剖析Imagination的A-Series GPU新架构:和高通Adreno和Arm Mali比比
这次的产品发布颇令人意外之处在于,实际上Imagination于2017年才宣布推出最新的GPU架构"Furian"——这个架构的正式版本,即PowerVR Series9XT则是到2018年年底才出现的。在Imagination的常规操作中,某个弹性架构实际是可以应用多年的。比如Rogue架构(最著名的产品就是苹果的A系列SoC)沿用了将近7年时间,Furian才诞生。
所以A-Series的出现,很有Imagination内部“革新”的意味,这不仅体现在性能方面相比前代的飙升,以及架构层面(A-Series产品的架构名称似乎叫做Albiorix,不过Imagination并没有在会上提过)和市面已有GPU竞品的很大差异,还体现在Imagination PowerVR产品执行副总裁Steve Evans表示明年、后年还会相继有B-Series、C-Series这样的新品问世,而且预计每年性能攀升30%——这在现如今的移动GPU行业并不是小数字,一年一步进也不像Imagination往常的风格。
抛开私募基金凯桥收购Imagination之类的问题不谈,我们期望通过这篇文章,对A-Series架构层面的部分剖析,来理解Imagination现如今和过去究竟发生了多大的变化,以及尝试推断这种变化的原因在哪里。

A-Series的“性能暴涨”
首先还是简单回顾一下这次发布的新品是什么,以及相比前代和竞品,外显的性能与能效差异如何。按照Evans的说法,A-Series是耗费超过2年时间打磨的——这恰在Furian诞生时间点前后,或许A-Series的内部变革计划是从那个时间就提上日程的。A-Series GPU IP总共三个系列,分别是AXE、AXM和AXT,简单说就是低中高端的差别,这和PowerVR过往产品的定位传统一致。值得一提的是,其中定位小尺寸、低功耗的AXE系列应该是基于前代的Furian架构——不过它同样应用了最新的部分技术。
Evans表示,A-Series核心代表的是迄今为止最快的GPU核心(fastest GPU cores ever created),无论是相比前代产品还是市面上既有的其他竞品,且在PowerVR家族内是一次超乎寻常的飞跃(exceptional leap)。其中AXT系列“快了2.5倍”,这个时代的性能上升2.5倍仍然是个惊人的数字。这里的比较,针对的应该是上一代的PowerVR Series 9,但Evans并没有说是Series 9中的哪个系列或哪个产品。

从Imagination后续在技术对比中的更多解读来看,2.5倍指的的应该是相比更早的Rogue架构(Series 9既有采用Furian的型号,也有采用Rogue架构的型号)。在更多的性能对比数字方面,Evans还提到了ALU单元数量增加4倍,AI性能提升8倍,功耗则低了60%——通常功耗的降低数字是指,在达到与前代相同性能的同时,功耗降低了这么多。
在相对具体的产品层面,Evans总共列出了四款产品,分别是AXT 64-2048,AXT 32-1024,AXM 8-256,AXE 1-16。前面的字母是对应上述产品系列的,后面的数字实际也很容易理解。
比如AXT 32-1024,这里的“32”指的是纹理填充率(texture fill rate)达到32 GigaPixel/s(实际上这里的Pixel应该是指Texel,即每个时钟周期采样32个双线性过滤texel);1024则指1.0 TeraFLOPs(也就是每个时钟周期1024次FP32 FLOPs);另外,相关的AI性能则是在这个数字的基础上翻4倍,AXT 32-1024的AI性能就是4 TOPs(INT8推理)。

这样一来,其他几款产品的性能参数以此类推也就大致很清楚了,比如上图的AXT 64-2048。AXT 64-2048显然是这个家族中性能最彪悍的一款,Evans表示,这款产品“为Imagination开启了全新的应用市场,包括数据中心应用”;而AXT 32-1024定位于高性能图形计算,“可应用于未来几年的高端智能手机中”。
AXM 8-256用Evans的原话说是一款中端定位的“sweet spot”GPU,这句话应该是指其能效比在A-Series家族中可以达到最佳,应用场景包括了汽车、数字电视、机顶盒、平板等;AXE 1-16是A-Series家族中最小的一款。
如果我们单看这些数字,实际就已经是不错的成绩了。但没有量级概念的话,还是需要对比一下竞品。Evans也在现场对比了同代竞品的实际性能、功耗、面积,也就是PPA。[!--empirenews.page--]
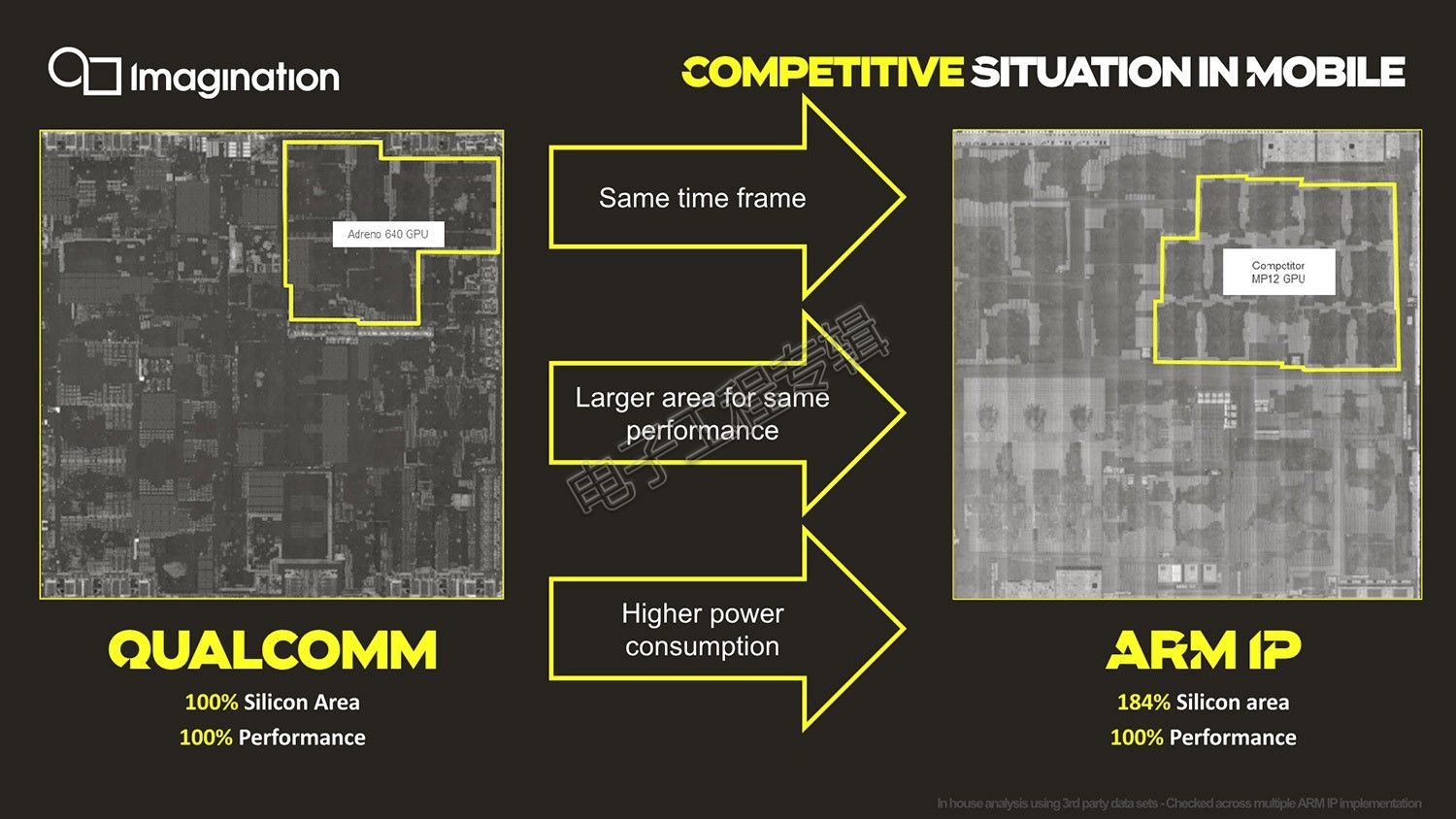

同代比较知名的竞品就属骁龙855的Adreno 640了,另外Evans并没有具体说对比的Arm Mali竞品是哪个型号,die shot也看不出来。不过PPT上标注了MP12,亦即这是个12核GPU,市面上比较新、而且符合该特征的产品就是Exynos 9820了,其GPU为Mali G76MP12,所以猜测Evans对比的这款GPU正是Arm Mali G76。如果将Adreno 640的性能、占地面积视作100%,则“Arm需要额外84%的占地面积,才能达到相同的性能水平,也就是说功耗必然也更高”,“而Imagination达到和高通相当的性能,在芯片面积和功耗方面都要小得多。”即便是达到175%的性能水平,占地面积和能耗依然更小。
这个数据当然是非常好看的,不过实际上这种对比可能并不公平,因为一方面Exynos 9820和骁龙855在制造工艺上就有差别,而且G76也并非Arm Mali最新的GPU IP。今年年中,。推测A-Series的实际GPU芯片产品至少也要2020年才能面市,所以A-Series首波真正要应战的应该是Arm Mali G77,以及高通刚刚发布的Adreno 650。
好在Mali G77在宣传中提到性能密度(performance density)相比G76也就提升为30%;而高通则宣称Adreno 650性能提升25%;就Imagination公布的数字来看,A-Series即便与这两者同场竞技也完全有充沛的余力一战,而且基本是无压力的状态,主体上还是要看Imagination令IP实体化的速度和表现。

Imagination PowerVR产品执行副总裁Steve Evans
为什么“性能暴涨”?
