英特尔“至强”叫阵“米兰”,Arm阵营笑而不语
3月15日,AMD公司发布了采用台积电7nm工艺制造的全新EPYC 7003系列处理器(代号“米兰”),其中包括了代表着服务器CPU性能新高的AMD EPYC 7763处理器。在最多可达64颗的“Zen 3”核心、全新级别的每核心高速缓存、PCIe 4连接、更多I/O和内存吞吐量等先进科技的加持下,EPYC 7003系列处理器每时钟指令集(IPC)性能提升高达19%。
AMD方面表示,EPYC 7003系列是目前全球最好的数据中心芯片,超越了竞争对手英特尔。预计到2021年底,EPYC处理器将会与包括AWS、思科、戴尔科技、谷歌云、HPE、联想、微软Azure、甲骨文云基础架构、Supermicro和腾讯云等在内的众多合作伙伴携手合作,为其生态系统带来超过400个云实例以及超过100个新OEM平台。

AMD围绕EPYC处理器构建的生态系统
被AMD抢了风头的英特尔自然不甘落于人后。
4月7日,英特尔宣布推出第三代至强(Xeon)可扩展处理器(代号Ice Lake),其主要亮点包括:采用Intel最新的10nm工艺,单个芯片最多包含40核。与上一代20核Cascade Lake相比,IPC性能提升20%;在主流数据中心工作负载上性能平均提升46%;74%的AI推理性能增加;与5年前的老系统相比,平均性能提升2.65倍。
值得一提的是,第三代至强可扩展处理器是Intel首个主流双插槽并启用SGX软件防护扩展技术的数据中心处理器,也是Intel唯一一个内置AI加速的数据中心处理器。此外,作为多代策略的延续,第三代至强内置有Intel密码操作硬件加速。

而为了应对数据中心AI负载任务的增长,第三代至强处理器通过代际硬件平台改进、软件优化,在机器学习用例中,比如XGBoost算法、Kmeans算法等方面,实现了1.3-1.6倍的性能提升;面向深度学习应用中常见的图像识别、图像分类、语言处理等,DL Boost指令实现了1.45-1.74倍的性能提升。
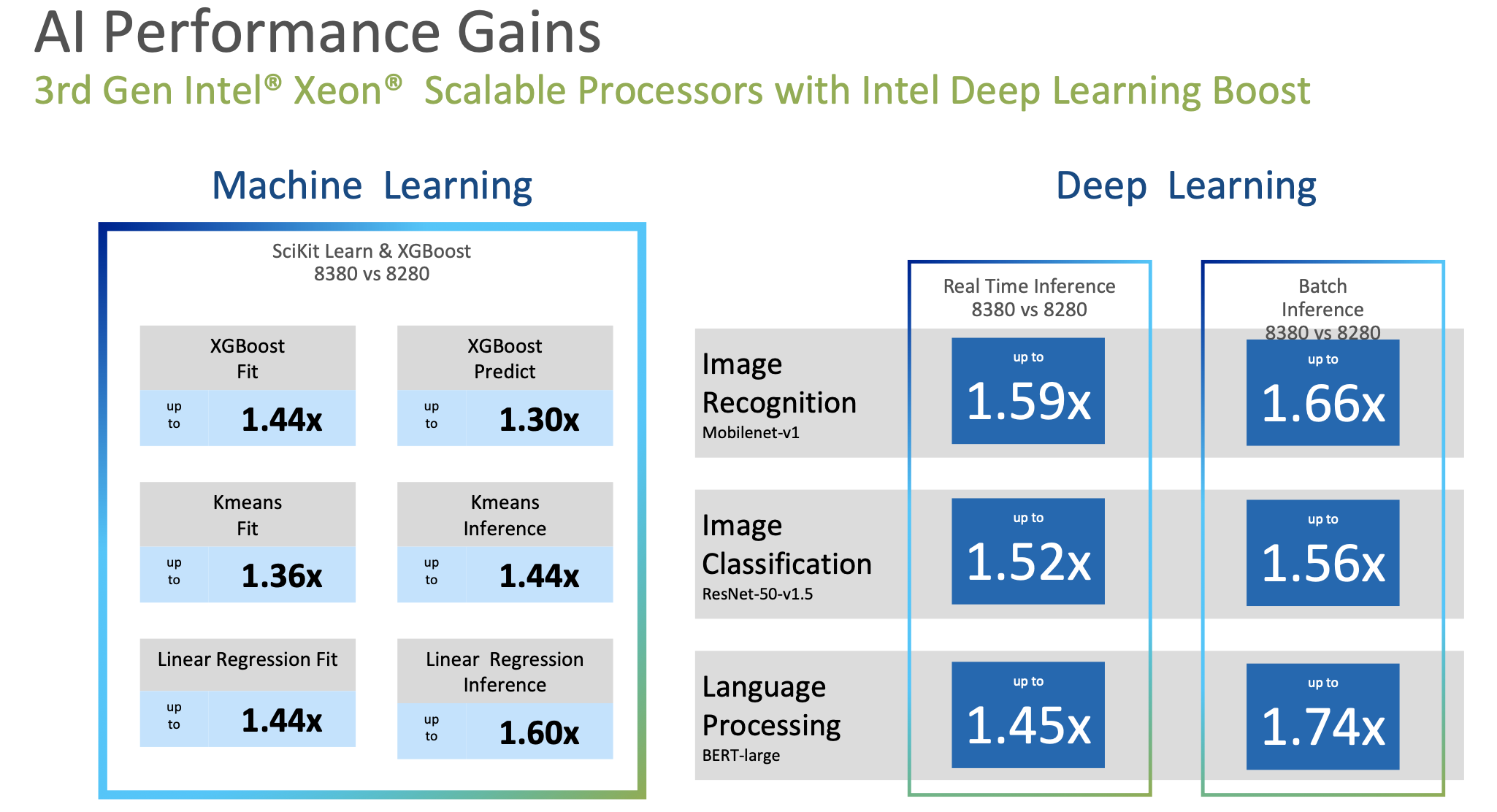
