的核心还是感知,而Waymo要更进一步。

数据集中训练占70%,包括未来轨迹真值,validation占15%,测试占15%。每个场景有20秒时间,Scenario代表一个场景,也就是一段时间内的交通情况,包括自动驾驶车自身,其它的交通参与者(车辆、行人),以及交通灯在20s内的轨迹和状态,同时还包括了道路信息即地图。也就是说Scenario是一条数据的最小单元。从20秒内抽出9.1秒的时间窗口,频率为10Hz,即91帧,10个历史样本,1个现在时样本,80个未来帧,也就是说要预测未来8秒的行动轨迹,Waymo认为预测时间越长越安全。 标注系统和感知数据集一样,也是别出心裁的自动标签系统。论文为《Auto4D: Learning to Label 4D Objects from Sequential Point Clouds》所谓4D就是加了时间戳。顺便说一句,这篇论文不是Waymo的,而是Uber和多伦多大学的。
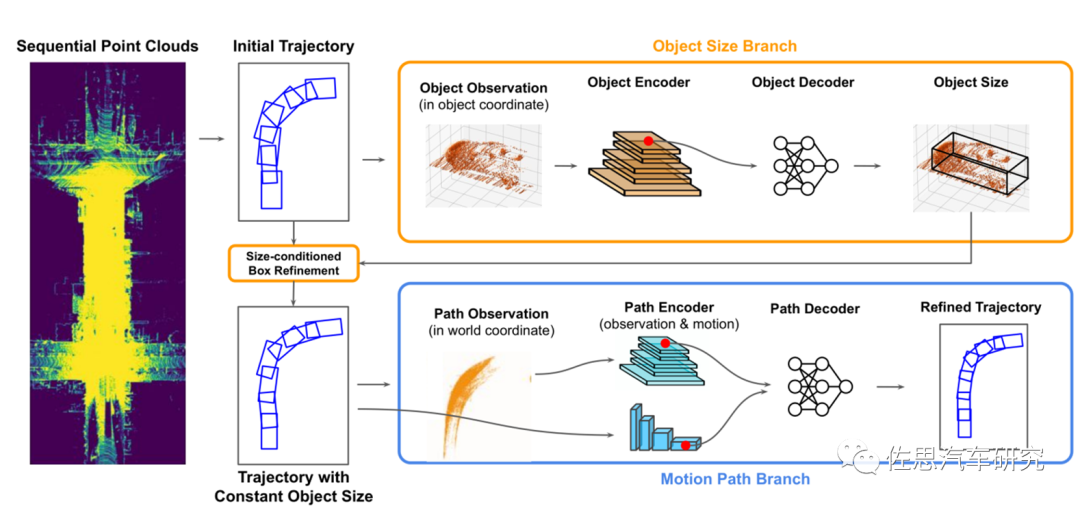
4D自动标签系统
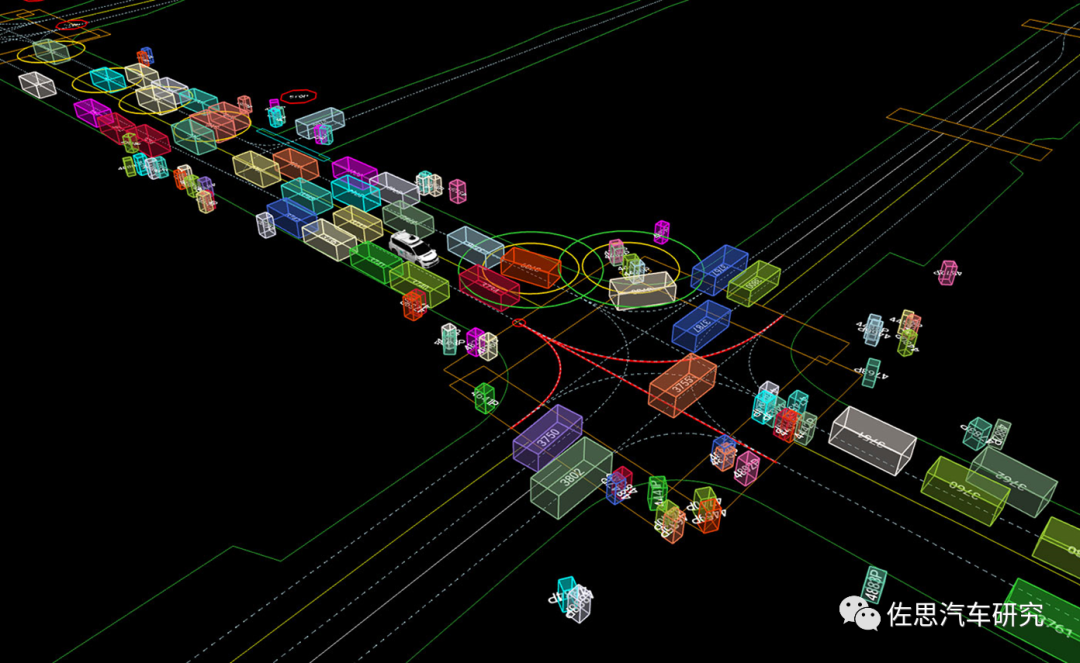
Waymo Open Motion Dataset示例
预测评价指标有平均位移误差:Average displacement error(ADE),每个预测位置和每个真值位置之间的平均欧式距离差值。
终点位移误差(Final displacement error,简称FDE):终点预测位置和终点真值位置之间的平均欧式距离差值。