那么达成这种性能暴涨的原因是什么?Imagination PowerVR产品管理和技术营销高级总监Kristof Beets在接受我们采访时,首先提到的就是“完全重构的ALU(算术逻辑单元),我们对其进行了大量精简,现在其内部就是相当简单、干净的MAD管线(MAD是指乘法累加单元)”,执行单元从过去的2个MAD单元,变为现在的1个MAD(而且还抛弃了Furian架构中的MUL乘法单元),也就是说每个时钟周期单条管线的执行能力实际是下降的——这也是ALU拓宽的重要前提。
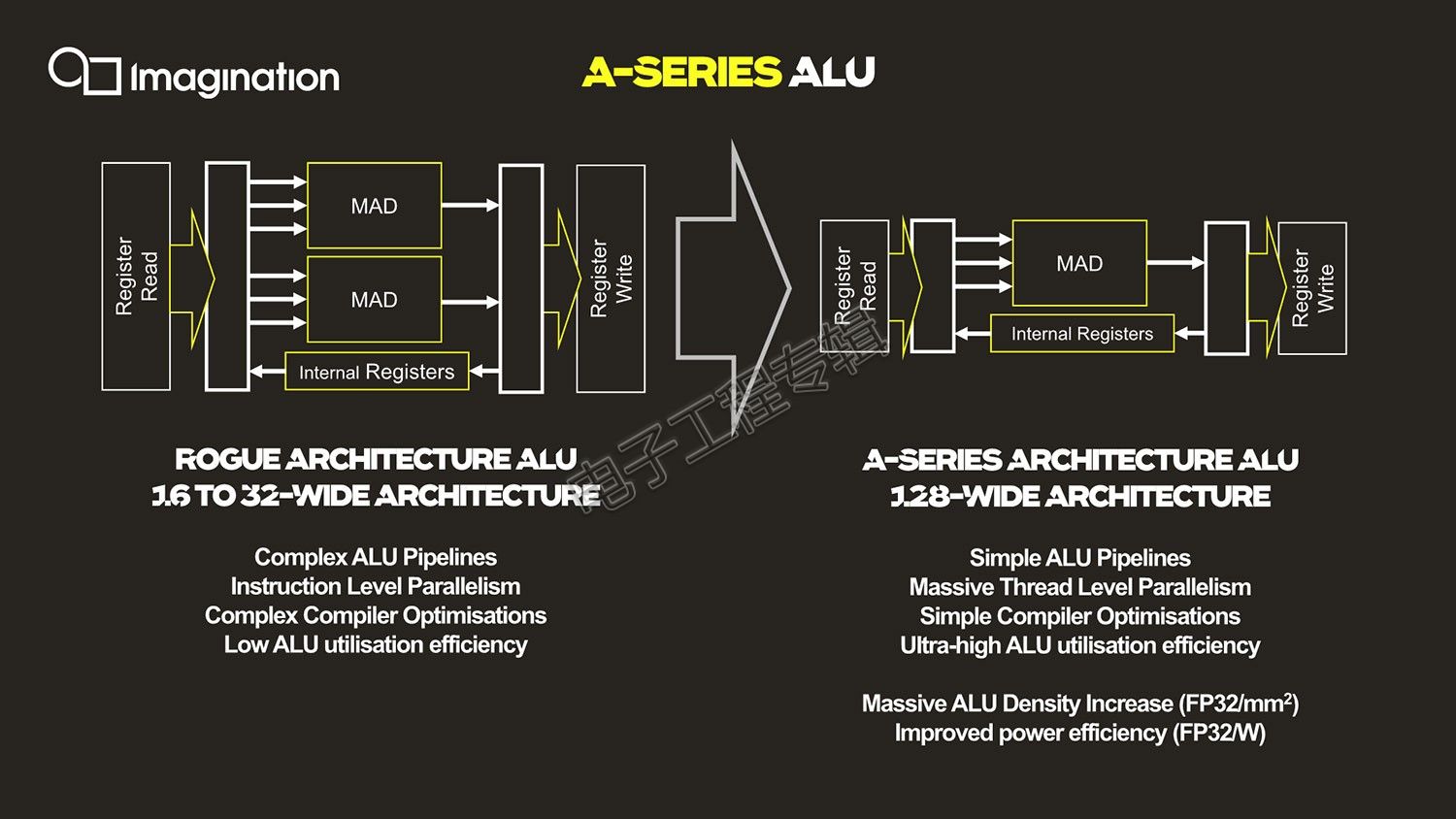
A-Series在架构上也因此有了“128条ALU管线同时并行”,也就是128-wide ALU。128线程宽度是什么概念呢?早前的Rogue架构采用的是32线程宽度wavefront(wavefront是GPU代码的最小可执行单元,SIMD过程中数据处理的最小单元,在所有线程中同时执行同一指令,Nvidia称其为warp),不过单个SIMD仅支持16-wide;Furian架构则真正加宽到了32-wide,即单个时钟周期执行32-wide wavefront。
作为对比,Arm Mali G77的SIMD宽度是16-wide,这还是相较G76的一倍拓宽。所以A-Series单就ALU结构来看,显然是独占鳌头的。这也表明Imagination真正开始从指令级并行彻底转往线程级并行(TLP),实现ALU的更高利用率。这么做理论上能够极大提升性能密度。Beets补充说由于管线精简,“compiler也大幅简化了,它只需要在管线中找乘法累加实现100%运算即可,架构中也更容易实现高利用率,是设计中实现性能密度和能效提升的重要组成部分。”
不过有这么宽的ALU,如何改进整个架构的前端,去喂饱这么宽的执行单元就成为一个问题了。前端调度效率低的话,这么宽的ALU管线只会出现大量闲置,以及效率的下降。
针对这部分,Beets在演讲着重介绍了data master(数据管理)——各种不同的data master将工作负载分配到GPU中去,比如有Geometry Data Master负责几何数据管理;还有2D Data Master、3D Data Master,以及Compute Data Master(负责通用型计算数据管理)。这些不同的data master基于内存的命令队列中读取数据,驱动任务负载进入GPU。[!--empirenews.page--]
