Chiplet车载应用领域在何处?
Chiplet中文叫小芯片、芯粒或晶粒。目前,能量产Chiplet的厂商仅有四家,分别是英特尔、AMD、英伟达和亚马逊。华为的鲲鹏920号称全球第一个采用Chiplet的AI芯片,实际上是ARM的N1核心并联做服务器,所以只有四家。
目前的Chiplet设计中绝大部分是用于CPU的,英特尔、AMD和亚马逊都是如此。Chiplet有两种,一种是简单的单一逻辑(monolithic)die+HBM或DDR型,另一种是复杂的多个逻辑die+I/O+存储。前一种笔者认为不能算是严格意义上的Chiplet,因为这种设计只是用硅互联层代替了PCB板,把HBM与逻辑单元做到物理距离最近,以此提高数据搬运效率,它不会降低逻辑die的成本。Chiplet最早的出发点是靠分散的die来降低超大尺寸die带来的高成本,这与Chiplet的初衷完全背离了,后一种才是真正的Chiplet。
真正的Chiplet的地位比较尴尬,那就是低不成高不就。目前,在车载座舱和智能驾驶领域,monolithic芯片已完全占据市场,高通几乎垄断高端座舱,而英伟达则垄断智能驾驶高端,没有Chiplet的需求,低端更没有Chiplet的需求。很多人寄希望于高算力市场,但Chiplet需要Die to Die传输数据,在高算力领域,目前都是单一逻辑(monolithic)die+HBM或DDR型,真正的Chiplet目前只有AMD的MI300X,仅此一个特例。而HBM本身价格就很高,还需要2.5D封装,也就必须用台积电昂贵的CoWoS工艺,价格基本都在3000美元以上,显然无法用在汽车领域。
英伟达H100:售价超过3万美元的英伟达H100,外围的六片就是HBM内存。
AMD MI300A芯片: AMD在2023年CES大展上推出的MI300A芯片,包含13个Chiplet。
AMD MI300的die shot:AMD MI300的die shot,不仅有6个HBM,还有GPU(即XCD),CPU(即CCD),I/O和AID。