空间重叠率(Overlap Rate):总重叠数与进行多模态预测次数的比值。一个样本e对应的一次多模态预测中,最高置信度的预测里,每一个时间步step,一个对象与另一个真实情况或该预测情况的其他对象的3D边界框存在重叠,则重叠数加1。
漏检率(Miss Rate,简称MR):整个数据集在t时刻的错误比例。对于一个样本,给定t时刻,所有K个联合预测,都存在某个对象a的位置,其指示函数IsMatch(.)为0,则该时刻MR为1。
平均精度期望(mAP):先对每个对象的真实轨迹按定义的运动方向分为8类(buckets),用上面的IsMatch(.)来定义TP,FP等(但是对于都Match的情况,仅认为置信度高的为TP),在各类内按置信度排序TP、FP后,根据各个TP的准确度(precision)求平均(置信度越高的TP排在前面,对AP的影响越大),再对各个类别的AP求算数平均。
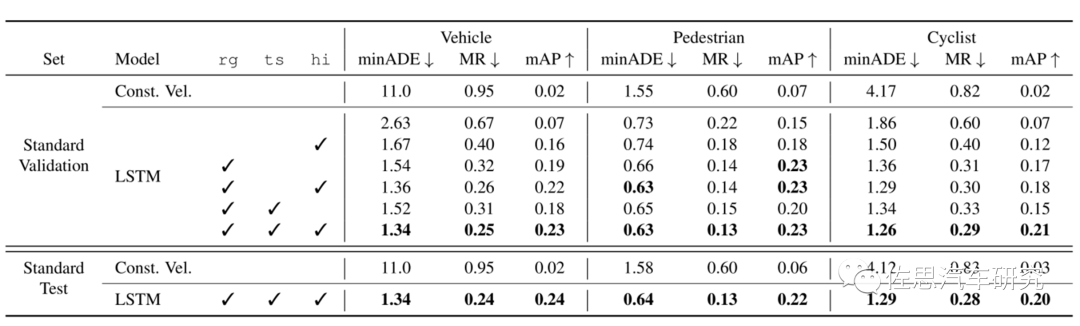
Waymo的Baseline基线成绩,rg代表道路拓扑,ts代表交通信号,hi代表high-order interactions,rg基本可看做高精度地图,这对模型预测很有帮助。mAP的值远低于3D目标检测,显然预测目标轨迹的深度学习还非常不成熟。
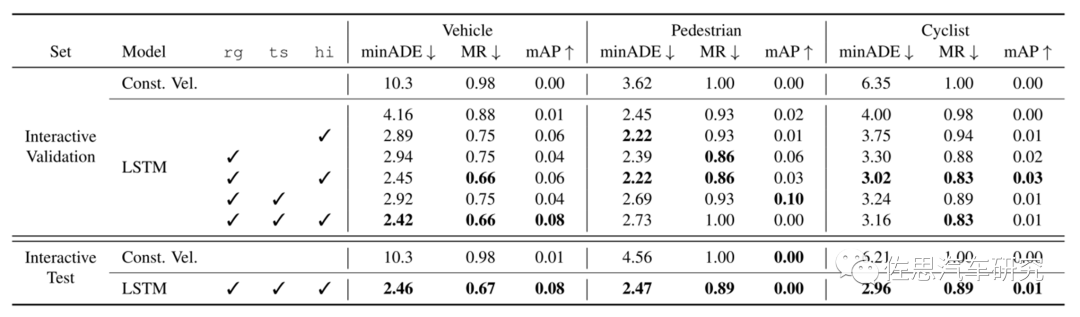
交互式interactive的成绩就更差了,显然预测目标轨迹的深度学习还有很长的路要走。
相关文章