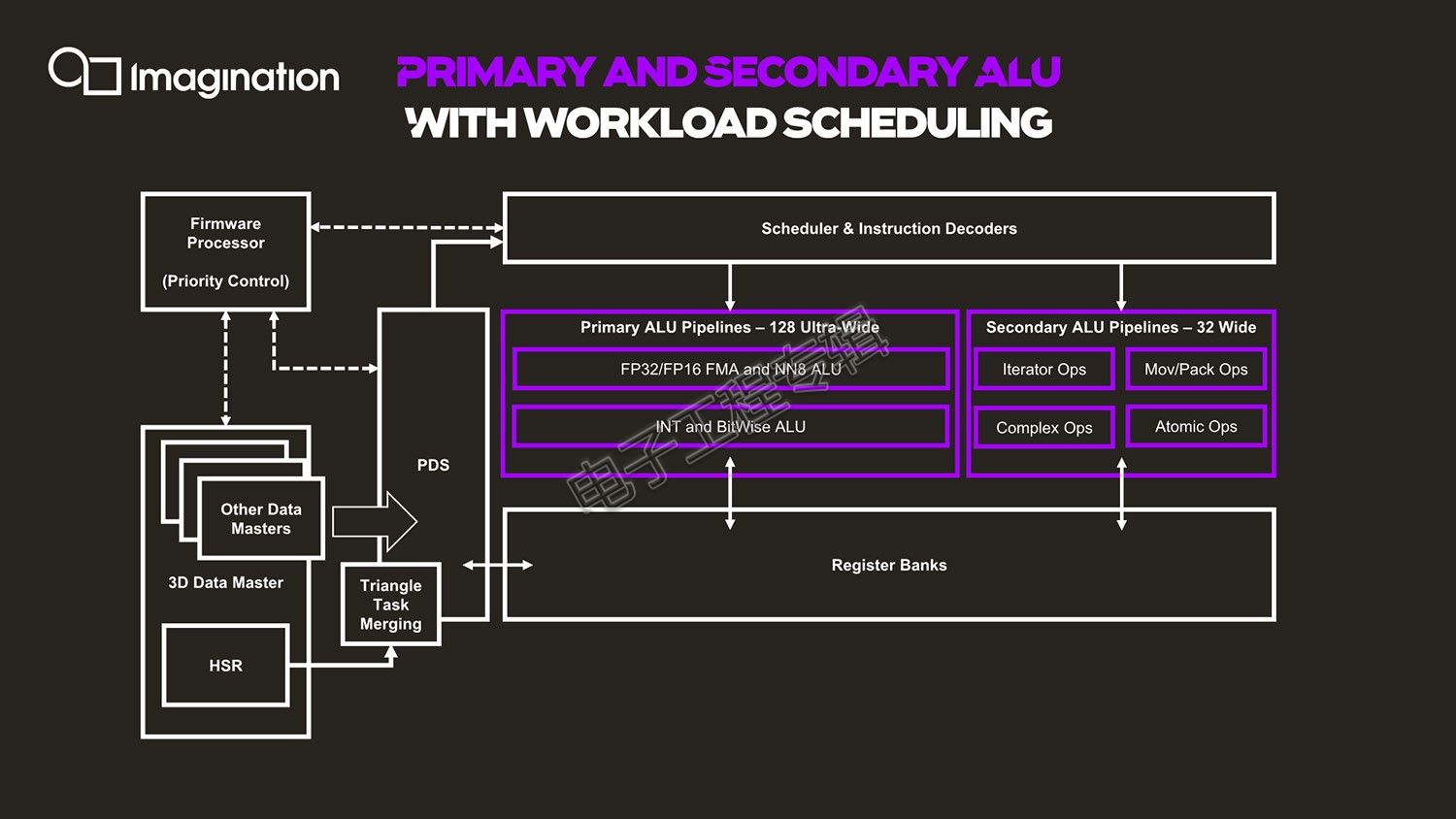
比如3D Data Master,还执行一些其他的固定功能预处理,包括HSR(隐面消除,是GPU的核心技术之一)、针对shader的工作负载生成。随后进入到“Triangle Task Merging”(三角形合并)——Beets表示这是一个关键模块;PDS(Programmable Data Sequencer,可编程数据定序器)再对资源进行分配管理,为工作负载和管理任务预留寄存器空间——这个组件能够针对未来的线程从cache中预取数据。
接下来是指令scheduler(调度器)和decoder(解码器),分发解码后才正式进入到执行单元。然后就是128-wide的ALU了,这里值得一提的是,在主ALU管线之外还有一个副ALU线路方案(Secondary ALU),如上图所示。这部分管线仅有主ALU管线1/4的宽度,每周期并行执行32个线程,不过有一些更为复杂的指令,执行任务包括各种操作与迭代、数据转换、超越指令等。Beets表示,在更低的速率上工作,是基于对真实应用场景各种工作负载所做的权衡。“针对ALU结构,我们分析了大量应用,去理解其中的平衡点,实现最高的效率。”
弹性化扩展
以上是对单个ALU簇的大致理解,也是A-Series获得性能暴涨的主要原因。我们往更高层级看一看其架构变化。在多年前的Rogue架构分享中,Imagination曾有一度将每个USC(Unified Shading Cluster)算作一个核心。到A-Series看来,大概已经不能这么算了,因为其性能扩展方式比较“模块化”。
前文谈到的这样一个主体128-wide ALU管线实际就是一个USC。这样一个USC,加上周边的固定功能单元,比如TPU(纹理处理单元)、HSR(隐面消除)、各种针对不同数据的管线(如针对几何数据处理、光栅处理、混合处理等),以及可实现更高层级共享的cache,也就共同组成了一个真正意义上的“核心”,只不过这个核心比较大型。下面这张图就是一个完整的核心,在A-Series的弹性架构中构成真正的、完整的一个IP方案。
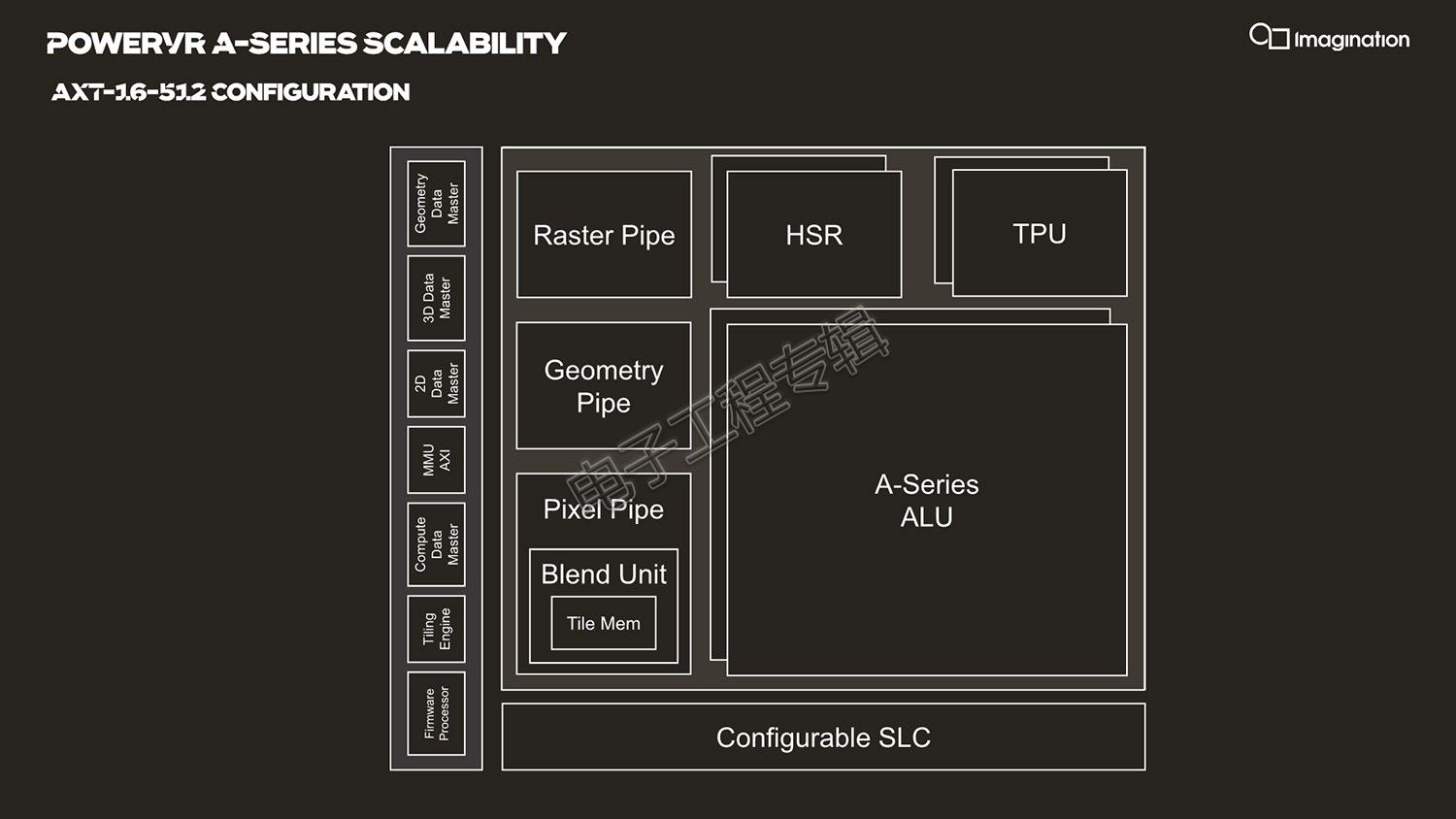
