基于统一BEV表征的多任务多传感器融合技术
为了实现多传感器数据的统一表达(Unified Representation),以前常规的方法:
1)Lidar-To-Camera: 将激光雷达点云投影到图像上,使用2D CNN算法来完成数据处理。它会造成严重的几何扭曲(如下图a),影响3D Object Recognition等Geometric-Oriented任务的效果。
2)Camera-To-Lidar: 用Semantic Labels、CNN特征等信息增强点云,然后使用LiDAR-based Detector来预测3D Bounding Boxes。这种Point-Level Fusion的方法丢失了语义信息,在Semantic-Oriented任务中表现不佳(如下图b)。

BEV Fusion Method
BEVFusion在BEV空间实现了统一的多模态特征表达,同时保留几何结构和语义信息。
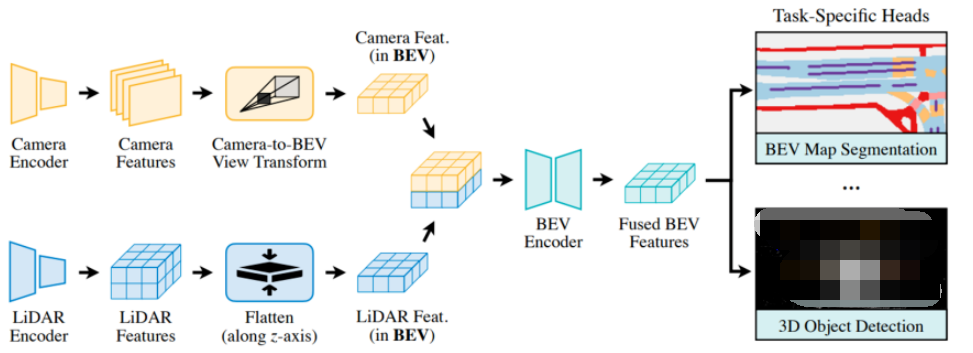
BEVFusion对不同模态的输入采取不同的编码器(Encodes)来提取Features,这种方法既保留了几何信息,又保留了语义特征信息;然后使用Fully-Convolutional BEV Encoder融合多模态的Features,缓解不用特征之间的局部偏准(Local Misalignment);最后添加一些特定Head来支持不同的3D场景理解。
BEVFusion优化后的BEV Pooling实现了40x的速度提升;它比Camera-Only的模型实现了6%的mIOU提升,比Lidar-Only的模型实现了13.6%的mIOU的提升。
Camera-to-BEV Transformation
Camera-to-BEV的变换首先要解决每个像素的Depth问题,文中采用了与论文LSS(Lift, Splat, Shoot)的方法来预测每个像素的离散深度分布。
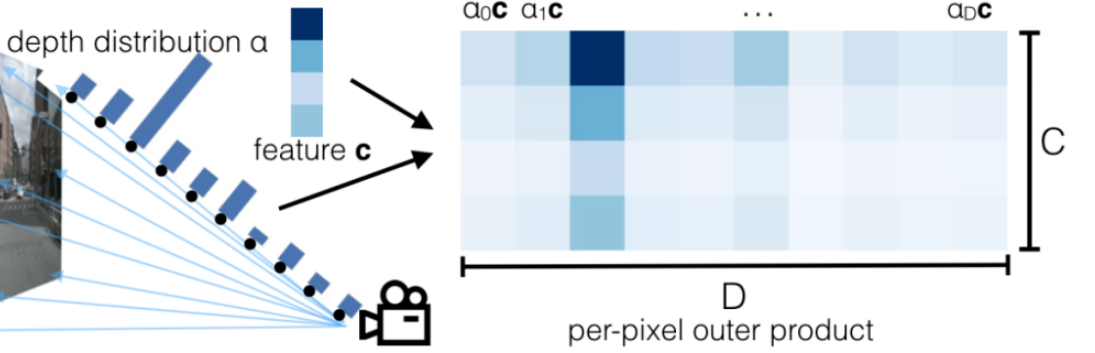
如下图所示,对每个Feature Pixel沿射线假设D个离散点(每个像素对应D个空间位置),每个离散点的可能性对应一个归一化的概率。
