前几年,在赛灵思(Xilinx)没被收购、Altera没有独立那个年代,FPGA厂商的产品PPT中,绝对会有不会缺乏与GPU的对比。尤其在跑AI方面,无论是在性能上,还是功耗上,都比GPU强,同时还具备更强的灵活性。
反观最近一段时间,AI和大语言模型(LLM)的热潮不仅没有熄火,反而越来越热。最近一段时间,FPGA厂商也在“悄悄”发力,推出面向AI的新产品。
那么问题来了,相比GPU,FPGA性价比如何?在LLM领域,FPGA会有一席之地吗?
Achronix:跑LLM比GPU更便宜
早在2019年5月,Achronix就推出了“FPGA+”系列产品Speedster7t FPGA。之所以叫FPGA+,其实是因为这颗芯片属于eFPGA IP的领域,即嵌入在定制SoC或ASIC器件中的FPGA IP内核。
作为FPGA赛道的“小众”玩家,Achronix的定位一直很清楚,就是堆料:采用台积电(TSMC)7nm FinFET工艺打造;采用新型二维片上网络(2D NoC)技术,支持片上处理引擎之间所需的高带宽通信;将FPGA与ASIC技术融合,兼顾了两者的优点,具体做法是将内核执行外的算法冻结;那时候就支持GDDR6、400G以太网端口等,现在依然可以继续扩展。
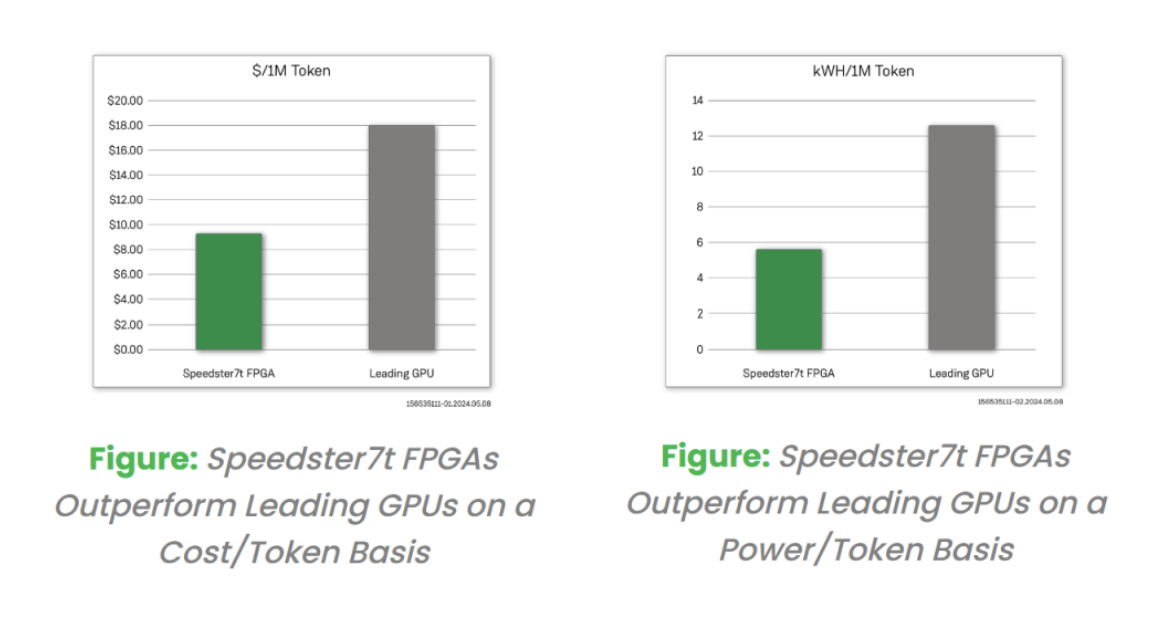
最近,Achronix更是放出了自己FPGA器件在LLM的基准测试结果。
通过对比上Speedster7t和领先GPU在Llama2 70B模型的推理性能上,Achronix计算出基于 FPGA 的解决方案的每token的价格($/token)提高了 200%。除了成本优势外,在比较 FPGA和GPU卡的相对功耗时,Achronix观察到与基于GPU的解决方案相比,产生的 kWh/token提高了200%。
Achronix还在基准测试中声明,这些优势表明FPGA可以成为一种经济且能效高效的LLM解决方案。
AMD:FPGA更适合低时延场景
2024年6月,AMD推出第一款大规模数据处理市场的加速卡产品Alveo V80,非常适合高性能计算、数据分析、金融科技、网络安全、存储或AI计算的应用。它不仅使用了Versal FPGA自适应SoC,还包含HBM。