Intel官方提供的数据显示,自2017年推出第一款至强可扩展处理器以来,英特尔不但向全球客户交付了超过5000万颗至强处理器,部署了超过10亿颗至强核心,还成功的将用户每台虚拟机的基础设施成本降低了25%,且性能保持不变,并将超过80%的TOC转化为已有实际收益的部署。目前,超过800家云服务提供商部署了基于至强可扩展处理器的服务器,超过1000个客户进行了TOC认证。
不打“核”战
Intel方面认为,单纯比拼“核”数的做法既不可行,也不科学。因为虽然大多数行业标准的基准测试都是最大吞吐量,但是对于数据中心计算机架构来说,不仅需要提高吞吐量,同时也需要具备最佳的响应能力,这样才能更好地处理数据中心普遍的工作负载。为了实现这一点,处理器既需要应对传统的工作负载,也要能够应对新兴的数据工作负载,性能需要在处理器内部和外部进行良好拓展,无论是节点内部还是节点外部。
Intel官方给出了与AMD米兰在缓存时延、内存时延等方面的参数对比:
在包括L1、L2、L3层级的缓存时延方面,最关键的是L3层面的缓存时延。第三代至强可以直接访问这一层缓存,从而获得一致的响应时间。米兰包括8个不同的硅芯片进行计算,每个都有独立的缓存,当数据在本地缓存中,即核所在的位置旁边,响应时间会很短;但如果数据不在本地缓存,需要通过I/O请求,到另一个计算硅芯片来检索数据,再通过I/O回到发出申请的内核,因此本地缓存访问和远程访问之间响应的时间差别很大。

内存时延方面,Intel方面强调了最大的DIMM能力和速度能力。第三代至强有8个内存通道,可以在最高的内存频率下达到3200 DIMM性能,而米兰只有一个内存通道可以以最快的速度运行,到第二个DIMM时,速度下降会降低内存的吞吐量。
在DRAM时延方面,在本地插槽的情况下,从内存中获取数据最快需要多长时间?从第二个远程插槽中获取数据又需要多长时间?Intel方面强调了第三代至强组合产品的优势,硅芯片旁边就是直接内存控制器,因此本地插槽延时更短,远程插槽延时性能更优,最高可以快30%。
内存总能力上,Intel的持久内存可以实现每个插槽6TB内存,这一能力几乎可以让用户在尽可能靠近处理器的位置随时提取数据,做到快速访问。Intel技术专家表示,以上这些好处不一定在吞吐量上能显示出来,但实际响应时间在应用中非常关键。

在深度学习和推理性能方面,第三代至强比AMD米兰提高25倍。在20个最常见的机器学习、深度学习模型的训练和推理比较中,第三代至强性能是米兰的1.5倍,是英伟达A100 GPU的1.3倍。