在AXM 8-256方案中,这样的一个GPU“核心”内部有一个ALU簇(即一个USC),一个TPU纹理处理单元,以及其他专用单元。而在更高配置的AXT 16-512产品中,一个“核心”则包含了两个128-wide的ALU簇(达成每个时钟周期512次浮点运算),两个TPU(达成每个时钟周期采样16个双线性过滤texel)。
作为对比,Mali G77标称每个时钟周期 64 FLOPs、2 texels,也就是说一个AXM 8-256核心就相当于8个Mali G77核心的性能水平。这其实也表明了Mali仍在走GPU的小核心、多核心路线,而Imagination在走宽核心路线。
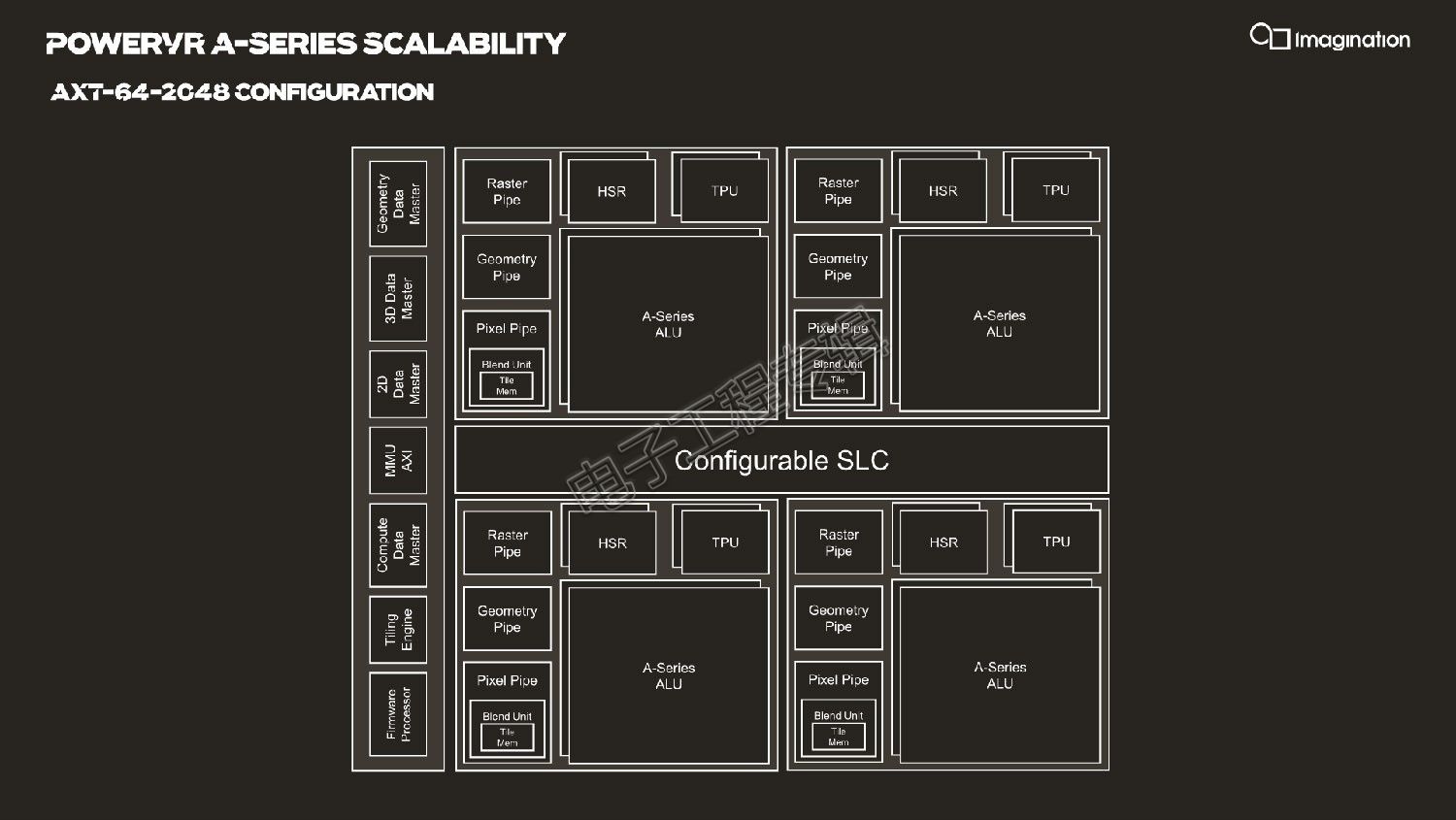
而如果是性能更高的AXT 32-1024,就是将这样一个GPU核心“复制”一份,实现性能翻番;那么达到最高配的AXT 64-2048实际上就是四个这样的核心。与此同时,针对各种单元的调度和监控,有一个小型的固件处理器(firmware processor),这一点将在后文中进一步提及。
Beets说这样的弹性架构,可以方便地选择性能提升,或者通过减少并行管线、纹理单元的方式,实现符合自身应用所需的配置。
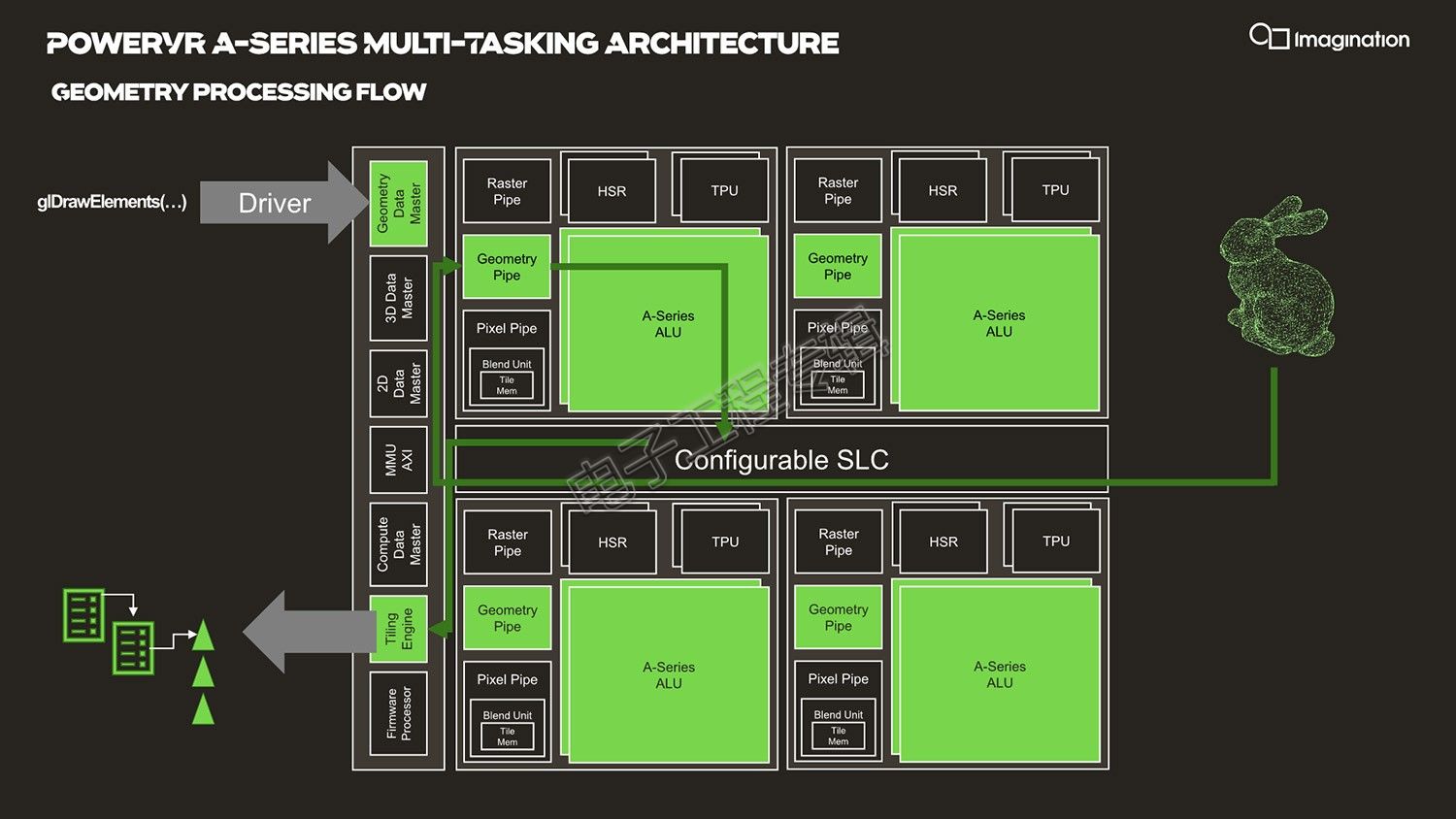
尤为值得一提的是,他特别列举了各种操作类型在流经GPU时的全套逻辑。比如上面这张图就是几何图形处理过程(geometry processing flow)的例子,绿色模块表示的是需要处理这些数据和操作所涉及的模块,箭头则表示整个流程方向:GPU获取到内存中的命令结构,Geometry Data Master首先检查内存中的命令队列,获取命令并将工作负载推到GPU内部;随后读取几何图形,各种各样的三角形就会填充到cache中,再进入几何图形管线(geometry pipeline),之后流经ALU,返回的结果还需要进入到Tiling Engine(因为Imagination的GPU IP是典型的Tile-based Rendering基于块渲染的架构),将这些三角形转换至应用于屏幕不同的tile区域,最终输出到内存。[!--empirenews.page--]
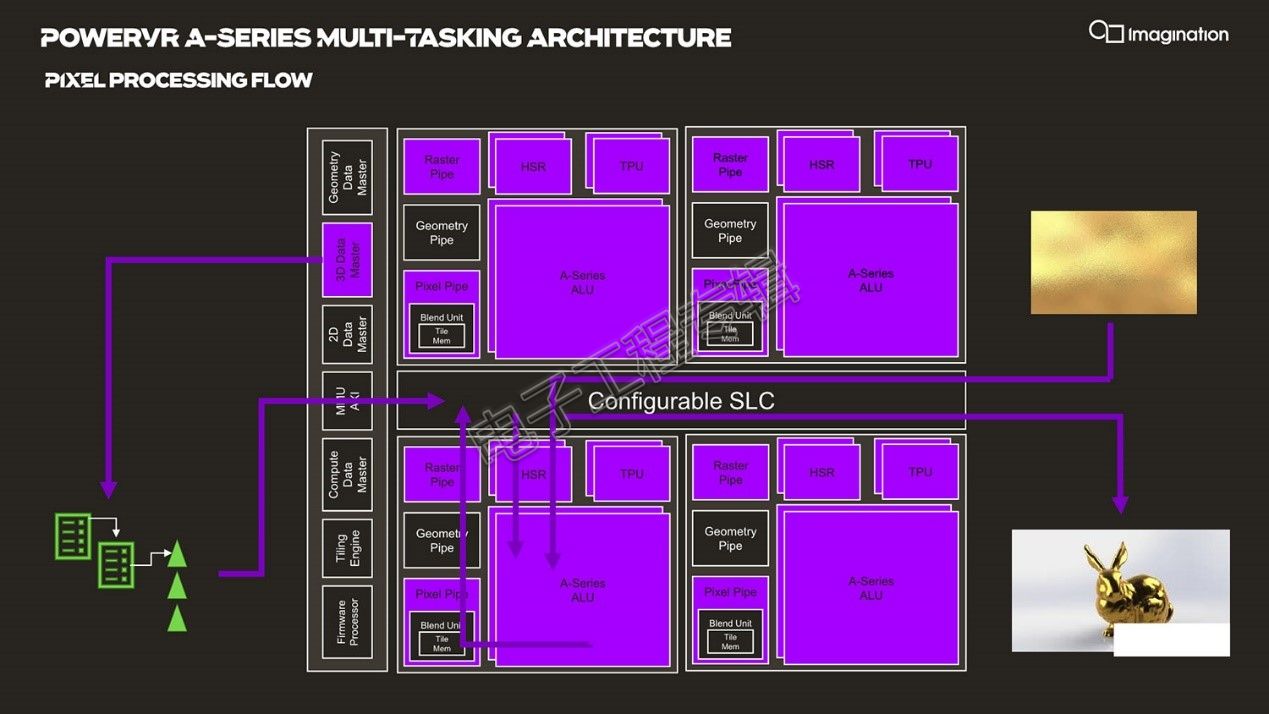