具体从架构来看,Alveo V80是Versal HBM系列家族最大的一个器件,Alveo V80加速卡基于7nm工艺的AMD Versal XCV80 HBM系列自适应SoC,具备2574K个LUT逻辑单元和10848个DSP计算逻辑片;包括一个32GB的DDR4 DIMM扩展插槽;带宽达到每秒800GB,可以应对非常大的数据工作量要求,消除很多瓶颈;采用PCle Gen5接口,能够支持64G传输速率,是之前第四代的2倍;支持MCIO的连接,有可扩展的GTY,可以实现存储卡的一系列连接;全高有3/4长,共300W功率,采用被动冷却,可以使用Vivado工具进行开发。

相比传统的GPU加速卡都要与CPU连接,扩展数量存在很大的限制,Alveo V80这样的网络附接加速卡就更灵活一些,包括低时延传入网络、绕开CPU与加速器之间的PCIe连接瓶颈、无需独立网卡,从而实现加速卡和计算密度的最大化。

谈及GPU与FPGA,AMD认为二者擅长领域不同,各有所长。有的时候实际应用对计算、对功耗、对编程的模式都有不同的要求,就会在GPU、FPGA、ASIC不同的加速卡上做出不同的选择。
GPU主要擅长浮点、并联、定点,可以提供大量的HBM;但FPGA更擅长实时处理,具备低时延、灵活应变的特点,有非常丰富的存储器架构资源,就像乐高积木一样,可以自定义进行拼接和拼装。
Alveo系列产品主要针对的是内联网络、实时处理,比如实时传感器的处理,或者对于时延要求很高的金融领域,需要非常灵活应变的一些特点,那么FPGA的自适应SoC就是非常好的解决方案。在实际中也需要看不同的架构,比如说它时延需要非常低,而且对自定义要求很高的工作负载来实现非常好的每瓦性能,需要很高的灵活应变,那么FPGA在这方面就是非常好的适配。
在2022年,AMD收购赛灵思之际,赛灵思也曾公布AIE(人工智能引擎)这一架构。
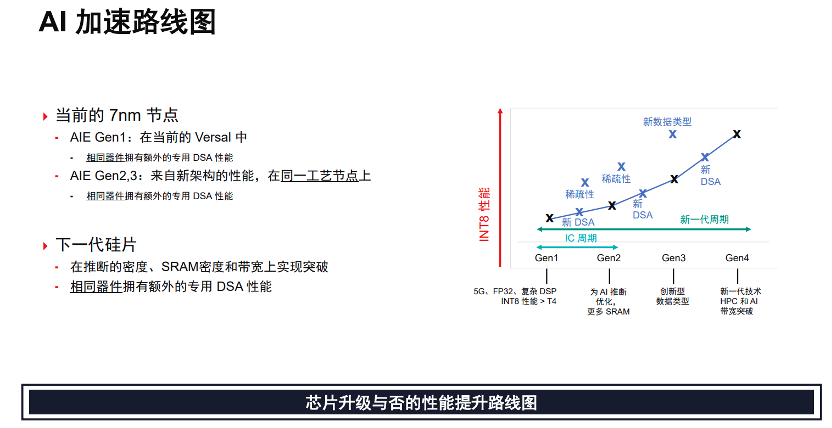
纵观AI加速产品路线,第一代AIE已布局在当前的Versal之中,搭载AIE的Versal在性能上远超于T4 GPU;第二代AIE将会提升其密度,以确保能够处理更多类型数据,并将对存储器进行分布式布置提高效率;第三代将会引进更多专用数据类型,服务于机器学习,使得基础性能能够提高2~3倍。而在下一代芯片上,将不断推出新的芯片来大幅提升性能。