面对数据中心应用将AI加速任务卸载到专用处理器上的趋势,Intel借第三代至强发布之际再次表明:第一,至强CPU是AI加速的绝佳选择,加速发生在CPU,可以将工作负载提升到新的水平;第二,数据中心基础架构的高利用率非常关键,决定了用户在不同类型工作负载中能够获得的容量弹性,因此在最佳TCO基础上的分布式服务最为重要,而不仅仅是在孤立的节点基准测试上做到最佳。
Intel市场营销集团副总裁、中国区数据中心销售总经理陈葆立表示,整个产品的迭代做好平衡非常重要,不管是核数、还是不同工作负载的加速指令和配套产品。目前采用PCIe 4.0 64个通道,已经可以显著提高带宽和性能。随着分布式计算、微服务在大规模数据中心的应用,I/O的时延和一致性对于大规模服务的实际交付非常关键。Intel通过对这些I/O流、在插槽中的处理情况,以及与CPU上其余服务交互方式的改进,从而保证能够提供最佳的规模系统性能,满足遍布大量节点和整个数据中心的需求。
Arm阵营“笑而不语”
对服务器领域的追逐从未停止的,不仅有X86架构,还有Arm阵营。
2018年10月,Arm首次宣布推出面向云到边缘基础设施产品Neoverse及其初步路线图,并承诺平台效能30%的年增长率指标将持续到2022年及以后。2020年9月,Neoverse再度进阶,新增两个全新的平台—Neoverse V1平台以及第二代的N系列平台Neoverse N2。
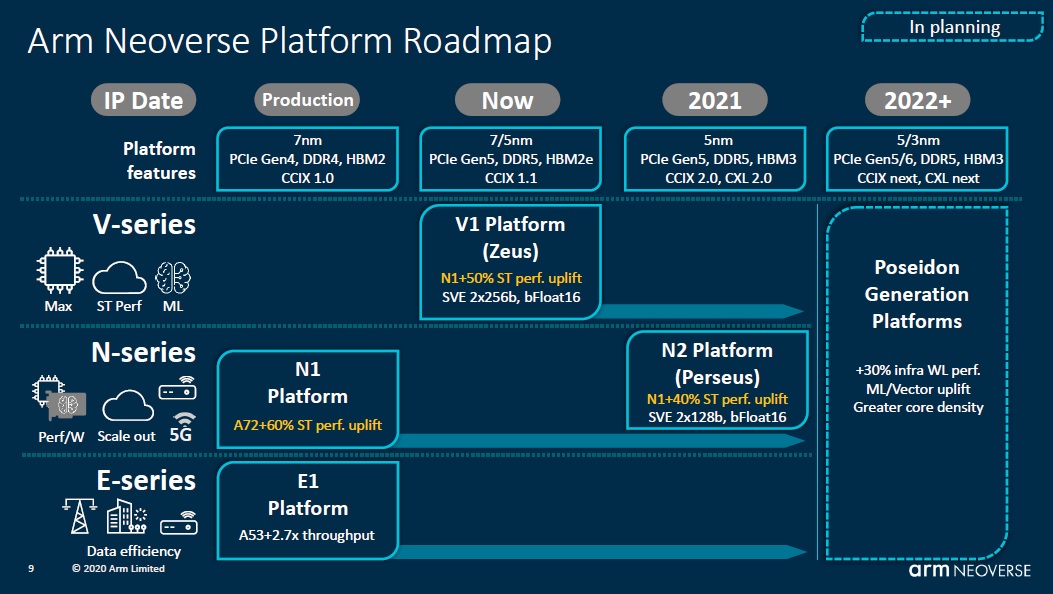
Arm Neoverse平台路线图
根据Neoverse平台PPA设计原则,N系列强调性能、功率、面积得到同等考量,擅长可扩展;E系列主要关注效率,对于网络流量和数据应用程序非常有效,在功耗和面积的缩减上进行优化;V系列旨在提供最佳性能,需要添加更大的缓存、窗口和队列,相对来说会消耗更多面积和功耗。
Arm方面认为,除了与工程团队的努力和投入密不可分外,Arm自身软件生态系统的逐渐成熟以及异构计算的推动同样功不可没。
再一起看看其它厂商的最新动态:
3月15日,隶属于Arm阵营的安晟培半导体(Ampere Computing)公布了云原生服务器处理器Ampere Altra Max样片的基准测试数据。Altra Max是Ampere继2020年3月发布的80核Altra处理器后即将推出的重磅新品,内核数量达到128核,专为云原生架构打造。在软件媒体编码测试中,Ampere Altra的编码性能已经领先于当前的x86处理器(如下图所示),而Ampere Altra Max则比Ampere Altra更强。

Ampere Altra媒体编码性能与x86处理器对比
3月17日,高通公司宣布以14亿美元的价格完成了对世界一流的CPU和技术设计公司NUVIA的收购。在被问及是否会继续投资NUVIA最初进入的服务器和企业市场时,高通方面回应称,这不是收购的主要目标或动机,但是高通公司未来会对此保持开放的态度,让NUVIA团队探索这些可能性。
3月29日,亚马逊云科技宣布,新一代内存优化实例Amazon Elastic Compute Cloud(Amazon EC2) X2gd实例已全面可用,它由亚马逊云科技自研的基于Arm构架的 Graviton2处理器提供支持。新的X2gd实例与当前基于x86的X1实例相比,性价比提升可高达55%;而与其它基于Graviton2的实例相比,每个vCPU配置的内存容量更大,使客户能够更高效地运行内存密集型工作负载,例如内存数据库、关系型数据库、电子设计自动化(EDA)工作负载、实时分析和实时缓存服务器等。
结语
尽管受到新冠病毒疫情的影响,但来自数据中心的需求仍然源源不断,同时,5G商用也促使全球消费者和企业数据访问出现了快速变化。Canalys的数据显示,2020年Q1全球云计算资本支出增长34%,达310亿美元,创历史新高。根据Omdia的数据,2020年Q1全球服务器出货量为330万台,同比增长超过30%,创下了有史以来第一季度的最高纪录,而2020全年出货量达1,290万台,比2019年增长8.3%。
很显然,一些过去需要2至4年时间才能形成的趋势,现在已经被缩短到了几个月。因此,越来越多的数据中心运营商不断加大对数据中心的投资,以应对经济领域数字化转型的快速推进。可以预见的是,在数据中心领域,打造强有力的批量生产与交付的生态系统和供应链,帮助用户加速面市时间,简化从边缘到云基础设施的部署,将成为芯片厂商未来竞争的焦点。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。