所有的Camera特征组合在一起,形成NHWD的Camera Feature点云,N是Camera的个数,HW是每个Camera Feature Map的大小。
沿着x,y两个方向,按照rxr的BEV网格,使用BEV Pooling对Camera Feature点云进行聚合量化。
最后,沿z轴Flatten这些特征。
这个过程中的BEV Pooling耗时严重,作者提出了Precomputation和Interval Reduction解决这个问题。
Precomputation

相机的外参是固定的,内参也是固定的,相机的射线上采样的D个离散点的采样间隔也是已知的,因此Camera Feature点云的每个点的x和y坐标是固定的,每个点在哪个BEV Grid中也是不变的。因此可以通过预计算的方式提前计算好,之后直接用即可。
Interval Reduction
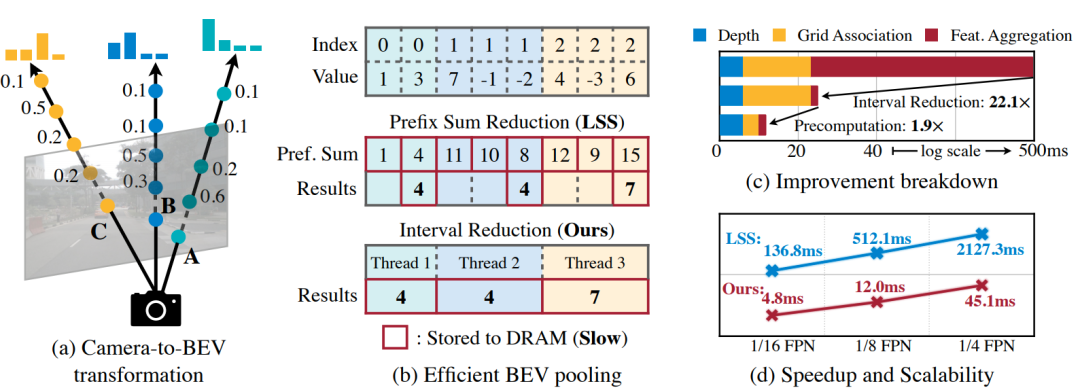
LSS使用Prefix Sum计算每个BEV Grid的聚合结果。
如上图所示,index是网格的编号,BEV Pooling的目标是将相同index的Value加起来,即将同一个网格内的特征聚合在一起。
Pref.sum是一个累加和。1=1,4=1+3,11=1+3+7,10=1+3+7+(-1),…
Pref.sum只是一个中间结果,用来辅助计算最终的聚合值。在Index变化时,减去前一个index的Pref.sum值,得到聚合结果result。
LSS的Prefix Sum可以看做是单线程的计算过程,本文直接使用Specialized GPU Kernel对多个BEV Grid独立并发计算,没有计算和存储前缀和的开销,大大加速了计算过程。
优化后的BEV Pooling将Camera-To-BEV Transformation提升了40倍,Latency从500+ms降低到12ms。
Fully-Convolutional Fusion
Lidar和Camera的BEV Features可以简单的用Elementwise Operator(比如Concatenation)来做Fusion。