不同类型的操作,整个流程及涉及的模块会有差别,比如像素处理对应3D Data Master,后续要做隐面消除、计算像素渲染等;还有比如一些内部操作(housekeeping operations)、2D操作等等。上图是像素处理流程(Pixel Processing Flow),以紫色示意。
全栈并发的HyperLane技术
以上提到的这些各类别操作,可以通过一种名为“HyperLane”的技术做硬件级并行,这也是Imagination这次随同A-Series GPU IP发布的一种技术。这种技术对内存做完全隔离,多任务同时提交给GPU,实现GPU的多任务执行,或者说GPU硬件的“全栈并发”。典型的比如说图形计算和AI计算同时进行。

实际针对前文提到的各种不同类型的操作,HyperLane可将GPU的所有任务负载切分成(subdivide)几份,这其中不仅包括了物理层面的隔离切分(模块层面的并发),还包括按照时间切分做负载资源切换。不同的Data Master可以同时保持活跃状态,在整个GPU硬件资源之间进行动态的工作执行,每个时钟周期不同的模块可以执行不同的任务,ALU可以做Compute操作、像素操作、几何图形操作、2D操作等。
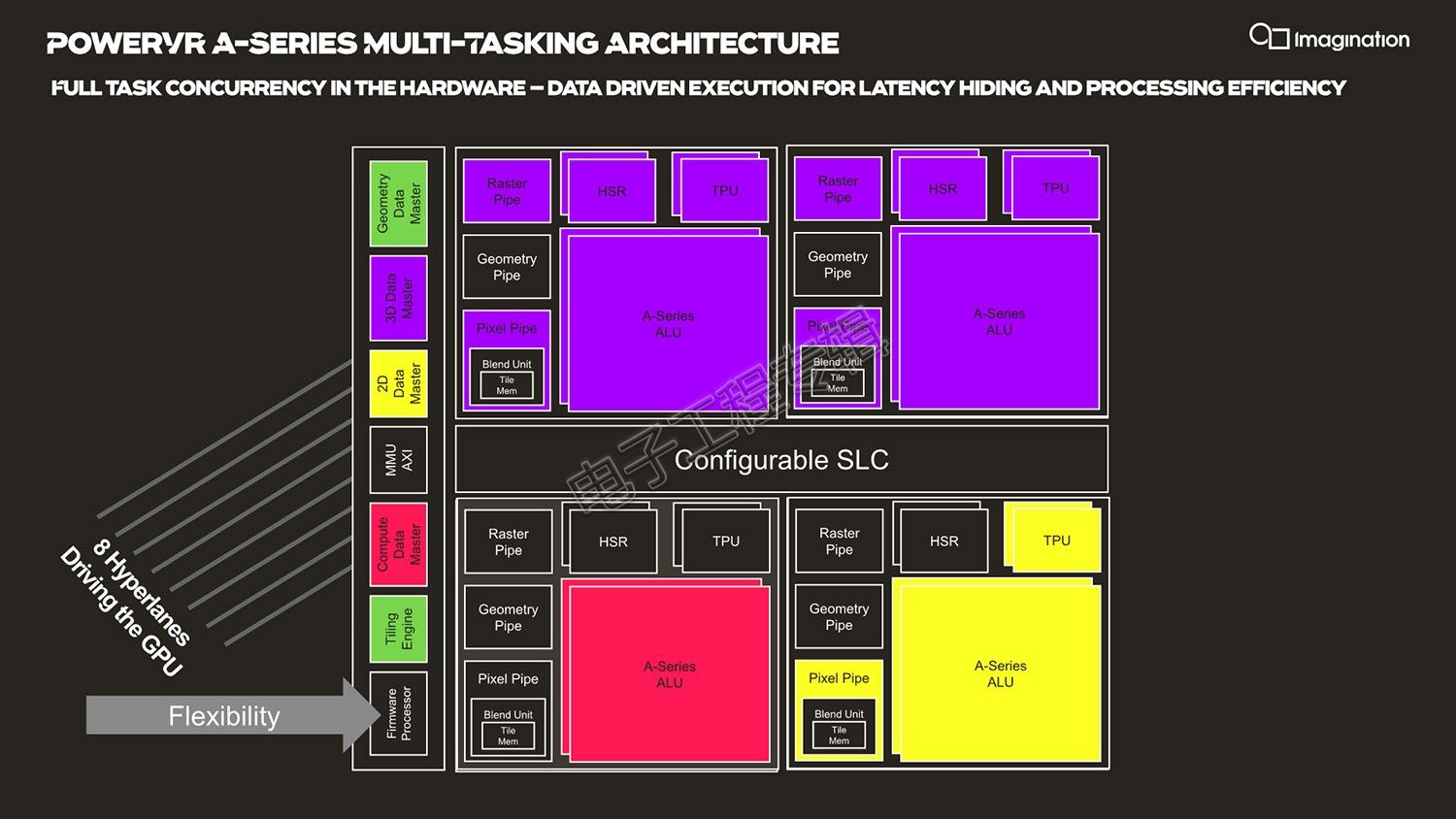
多种颜色表示HyperLane激活的多种操作正在同时进行
另外,HyperLane还有优先级机制,Evans说:“比如有客户希望,在同时执行任务的时候,确保图形计算性能不会受到AI工作负载的影响,那么就可以调高图形计算优先级,即便芯片正在处理复杂的AI任务,图形性能也能被保护起来。”这部分操作需要借用到这次IP架构中的固件处理器(即前文提到的firmware processor)。
HyperLane技术包含了动态的8路切分(eight way split/multi-tasking),也就是至多8条hyperlane。“所有工作同时进行,在硬件层面完整隔离和实现虚拟化,硬件级别的高级调度机制实现灵活性。”
HyperLane的一个副产品是内容保护,每条hyperlane都是隔离的,彼此之间的内容就能实现隔离。Evans说:“比如有个流视频应用,带DRM,那么内容在整个GPU中都是完全隔离起来的,在多任务环境中受到保护。”这也算是种安全防护方案了。

Imagination PowerVR产品管理和技术营销高级总监Kristof Beets
更多架构变化
