英特尔的硅光黑科技,怎么颠覆HPC和AI?
在前阵子的2024年光纤通信大会(OFC)上,英特尔开始发力硅光技术,首次推出与英特尔CPU共同封装的完全集成OCI(光学计算互连)芯粒,它是高带宽互连的一次重大进步。
在AI大模型到来的如今,世界越来越依赖于异构计算平台。随着工艺节点缩小、时钟频率提高和 SoC 尺寸增大,传统电气互连的能源和延迟成本已经成为一大问题。而现在,光学计算互连芯片将彻底改变数据中心和HPC中AI负载的高速数据处理。
那么,在OCI芯粒背后有哪些关键点和技术值得关注?英特尔研究院副总裁、英特尔中国研究院院长宋继强进行了一次分享。
为什么一定是硅光
在AI大模型来临之际,数据中心的算力开始膨胀,对于内存带宽也提出了巨大要求。
宋继强解析表示,目前,许多AI应用依赖于在数据中心训练和部署的大模型,以及派生到边缘服务器和服务集群的小规模模型。这些大模型对计算密度有极高要求,也对内存提出了大容量和高带宽的需求。传统存算比为读取一次进行几十到上百次计算,而现在几乎达到了算一次存一次的地步,甚至还需要做一些调整,这大大提高了对内存带宽的要求。

由于模型规模巨大,很难在单台服务器节点中部署和连接,通常需要一个机架,或者跨机架连接,形成数据中心内的服务器集群。然而,AI应用对存算比的高要求导致频繁访存,因此内存通道及其延迟直接影响着未来的大规模应用服务,不论是基础大模型还是行业特定模型。当前,尽管大家主要集中在服务器内部署模型,但一旦应用全面铺开,调用云端、边缘或特定领域内的模型,并发量将大幅增加。
这就要求行业探索新方法,在提高算力和存储密度的同时,降低功耗和缩小体积,从而在有限的空间内容纳更多的计算和存储芯片,以满足未来AI应用的需求。
在此之前,铜线被广泛用于芯片间互连。铜线具有高效、高速和低功耗的特点,但其传输距离有限。当仅在一个机架内连接时,使用铜线或金属线没有太大问题。然而,当需要跨机架甚至在整个数据中心内形成集群时,问题就显现出来了。由于集群占地面积较大,跨多个机架的连接线长度需要达到几十米甚至上百米。这种情况下,虽然仍可以使用铜线,但功耗会显著增加。为了在长距离下保持信号的完整性,需要提高驱动电压,这对于节能的要求来说并不是一个理想的方案。
硅光技术在节能方面具有显著优势。英特尔则将硅光技术整合了两项关键技术,有效地解决上述问题:一是可以利用半导体,特别是硅来发光和检测光,从而实现将其与现有基于硅的生产流程集成的目标;二是大规模集成电路可以在硅上与其他非硅晶体管或电路形式进行大规模集成。
此次英特尔展示的OCI芯粒,将半导体激光发射设备和硅光放大设备全部集成在一个晶圆上,这是其独特之处。与同类产品相比,这一优势使其体积更小、功耗更低。未来在实现规模化生产后,良率将提升,成本也会下降。
降低数据中心的I/O电力消耗
随着AI大模型规模的扩大,模型训练和推理需要在多个不同节点上进行。AI大模型的参数量增长遵循规模定律,即模型规模越大,同样数据集上的训练效能越好;模型尺寸不变时,训练数据规模越大,性能也会提升。规模定律对计算、存储及I/O通信的要求越来越高。
过去二三十年来,计算中用于I/O的电量需求不断增加。如果按照现在的增长速度继续下去,现有技术将会消耗掉所有供给机架的电源,使得计算和存储芯片没有足够的电力进行读写操作。这就是为什么必须采用新的技术方案来降低I/O部分的电力消耗,防止其持续上升。
为什么不能完全依赖电气I/O来解决这个问题?对数据中心机架来说,有多个服务器节点,但供电则是有限的。这些机架不仅为计算和存储芯片供电,还需要为其他I/O设备供电。因此,真正分配到每个芯片上的电量会减少。由于总电源供给和机架优化的限制,供给芯片的电量增长速度是有限的,不能快速增加。
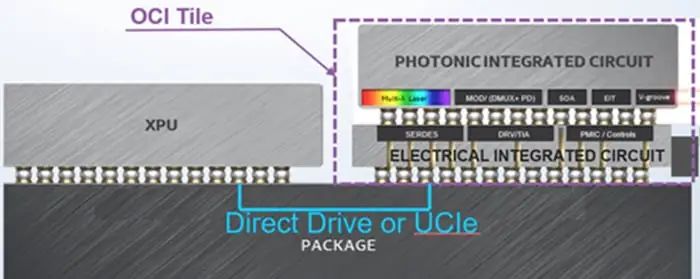
此次英特尔发布的硅光集成技术,OCI芯粒达到了光电共封装的层面。这种光电共封装技术将一个硅光子集成电路(PIC)与一个电子集成电路(EIC)一起封装在一个基板上,组成了一个OCI芯粒,作为一个集成性的连接部件。这就相当于一个芯片(die),可以与xPU、CPU、GPU或其它SoC一起封装。
在2024年光纤通信大会上,英特尔演示了这样一个系统,其中两个数据中心的CPU互相发送和接收数据。在数据中心的CPU旁边,英特尔封装了一个OCI芯粒。OCI芯粒将数据中心CPU发出的所有电气I/O信号转换成光信号,通过光纤在两个数据中心的节点或系统间进行互传。

