那个爱穿皮衣的男人带着英伟达的最新超级芯片GH200 Grace Hopper又来了。在计算机图形和交互技术会议SIGGRAPH上,英伟达CEO黄仁勋一袭黑皮衣,对台下数千名观众表示,“生成式人工智能时代即将到来,如果你相信的话,那就是人工智能的iPhone时代。”
这是继NVIDIA GH200爆火后,英伟达今年的二度炫技。颇有“产能供应不上,就在性能卷死大家”的意思。除了英伟达外,AMD、英特尔等国内外各大厂也在疯狂赶追这波AI热潮。
卷产能,卷性能
业界消息显示,全球多数大模型都在使用英伟达的GPU芯片,据TrendForce集邦咨询研报,预计AI芯片2023年出货量将增长46%。英伟达GPU是AI服务器市场搭载主流,市占率约60%到70%。
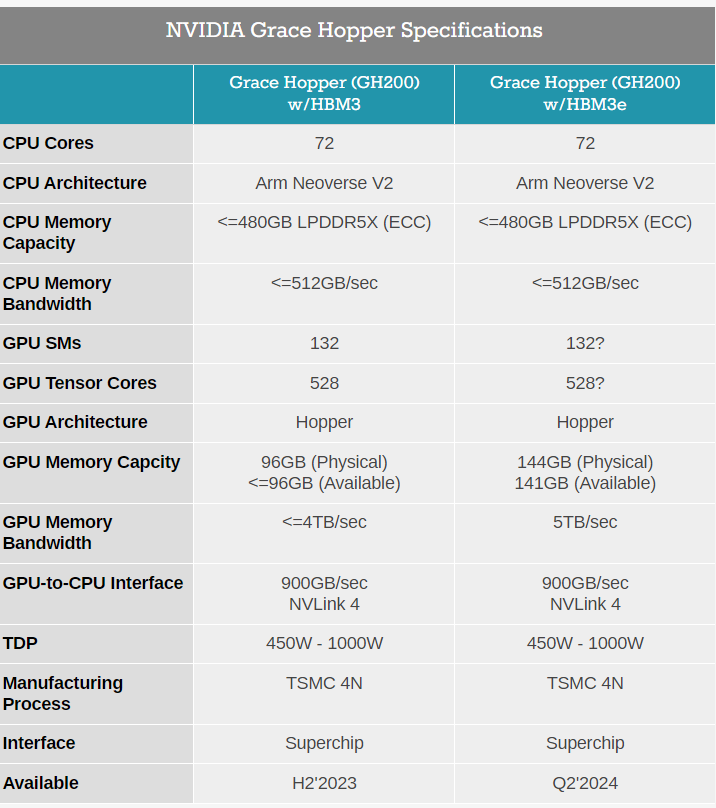
与当前一代产品相比,英伟达新一代GH200拥有基本相同的“基因”:其 72 核 Arm Neoverse V2 Grace CPU、Hopper GPU 及其 900GB/秒 NVLink-C2C 互连均保持不变。核心区别是它搭载了全球第一款HBM3e内存,将不再配备今年春季型号的 96GB HBM3 vRAM 和 480GB LPDDR5x DRAM,而是搭载500GB的LPDDR5X以及141GB的HBM3e存储器,实现了5TB/秒的数据吞吐量。
简单而言,这是世界上第一款配备HBM3e内存的芯片,能够将其本地GPU内存增加50%。这也是专门对人工智能市场做的“特定升级”,因为顶级生成式AI往往尺寸巨大却内存容量有限。
HBM3 VS HBM3e(图片来源:英伟达)
英伟达表示,HBM3e内存技术带来了50%的速度提升,总共提供了10TB/秒的组合带宽。能够运行比先前版本大3.5倍的模型,并以3倍的内存带宽提高性能。
根据TrendForce集邦咨询最新报告指出,以HBM不同世代需求比重而言,TrendForce集邦咨询表示,2023年主流需求自HBM2e转往HBM3,需求比重分别预估约是50%及39%。随着使用HBM3的加速芯片陆续放量,2024年市场需求将大幅转往HBM3,而2024年将直接超越HBM2e,比重预估达60%,且受惠于其更高的平均销售单价(ASP),将带动明年HBM营收显著成长。

以竞争格局来看,目前SK海力士(SK hynix)HBM3产品领先其他原厂,是NVIDIA Server GPU的主要供应商;三星(Samsung)则着重满足其他云端服务业者的订单,在客户加单下,今年与SK海力士的市占率差距会大幅缩小,2023~2024年两家业者HBM市占率预估相当,合计拥HBM市场约95%的市占率,不过因客户组成略有不同,在不同季度的位元出货表现上恐或有先后。美光(Micron)今年专注开发HBM3e产品,相较两家韩厂大幅扩产的规划,预期今明两年美光的市占率会受排挤效应而略为下滑。

结合业界消息,三星电子计划于今年底开始HBM3生产,并计划投资数千亿韩元,将忠南天安工厂的HBM产能提高一倍。从第四季度开始,三星的HBM3也将供应英伟达,当前英伟达高端GPU HBM芯片由SK海力士独家供应。
