汽车Chiplet面临标准混战
进入自动驾驶和数字座舱时代,整车厂或自动驾驶供应商要想做到完整闭环,芯片不可或缺,完整闭环才能加快迭代速度,最大限度掌握话语权,稳定供应链,也能降低自动驾驶系统成本。特斯拉、蔚来都这么做了,还有不少厂家正在规划或已在造芯的路上,包括Waymo、Cruise、Momenta。自研芯片最大门槛来自资金,自动驾驶芯片已经是7纳米起跳,5纳米主流,3纳米蓄势待发,一次性流片成本高达数亿美元,流片不成功的话,损失巨大。
Chiplet是快速自研芯片的捷径,可以像搭积木那样采购不同厂家的die再整合为一颗芯片,可大幅缩短研发时间,降低研发风险,降低成本。实际上特斯拉芯片也是采购不同的IP再整合而成,AI部分基本没有IP成本,主要IP成本来自CPU、GPU、NoC和存储控制与物理层。智能座舱领域使用Chiplet可以打造自己的特色,不像当前清一色的SA8155P,彰显不了特色。
Chiplet非常灵活,开发成果可无限重复利用,能适应高中低配车型。
Chiplet面临的最大问题是标准和封装技术平台的选择。Chiplet的标准体系也是OSI的7层模型。标准竞争主要集中在物理层、链路层和通讯协议层。目前所有的Chiplet接口标准,包括UCIe/BoW都需要先进封装,如设计规则为2um节点和3到5个RDL层的晶圆级扇形封装,但这些标准没有统一,大家各自为政。再有就是晶圆级的2.5D和3D封装完全被台积电和英特尔垄断,他们掌握绝对话语权,而标准不统一,对台积电和英特尔是有利的,不同的封装自然要出成本的。
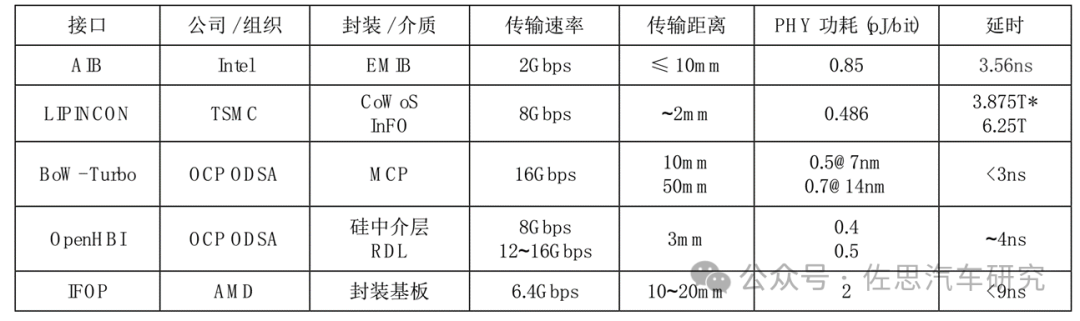
竞争最激烈的是D2D的接口标准, 已成功商用的Die-to-Die互连接口协议多达十几种,主要分为串行接口协议和并行接口协议。串行接口及协议有LR、MR、VSR、XSR、USR、PCIe、NVLink(NVIDIA),用于Cache一致性的CXL、CCIX、TileLink、OpenCAPI等;并行接口及协议有AIB/MDIO(Intel)、LIPINCON(TSMC)、Infinity Fabric(AMD)、OpenHBI(Xilinx)、BoW(OCP ODSA)、INNOLINK(Innosilicon)等。
比较而言,串行接口一般延迟比较大,而并行接口可以做到更低延迟,但也会消耗更多的Die-to-Die互连管脚;而且因为要尽量保证多组管脚之间延迟的一致,所以每个管脚不易做到高速率。串行互连与并行接口相比,适应距离更远的传输,其每比特的传输能耗更大,传输延时也更大。串行互连电路的设计难度大,但更容易在成本较低的有机基板上实现高性能的传输,制造成本更低。并行接口的互连密度高,一般需要在硅基板上实现,封装成本更高,并行信号之间存在较严重的干扰和信号完整性问题,每个I/O的传输速率受到限制。其优点是设计复杂度低,每比特的传输能耗更低。传输延时小,尤其适合作为对于访问延时要求较高的存储类接口。
串行与并行标准对比

并行接口对比
CEI-56 SerDes对比

ACC 1.0芯粒互联接口标准
中国Chiplet 产业联盟(China ChipLet League,简称:CCLL)由西安市政府、清华大学交叉信息核心技术研究院、芯动科技、紫光存储等单位于2020 年9月16日在西安启动成立。2023年2月发布Advanced Cost-driven Chiplet Interface(ACC 1.0)芯粒互联接口标准(见上图),低成本是其特色,基本上就是串口技术,难以用在高性能车载运算领域,在服务器领域或许有应用空间。