我们认为,这次GPU IP改进中的一个亮点应该就是前文多次提到的固件处理器(firmware processor)了(似乎还是RISC-V架构)。即GPU内部有个小型的微控制器,它位于全局最高层级,完全可编程,以实现GPU整体任务执行的灵活性。“相关数据流、执行、优先级等各种GPU内部的活动,任何事件、任何决策,都通过固件处理器来控制和决定。这样一来就大大减轻了CPU的工作,而且还更有弹性。”
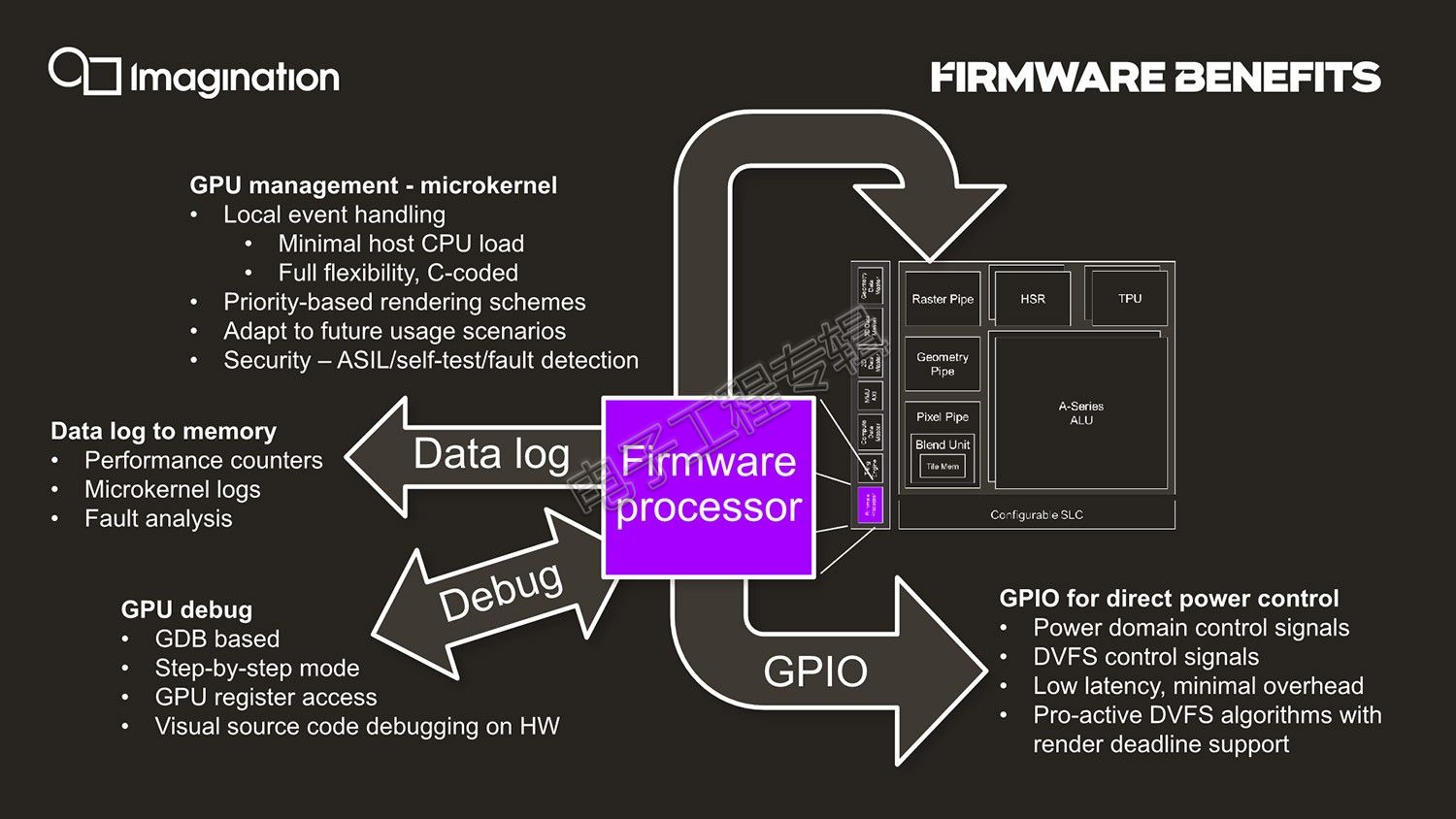
一般来说,GPU的这部分工作是由CPU驱动执行的,而Imagination则把这个活儿揽到了自己手里。这项改进似乎在Imagination的宣传中成效还挺大。典型的就是它能够应用于GPU更好的DVFS调节(动态电压平率调整)——这项工作原本是由内核GPU驱动负责的(所以以后驱动更新都是写入到这枚处理器固件中?)。Beets提到:“固件处理器能够全面感知GPU核心中发生的一切,这对于调度机制很有帮助,它甚至可以用来帮助开发者理解,如何获得GPU的更多性能。”
“如果我们能够了解GPU的工作调度、优先级,查看所有的参数,那么就能够知道何时需要更高的频率,或者可以在某个时间点降低频率。为此,我们的固件中有大量直接的GPIO信号回写,针对功耗控制做同步。GPU直接写回给系统到底发生了什么,这比CPU快多了。这样一来就能实现更出色的DVFS算法,可了解工作负载甚至预测所需的频率。”[!--empirenews.page--]
这枚小型处理器,还有一些特别的工作场景,比如说“如果GPU执行出现问题,我们可以通过固件记录有关GPU的信息,快速发现问题在哪里。控制获取信息,写回到内存,给予我们在GPU真实应用中debug的能力,而不是通过仿真去进行。这是分析问题非常出色的工具,如果应用在汽车系统中,还能进行错误分析。”
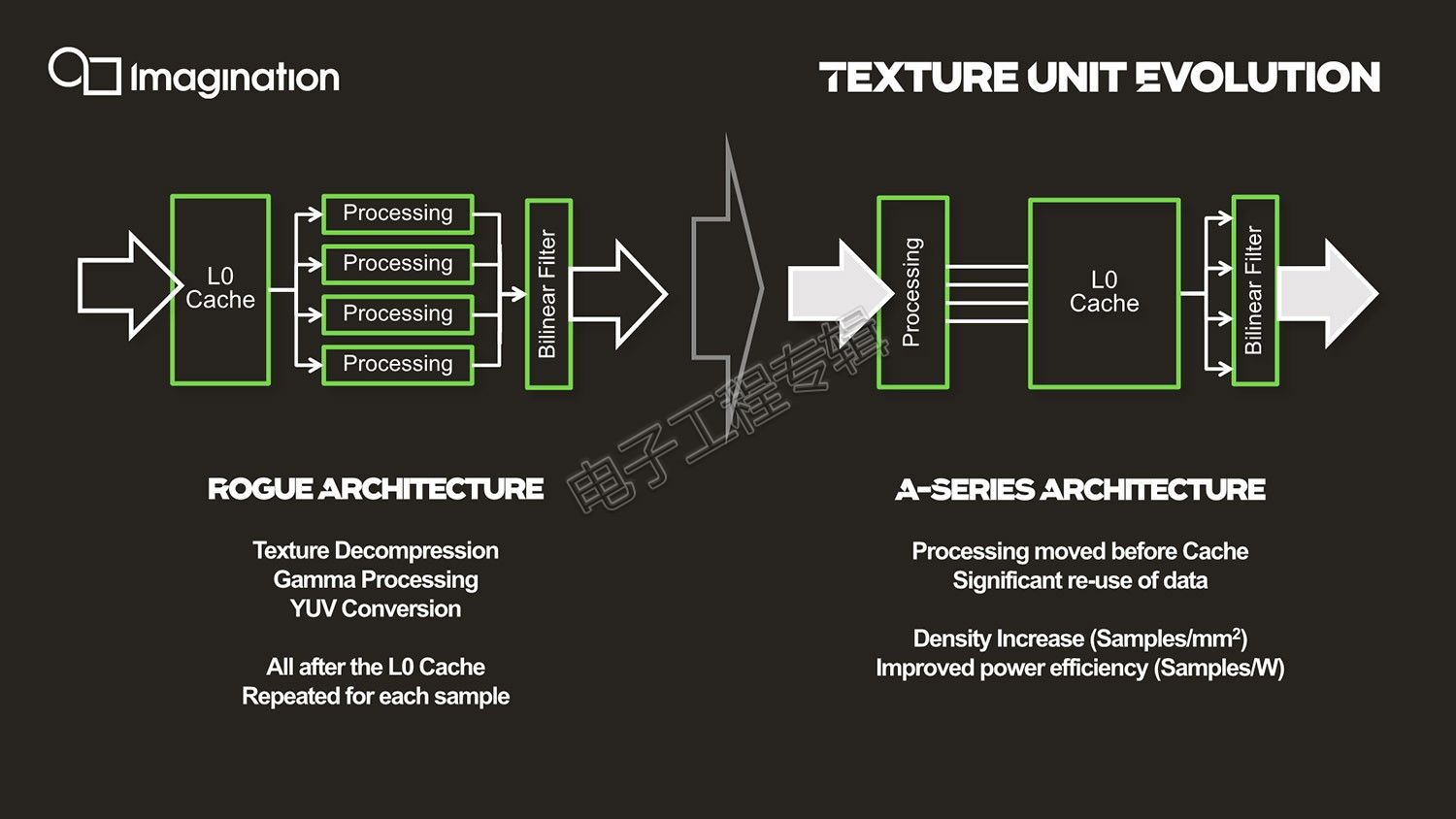
除此之外,A-Series在架构层面还有一些比较重要的变化,体现在纹理单元上(Texturing Unit),相关于将图像放到屏幕上的。比如说L0 cache的位置发生了变化,新架构的位置是在处理与线性过滤阶段之间。原本Rogue架构中,包括纹理解压(texture decompression)、gamma、YUV转换等操作都是在L0 cache之后进行的,这样一来某些相同的任务会被多次重复执行处理。而L0 cache位置调整后,可储存处理阶段时候的输出,数据可复用——多项异性过滤的时候,texel不需要再重复采样。