为何高算力领域没有真正的Chiplet?
Chiplet大放异彩都源自AMD,AMD也靠Chiplet翻身,在服务器CPU领域几乎与英特尔平分秋色。
芯片Die尺寸与良率对比
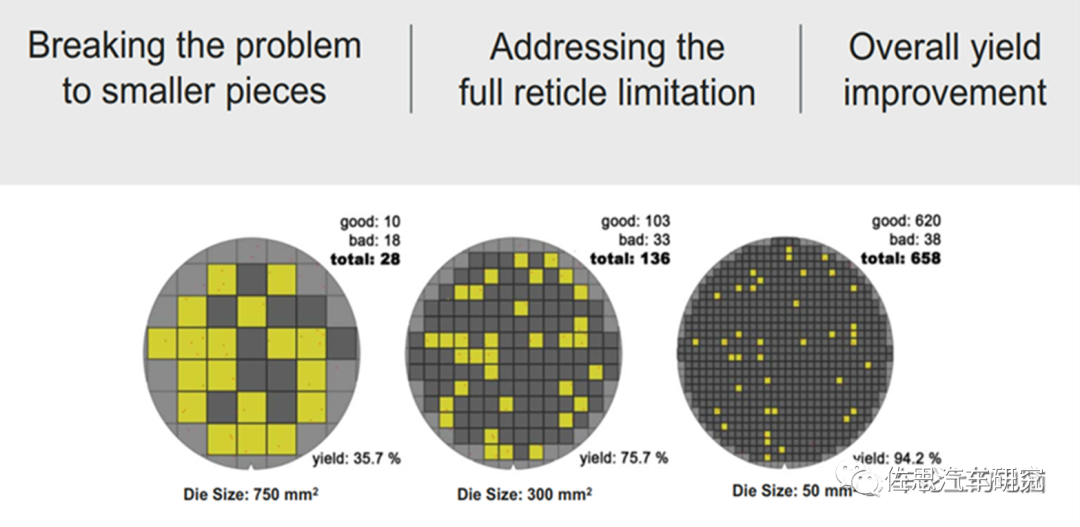
很多人引用这张图,芯片Die尺寸750平方毫米的良率只有35.7%,50平方毫米是94.2%,实际没有这么夸张。英伟达的A100的die尺寸高达826平方毫米,H100的die尺寸也有814平方毫米,远超750平方毫米。英伟达不知道Chiplet的优势么?英伟达当然知道,但英伟达也只在HBM部分用Chiplet,在GPU部分从未使用Chiplet,一直坚持monolithic,并且将来也不用。原因可以看英伟达发表的一篇论文《GPU Domain Specialization via Composable On-Package Architecture》(https://arxiv.org/pdf/2104.02188.pdf)。
Chiplet自2018年就开始推广,不过到目前反而超大Die尺寸的GPU正大行其道,真正的Chiplet却乏人问津。此外,英伟达Orin的Die尺寸大约是455平方毫米,而高通SA8295P的Die尺寸大约110平方毫米,单论硬件成本,英伟达Orin是高通SA8295P的4倍。
Chiplet必然牵涉到Die to Die(以下简写D2D)的标准,目前的Die-to-Die互连接口协议多达十几种,主要分为串行接口协议和并行接口协议。其中:
串行接口及协议有LR、MR、VSR、XSR、USR、PCIe、NVLink(NVIDIA),用于Cache一致性的CXL、CCIX、TileLink、OpenCAPI等;
并行接口及协议有AIB/MDIO(Intel)、LIPINCON(TSMC)、Infinity Fabric(AMD)、OpenHBI(Xilinx)、BoW(OCP ODSA)、INNOLINK(Innosilicon)等;