据英伟达官方消息,其最新的GH200产品需要到明年二季度才投产,其售价暂未透露。这其中一个重要原因是HBM3e将在明年才会供货,市场消息显示,三星和SK海力士预计将于明年第一季度发布HBM3E样品,并于2024年下半年开始量产。美光方面,则选择跳过HBM3,直接开发HBM3e。届时,依靠新款英伟达芯片,AI大模型有望迎来新一轮的爆发。
据TrendForce集邦咨询观察HBM供需变化,2022年供给无虞,2023年受到AI需求突爆式增长导致客户的预先加单,即便原厂扩大产能但仍无法完全满足客户需求。展望2024年,TrendForce集邦咨询认为,基于各原厂积极扩产的策略,HBM供需比(Sufficiency Ratio)有望获改善,预估将从2023年的-2.4%,转为0.6%。
英伟达的竞争对手们
AI这个巨大的千亿市场,不只是英伟达一家的游戏,AMD和英特尔也在加速追赶,希望分得一杯羹。
英特尔在2019年以约20亿美元价格收购了人工智能芯片制造商HABANA实验室,进军AI芯片市场。今年8月,在英特尔最近的财报电话会议上,英特尔首席执行官Pat Gelsinger表示,英特尔正在研发下一代Falcon Shores AI超算芯片,暂定名为Falcon Shores 2,该芯片预计将于2026年发布。
除了Falcon Shores 2之外,英特尔还推出AI芯片Gaudi2,已经开始销售,而Gaudi3则正在开发中。业界认为,目前Gaudi2芯片的热度不及预期,这主要在于Gaudi2性能难以对英伟达H100和A100形成有效竞争。
英特尔研究院副总裁、英特尔中国研究院院长宋继强近日表示:“在这一波大模型浪潮当中,什么样的硬件更好并没有定论。”他认为,GPU并非大模型唯一的硬件选择,半导体厂商更重要的战场在软件生态上。芯片可能花两三年时间就做出来了,但是要打造芯片生态需要花两倍甚至三倍的时间。英特尔的开源生态oneAPI比闭源的英伟达CUDA发展可能更快。
AMD也在加速追赶。今年6月,AMD举行了新品发布会,发布了面向下一代数据中心的APU加速卡产品Instinct MI300,直接对标H100。这颗芯片将CPU、GPU和内存全部封装为一体,从而大幅缩短了DDR内存行程和CPU-GPU PCIe行程,从而大幅提高了其性能和效率。
Instinct MI300将于2023年下半年上市。AMD称Instinct MI300可带来MI250加速卡8倍的AI性能和5倍的每瓦性能提升(基于稀疏性FP8基准测试),可以将ChatGPT和DALL-E等超大型AI模型的训练时间从几个月减少到几周,从而节省数百万美元的电费。
此外,谷歌、亚马逊、特斯拉等也都在设计自己的定制人工智能推理芯片。除了国外大厂,国内的芯片企业也迅速入局,其中,昆仑芯AI加速卡RG800、天数智芯的天垓100加速卡、燧原科技第二代训练产品云燧T20/T21均表示能够具有支持大模型训练的能力。
封面图片来源:拍信网