还有针对一些陈年旧算法的改进,比如说各项异性过滤(anisotropic filtering)以前一直是基于DirectX的——早年Imagination有参与过桌面GPU市场混战,当时这项特性自然是紧跟微软的参考算法的。所以这次“我们彻底重构了纹理采样方式”,“现在更加不依赖于角度(more angel-independent),采样更少但实际(各项异性过滤)质量更高。”这种算法的提升,实质也是减少带宽、增加能效的重要方案。”
此外,Rogue架构在合并(blending)操作上用的是shader。更早之前这种操作会有个专用单元去执行,Beets说Rogue采用软件的方式来执行合并操作虽然具备了很大弹性,而且节省空间,但这样一来系统会复杂化。“由于合并操作(shading a blending)越来越复杂,我们还是需要额外的指令来更高效地执行合并操作,所以A-Series又回归了专用合并单元。这样可以释放shader周期,减少数据搬运量。”

最后值得一提的是AI Synergy,实际也是本次Imagination技术发布的重点,不过它的实质是让A-Series GPU与Imagination的神经网络专核NX NNA产品做协同的,在GPU和AI专核之间实现AI负载的共享——GPU可以负责模型更多可编程层面的工作,NNA则针对全连接层处理的固定单元做任务处理。这部分不是我们针对图形计算要探讨的重点。
搭建生态是当务之急
实际上,还有一些特性是Imagination并没有着墨于A-Series的,比如当代GPU比较常见提升带宽效率的framebuffer图像压缩技术。Imagination的压缩方案名为PVRICv4,不过这套方案的最新版本实际已经在Series 9产品中得以应用。针对有损与无损压缩有单独的管线。Beets这次说Imagination持续加强了其HDR压缩率。
就这些技术来看,的确可以认为是Imagination近15年来“最重要的发布”,它已经充分凸显了Imagination做策略转变的决心,而且至少就Imagination自己的纸面数据来看,在能力上是优于竞争对手的。不过这并不能表明Imagination未来就可以在GPU市场上轻易获胜。
开发者生态此时变得极其重要,究竟有多少客户会采用A-Series GPU IP?这和生态的成熟度、市场价值有很大关联。