商业化的主要有NVLink、AID和Infinity Fabric,还有目前火热的UCIe。
串行接口一般延迟比较大,而并行接口可以做到更低延迟,但也会消耗更多的Die-to-Die互连管脚;而且因为要尽量保证多组管脚之间延迟的一致,所以每个管脚不易做到高速率。以目前的水准,NVLink可以做到900GB/s,Infinity Fabric也能达到896GB/s。
回过头来说UCIe,这其实是英特尔的阳谋。如果UCIe标准大规模推广,英特尔毫无疑问会是最大受益者,UCIe的物理层几乎不用想,肯定是PCIe,PCIe已经是高速互联事实标准了,而PCIe正是英特尔提出的;考虑到互通互联,推翻重来几乎不可能,协议层毫无疑问也是英特尔主导的CXL,基本上PCIe决定了最高不超过800GB/s,比现行的NVLink还低。
最致命的是UCIe的 pitch项目,从25-55um,从100-130um,都可以!某种意义上还是各做各的,die与die之间的pitch不尽相同,好比制订了铁轨的标准,但每条铁轨的宽度都不相同,就让两辆火车通行,毫无通行的可能。
Monolithic Die内部的通讯带宽远比D2D要好,D2D是要通过7层通讯协议的,无论是解串行还是物理层都影响效率,Die内部的带宽轻易可以做到10TB/s以上,是D2D的10到20倍。
这是英伟达坚持不用Chiplet的原因,也是英伟达成功的原因之一。UCIe联盟里自然也不会有英伟达的身影,不过英伟达的die可以支持UCIe,你要买英伟达的die做Chiplet也是可以的,不过嘛,那与买英伟达的芯片没区别。UCIe是英特尔下的一步大棋局,英特尔的EMIB封装工艺是做Chiplet的最佳选择,UCIe标准可以从台积电抢不少客户,目前来看,亚马逊已经是第一个客户,不过亚马逊做的也是CPU,即Graviton。估计微软是第二个客户。
虽然Chiplet不适合高密度计算,但微软独辟蹊径,提出了Chiplet Cloud。