由于Depth估计的误差,Lidar BEV Features和Camera BEV Features可能会存在Spatially Misaligned的问题,因此需要Convolution-based BEV Encoder来解决这类问题。
class ConvFuser(nn.Sequential): def __init__(self, in_channels: int, out_channels: int) -> None: self.in_channels = in_channels self.out_channels = out_channels super().__init__( nn.Conv2d(sum(in_channels), out_channels, 3, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(True), ) def forward(self, inputs: List[torch.Tensor]) -> torch.Tensor: return super().forward(torch.cat(inputs, dim=1))
效果测试
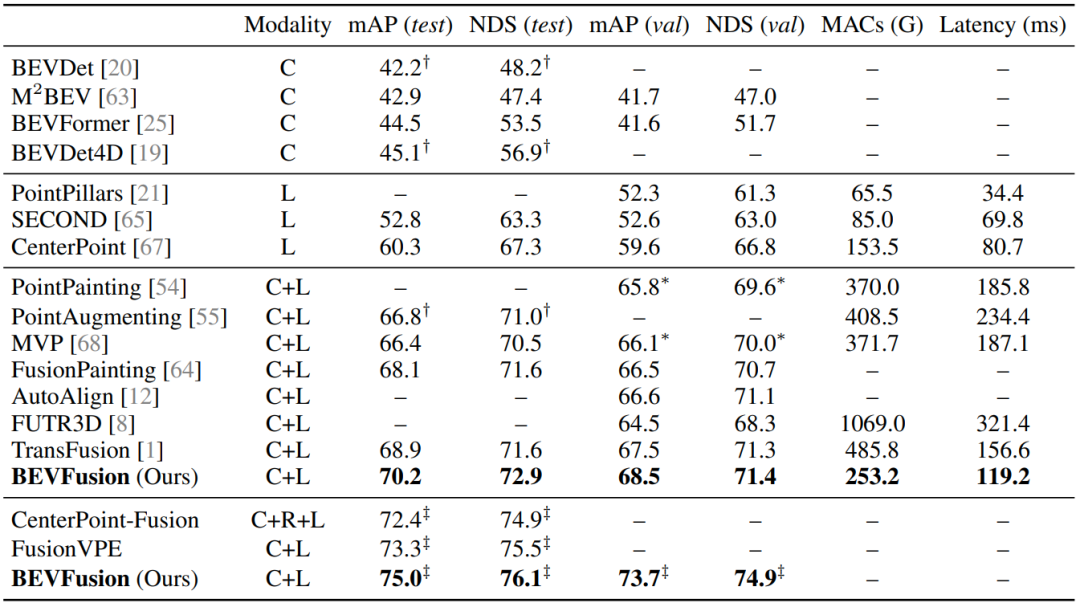
C是camera模态,L是LiDAR模态,MACs用于评估计算量,Latency是延时,BEVFusion结合了Camera模态和LiDAR模态,达到了SOTA,并且计算量和Latency也比较低。
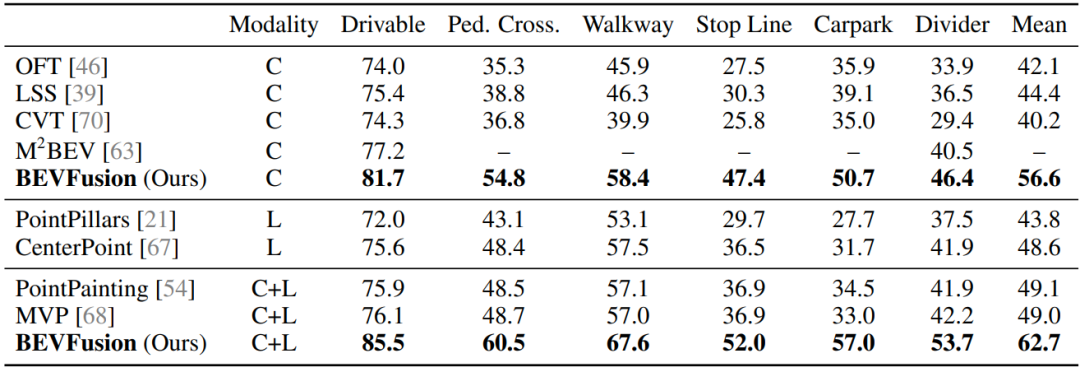
在nuScenes的BEV Map Segmentation中,BEVFusion达到了SOTA,并且对不同的地图元素的Segmentation Performance都有提升。

在晴天、雨天、白天、夜晚场景下,BEVFusion都有不错的表现。
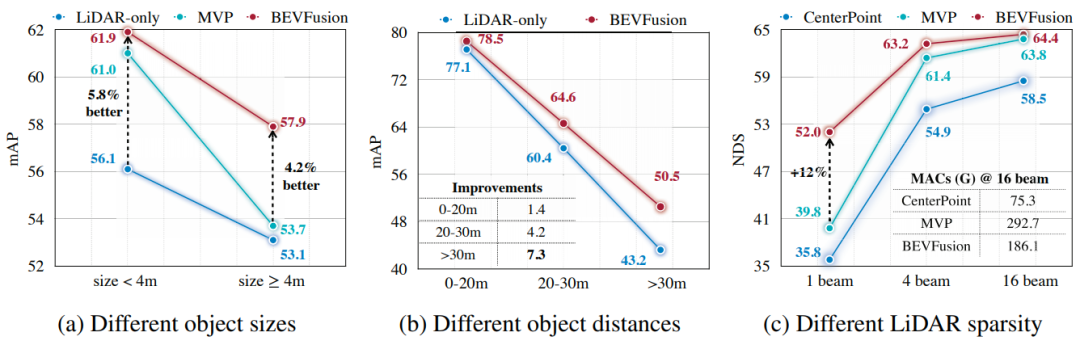
BEVFusion对于大物体、小物体、远处的物体、近处的物体的Performance都有提升;并且它在稀疏的Lidar波束上仍有不错的表现。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。