2020年8月,中科院计算所牵头成立了中国计算机互连技术联盟(CCITA),重点围绕Chiplet小芯片和微电子芯片光I/O成立了2个标准工作组,并于2021年6月在工信部中国电子工业标准化技术协会立项了《小芯片接口总线技术》《微电子芯片光互连接口技术》,也是在2023年2月发布,以串口为主,并口为辅。与英特尔的UCIe标准物理层一致,也是PCIe。
此外2024年1月,中国电科58所研究团队开始研究芯粒技术,并联合电子科大、智能院等单位共同完成了《芯粒互联协议标准Chiplet Interconnect Protocol》的研制。它主要是通信协议,与前两个国产标准不同。
国际上呼声超高的UCIe实际上是英特尔技术的翻版,UCIe的核心是AIB总线以及CXL协议,物理层还是PCIe,这些都是英特尔开发的,当然英特尔把这些IP也全部公开了,捐赠给了第三方独立机构。即便如此,总有些受制于人的感觉,这也是国内非要搞独立标准的原因。
实际Chiplet标准意义甚微,因为做高性能Chiplet需要2.5D/3D的晶圆级封装,这样的厂家全球只有台积电和英特尔。
2D封装的die-to-die连线需要经过封装基板,致基板内布线密集,因而需要占用一定的空间。所以第一代EPYC处理器4个芯粒无法紧密贴合摆放。另外有数据表明,基板内连线传输导致信号衰减较大,限制了信号频率,进而限制了die-to-die传输带宽。为了提高集成密度和die-to-die传输带宽,在2D封装基础上,通过硅中介层(silicon interposer)、硅桥(silicon bridge)、或者重布线层(RedistributionLayer,RDL)实现die-to-die的连接即是2.x封装。通过在封装基板表层嵌入金属薄膜层互连称为2.1D封装;利用有机/无机材料且无硅通孔的中介层互连称为2.3D封装;通过无源硅中介层和硅通孔(Through Silicon Vias,TSV)互连称为2.5D封装。按此标准,Intel的EMIB属于2.1D封装,日月光的FoCoS属于2.3D封装,TSMC的CoWoS属于2.5D封装。
台积电面向高性能计算场合使用CoWoS,面向成本敏感场合使用InFO_oS。英特尔的技术更先进,任何场合都可以使用EMIB或Foveros,相对台积电有成本优势,最近据说英伟达已开始下单英特尔。
三星虽然一直号称有2.5/3D封装技术,但却没有一个客户,而台积电的CoWoS产能持续吃紧。三星的2.5D/3D的晶圆级封装可以等同于无,传统的封装厂家所占利益微小,90%的利润都被台积电和英特尔拿走。关键的东西不在于设计,而是芯片的制造,集中度极高。
三星的Chiplet技术,看起来很好,就是没有客户。
台积电在2020年制定的路线图,至今仍然非常先进。
特斯拉用台积电InFO_SoW打造的Dojo D1,毛利率估计不低于80%,甚至超过90%。
台积电产能一向紧张,扩张产能非常谨小慎微,而英特尔产能非常充足。
目前Chiplet面临诸多难题,特别是缺乏CAD工具,这也使得Chiplet局限在少数几家大厂。西门子数字工业软件此前在接受媒体采访时曾说,像3D堆叠这样的方案,现在在执行上仍以手动(manually)为主。真正的自动化工具应当是去做chiplet分解、在3D封装上要确保电源贯穿各个层,完成多die的时序收敛等工作。die之间的热、可靠性、时序、电源分析目前都是厂家自己研发相关工具,干了EDA厂家的工作,EDA厂家要推出这样的工具起码还需要3-5年的时间。
虽然困难不少,晶圆代工厂基本上也只能选择英特尔和台积电,但自动驾驶必须完全闭环,软硬一体,芯片是灵魂,无法缺失,Chiplet是最佳选择。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。