微软的Chiplet Cloud架构
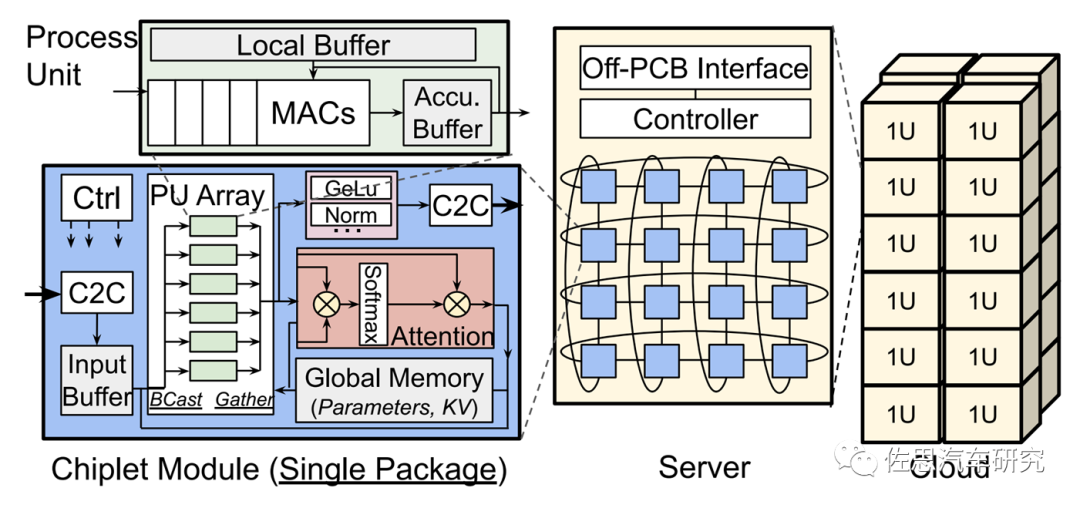
来源:微软
微软脑洞大开,将Chiplet不是放在有机基板上,更不用硅互联层,而是直接放在PCB上,大大降低成本,最少降低50%成本。
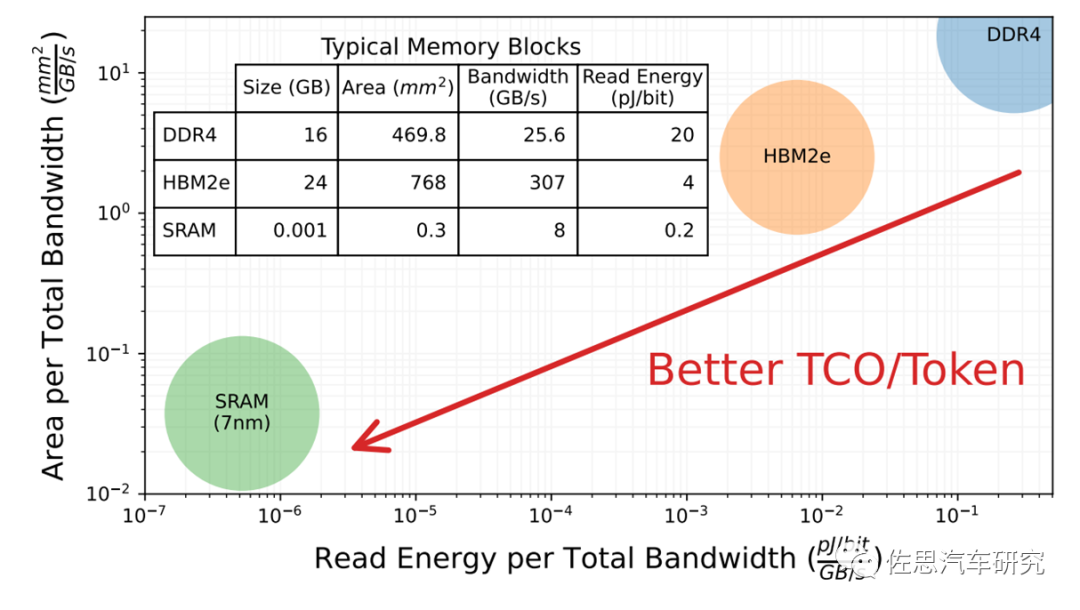
微软的设计也不用昂贵的HBM,而是用SRAM,这一点类似特斯拉的DojoD1。特斯拉用台积电最昂贵的SOIC 3D封装,有354个核心,440MB的SRAM,而微软的想法是将这354个节点独立为一个个Chiplet,直接封装在PCB板上,比特斯拉的SOIC成本估计能降低90%。SRAM将存储所有训练产生的权重和中间激活值以及KV缓存,这种设计有个缺点,那就是只能用于训练,训练阶段是为了产生权重模型的,无需一次性存储全部权重模型参数,可以分散到多个核心上,几百MB的SRAM就够;但在推理阶段则不同,它需要每次都导入完整的权重模型参数,需要几十到几百GB的SRAM,这么大的SRAM一整张12英寸晶圆都无法容纳。而车载领域显然是不需要训练的,只需要推理。这个Chiplet与其说是Chiplet不如叫多核心SRAM。
当然有人会说AMD最新的MI300X是8个GPU做的Chiplet,用于LLM领域,证明Chiplet可以用于高密度计算领域。不过,很少人注意到AMD的MI300系列都有至少2个AID,这正是秘密所在。
MI300配置情况
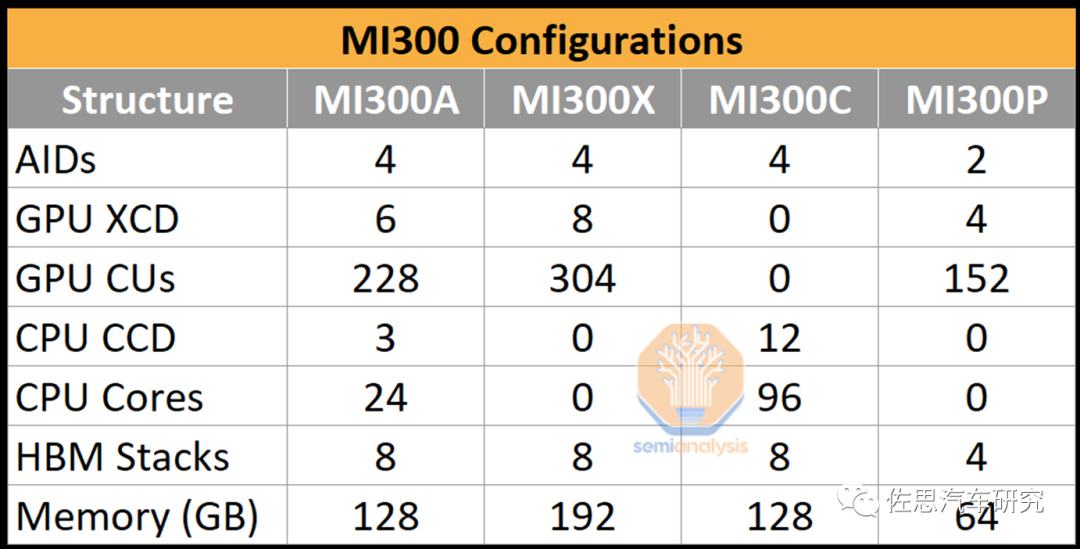
来源:semianalysis
MI300X也不例外,有4个AID。AID是台积电与AMD联合开发的,这个AID包含2个HBM内存控制器、64MB内存附加末级(MALL)缓存、3个最新一代视频解码引擎、36个xGMI/PCIe/CXL通道,以及AMD的片上网络(NoC)。在4个小芯片的配置中,拥有256MB的MALL缓存,达到了英伟达H100的50MB的MALL缓存的5倍。