该技术采用8对光纤,功耗仅为5 pJ/bit,比可插拔光收发器模块的15 pJ/bit功耗降低了3倍。目前,双向数据传输速度达到了4Tbps,上层传输协议兼容PCIe 5.0,单根光纤上间隔 200 GHz 的八个波长的光谱。它还使用八对光纤支持64个32 Gbps数据通道,每个方向可达100米。
100米以内的通信,都可以用硅光
根据宋继强的介绍,一套完整的硅光系统包括激光发生器、光波导、调制器、复用、解复用设备以及集成电路芯片,这套完整的单元确保硅光通信与电信号的集成,它们各司其职:
激光发生器发出激光后,需要在芯片上接收和导向不同的地方;光波导起到将光线在晶圆上导来导去的作用;调制器则将信号调制到原本纯粹的光波上;而复用和解复用设备在传输过程中处理不同波段的混合信号;集成电路芯片还需进行信号接收、放大和调制等操作。
在100米以内,光纤传输非常有效且节能。对于更长的距离,虽然需要增加中继设备,但依然可以实现,因为电信行业的底层技术依赖光纤传输。对于数据中心及大规模模型训练的集群,光纤传输尤为适用。
目前,英特尔希望将硅光集成技术应用在100米以内的通信中。对于更长距离的通信,可以采用市面上已有的可插拔光收发器,因为它们的驱动能力更强,但尺寸也更大。
从OCI芯粒的整个应用来讲,应用领域包括通信和计算,它可以与CPU、GPU等计算芯片封装在一起,实现计算与通信的紧密集成。通过硅光集成和先进封装技术,英特尔能够实现更高密度的I/O芯粒,并与其它xPU结合,形成多种不同类型的计算加互连的芯片种类,具备广阔的应用前景。
关于OCI I/O接口芯粒的性能演进路线图,当前英特尔的技术方案可实现32Tbps的传输速度。这主要依靠稳步提升以下三个方面的指标:
一是在一根光纤内,可以分为多少不同的波段(不同颜色的光),目前稳定的技术是8波段;
二是在每个波段的光内的数据传输率,即调制上的数据率,目前为32Gbps;
三是可以同时放置多少对光纤而不互相影响,目前为8对。
展望未来,英特尔会通过保持8种不同的光波段不变,将每个波段的数据传输率提升至64Gbps,传输速度即可翻倍至4Tbps。再进一步,通过增加光波段数量至16种,不同颜色的光数量翻倍后,传输速度将达到8Tbps。
不可忽视的晶圆优势
事实上,业界并不只有英特尔一家在做光I/O,那么英特尔的差异化优势在哪?
宋继强则表示,英特尔的差异化优势主要体现在将高频率的激光发射器和硅光放大器集成在晶圆上。两项核心技术都是在晶圆级制造完成的。英特尔能够量产这种高集成度的激光器,其优势在于使用普通光纤即可传输,而其他方案仍需要专门的光纤来保持偏振光特性,成本高且缺乏规模化部署的案例。
从制造工艺上来看,现在的OCI芯粒包含两块,包括一个带有片上密集波分复用(DWDM)激光器和半导体光放大器(SOA)的硅光子集成电路(PIC),以及一个用于控制硅光子集成电路和连接主机的电子集成电路(EIC)。
通常而言,PIC使用的制程相较于EIC更为成熟。这是因为EIC的制程取决于其需要满足的计算或信号传输要求,它必须与支持的主芯片(如CPU和GPU)的制程接近并对齐。例如,如果CPU和GPU都达到了7nm和5nm制程,EIC的工艺也不能落后太多,否则主频、功耗和密度等性能指标将无法满足要求。因此,EIC需要采用相对较为先进的制程节点。相比之下,PIC的制程要求并不那么严格,它并不一定要达到与EIC相同的级别。当然,PIC也会追求小型化,但其首要目标是保证足够的效率。因为PIC并非在晶圆上制作晶体管,而是制作光相关的器件,这些器件需要保持一定的尺寸才能达到最佳效果,否则会产生损耗。
目前,英特尔已在数据中心中采用可插拔方式部署了800万个硅光集成电路,每个电路集成了4个激光器,总计3200万个片上集成激光器在正常运行。根据时基故障率(FIT)评估,这些激光器的可靠性极高,FIT值小于0.1,即在10亿个小时内发生错误的次数少于0.1次,相当于100亿小时才可能出现一次错误。
不止如此,英特尔正在投入研发新的硅光子制造工艺节点,该节点将实现领先的器件性能提升、更高的密度和更好的耦合性,并大幅提高经济效益。英特尔将继续改善片上激光器和光收发器(SOA)的性能、成本和可靠性。目前的数据显示,在数百万个器件上,英特尔激光器的时基故障率(FIT)小于0.1。我们制定了积极的路线图,通过提高线速率、每条光纤的波长数、光纤数量和偏振模式,有望扩展未来几代OCI芯粒的性能,打造出带宽达32Tb/s的器件。
英特尔正逐步将这项技术推向产品化,并致力于提供高稳定性和高可靠性的光电接口解决方案。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。