针对开发者软件部分,Imagination也下了一番功夫,包括跨操作系统,对各种行业标准API的支持,对各种游戏引擎的完整支持。

面向开发者的有一项特性值得一提,即如上图所示,Imagination为开发者构建了“heatmap”:“很多开发者都在苦苦进行性能优化,尤其是图形计算方面。或许性能计数器(performance counter)会告诉你ALU限制、纹理限制,但对你的帮助其实真的不大,所以我们增加了一个新特性,生成图形计算画面的热图(heatmap),它会告诉你GPU在屏幕上的某个tile上面花了多长时间做渲染。我们的工具要做到这一点很容易。开发者能够很方便地搞清楚某些tile的渲染开销很大,花了最多的shader周期、最多的带宽等等,这样一来就能真正帮助开发者获得性能上的优化。”这其中的实现似乎与硬件上的固件处理器也有关系。[!--empirenews.page--]
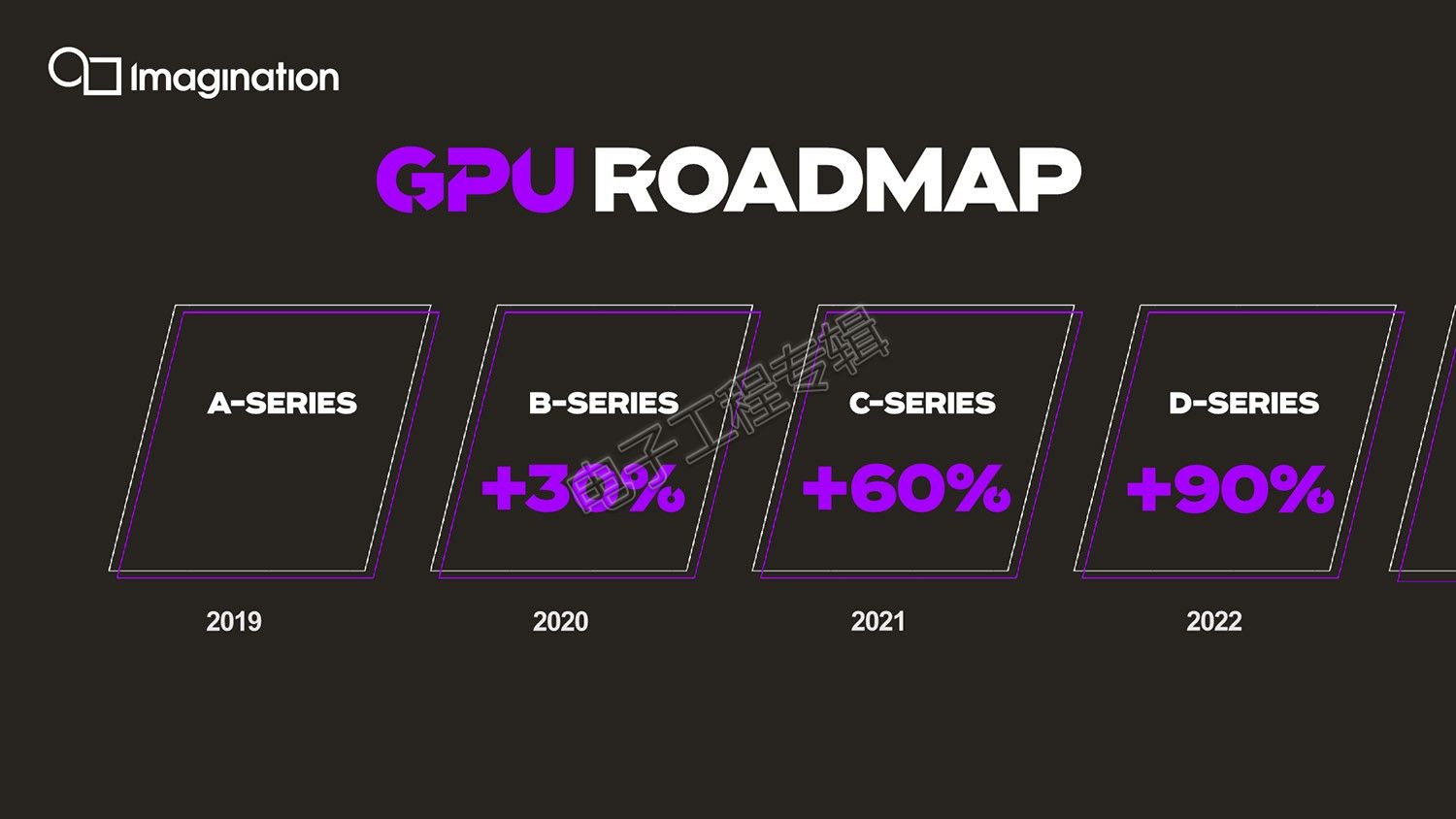
Evans勾勒了来年的产品路线图,2020年是B-Series,2021年C-Series,包括2022年的D-Series,要比今年的A-Series性能提升90%。光线追踪架构也即将到来,“我们也在开发新领域的图形计算方案,围绕光线追踪(ray tracing),移动领域的光线追踪架构,作为技术做授权方案,未来我们很快在GPU中引入光线追踪。”
Imagination当前面临的局势并不算很好,尤其是在主流手机SoC制造商普遍倾向于采用自研GPU IP的情况下。Furian架构在推出后就没有在市场上激起火花,这可能是A-Series在较快的时间内出现的原因。至少A-Series的确比过去更理想,也是Imagination很重要的转型之作。
我们在活动现场看到了Imagination的一些合作伙伴前来站台,包括全志科技、睿悦信息、紫光展锐等,看起来Imagination现如今的重要市场已经放到了中国。尤其在获得中资背景以后,其中的合作自然水到渠成,也是在当前国际环境下一个双赢的局面。即便如今的手机市场已经不是当年Imagination叱咤风云的时代了,行业如今的发展重心本来就在偏移,面向更多应用领域的GPU、AI产品却也充满机遇。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。