Intel:FPGA在AI的三大市场
早年,英特尔就曾将FPGA与GPU对比。2020年,英特尔推出首款AI优化的FPGA — 英特尔Stratix 10 NX FPGA,英特尔在里面塞了一种名为神经处理单元(NPU)的 AI 软处理器,实际测试下来,所实现的平均性能比NVIDIA T4 GPU和NVIDIA V100 GPU分别高24倍和12倍。
可以说,FPGA最大的优势,就是灵活性,其中塞点NPU这样的外挂,就能轻轻松松提升自己的AI性能。
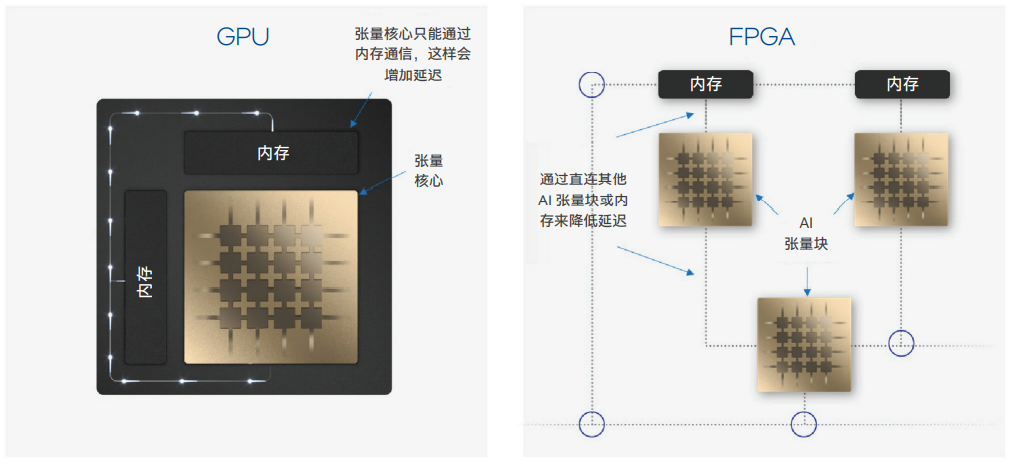
虽然英特尔FPGA的AI性能很强,不过,在拆分Altera之前,英特尔还是比较喜欢把FPGA算作加速器的一种,更强调组合加速,形成一种“超异构计算”的架构:
CPU适宜处理标量运算,一个一个算,比如控制流,非常容易处理,可以并发;GPU适宜处理矢量运算,很多数据一起算;AI更多是块状运算,需要专门做矩阵加速,数据存取也需要优化;FPGA特别适合稀疏运算,可以大幅度降低I/O及计算消耗。将这些整合起来就能各取所需,打好组合拳。
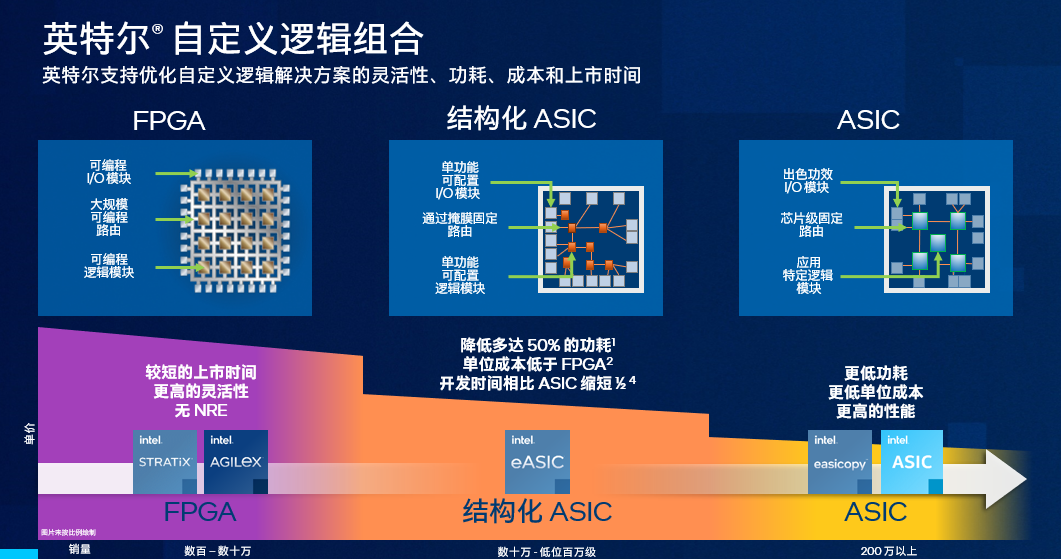
在今年3月英特尔拆分Altera时,英特尔就把FPGA “all in AI”了。
英特尔表示,AI引发的市场巨大需求,使得FPGA的市场空间远比想象中要大,未来几年其整体市场规模预计将达到约550亿美元。2022年~2023年间FPGA市场规模在90亿~100亿美元左右,并且以7~8%的复合年增长率增长。此外,AI将为FPGA市场带来巨大的机遇,根据分析师预测,到2028年,基于FPGA的解决方案将有额外的30亿美元的市场增长空间。
既然市场空间如此大,那么就完全没有必要把FPGA拴死到CPU上。可以预见,独立后的Altera,既可以继续服务英特尔的至强可扩展处理器对于高端FPGA的需求,也会按照自己的规划,从市场需求方面进一步发展,拓展自己的产品覆盖范围。
而彼时,英特尔也强调,在未来,英特尔FPGA拥有三个关键市场,FPGA会在这三个市场中进一步抢占LLM市场和边缘AI市场:
第一是数据中心,IPU是搭配至强可扩展处理器所使用的器件,它相当于是服务器中的服务器,每一个IPU器件又是基于FPGA而形成;
第二是网络,目前市场发生巨大变化,比如可编程网络的扩张及智能边缘的到来,这需要我们在整个网络当中去进行协同增效,EPF、时间敏感性网络(TSN)、P4可编程解决方案都会是未来市场机会,而英特尔的IPU/SmartNIC就是驱动下一代网络的核心;
第三是嵌入式,比如交通汽车、零售,可以说只要是涉及到我们衣食住行的一切,都在不断利用AI/ML提升生产效率和安全性,而FPGA的自身优异特性,能够降低这一切的TCO。
FPGA、GPU、ASIC,孰强孰弱
事实上,加速器的战争早已持续数年,争论主要在GPU、FPGA、ASIC之间。
GPU相对产品成熟,峰值计算能力优异,同时在图形显示的地位无可撼动,顺理成章地搭上半导体热潮,成为市场追捧的宠儿。FPGA相比GPU的核心优势在于能效、延迟和可编程性。
ASIC是为特定目的或应用而设计的定制电子电路,正因定制,所以性能和功耗肯定更强,这也就能说明为什么亚马逊、微软的AI芯片要比英伟达的GPU强那么多。成也定制,败也定制,它的算法迭代时间更长,灵活性更差,适应的场景也更少。现阶段,可编程FPGA对于实施与加速要求最苛刻的算法至关重要,直到算法已经非常成熟、并且最终确立下来之后,ASIC才可以用于实施这些硬件算法。
理性而言,GPU、FPGA、ASIC都是配合CPU计算的好能手,对厂商还是下游使用者而言,三者的特性截然不同,虽然可能会在部分应用场景下表现出更强的算力或更好的功耗,但部署过程难免要综合考虑TCO(总拥有成本)、上市时间、构建难度、部系统兼容度等,很难评判孰强孰弱。
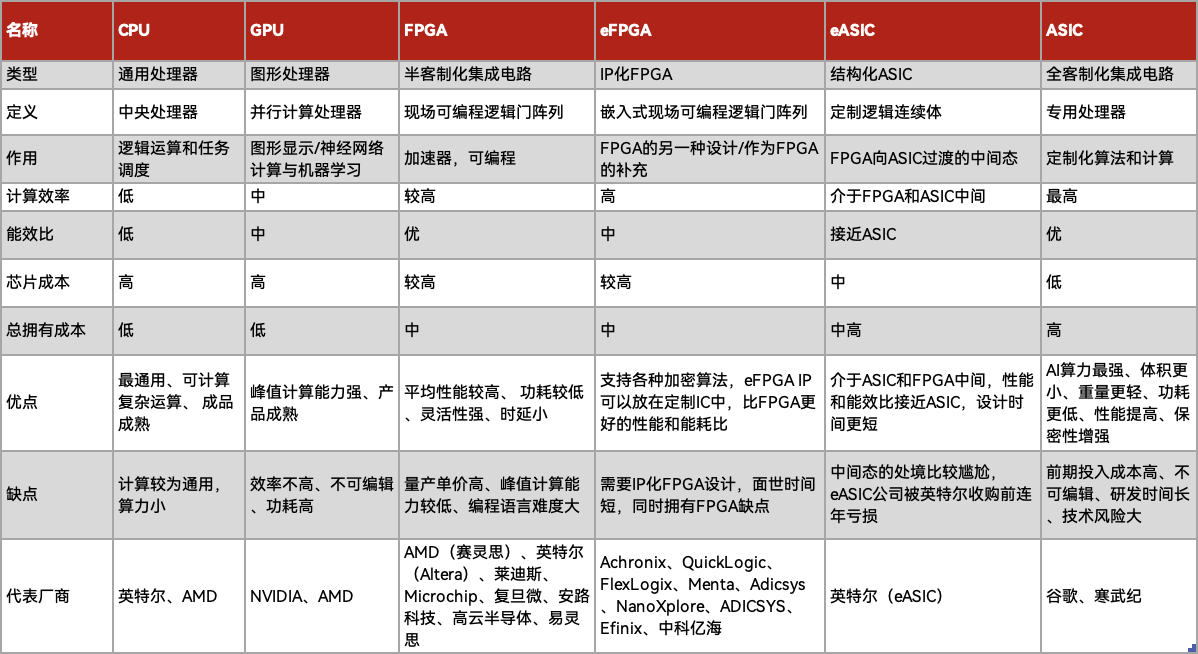
之所以FPGA没有像GPU那样出名,或许在其较高的价格,有或许在其超高的入门门槛。不过,在AI和LLM中,FPGA的确拥有自己独有的优势。
而展望未来,FPGA会分为数据中心应用和边缘应用两派,前者或更多以加速卡形式存在,后者则或更多以SoC形式存在。