它采用HBM领域用的TSV技术,也就是混合键合(hybrid bonding)技术将AID连接到其他小芯片,可以达到4.3TB/s的带宽(平均到每个AID上接近1TB/s),这是TSV+Chiplet技术,可不是D2D。这算是台积电独家技术,价格肯定非常高昂。AMD的GPU也有用到此技术,AMD称之为超短物理距离(USR)。不过和单一芯片比肯定还是要差点。
AMD用Chiplet主要是在CPU领域,车内对CPU算力的需求很不明确,AI算力因为Transformer倒是需求很旺。车载CPU用上Chiplet的可能性极小。
Chiplet另一个麻烦是成本太高。
几种Chiplet技术对比
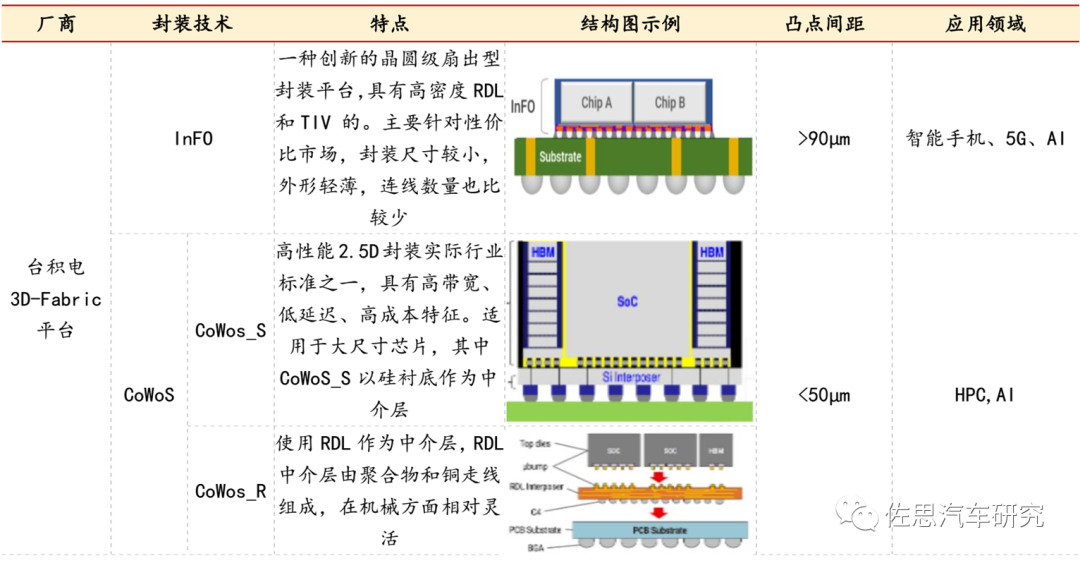

如果需要高算力密度的Chiplet设计,就必须用2.5D或3D封装,尽管英特尔的EMIB价格远低于台积电的CoWoS,但除了英特尔自己,没有第三方客户使用,主要原因是英特尔做晶圆代工刚起步,经验不够丰富,英特尔的晶圆代工工艺也明显落后台积电。此外,EMIB性能也略低CoWoS。基板封装的InFo虽然成本低,但AI性能也低,用在CPU领域才比较合适。
用CoWoS的芯片价格基本都在3000美元以上,一方面是CoWoS产能紧张,台积电几乎垄断2.5D封装领域,没有竞争压力。虽然台积电说会扩展产能,但是维持产能紧张意味着更高的利润。另一方面CoWoS一般都有HBM内存,而HBM内存因为AI需求暴增,SK Hynix近乎垄断,三星和美光产量很低,HBM持续涨价。
Chiplet和英伟达Orin比还有些竞争力,但要到上千TOPS的Transformer时代,Chiplet竞争力还是不如英伟达的GPU。在座舱领域,高通的Die尺寸本身就很小,Chiplet毫无胜算。因为台积电的CoWoS产能紧张,连英伟达都未能获得足够产能;高性能Chiplet必须用英特尔的EMIB,也就必须让英特尔代工,因为EMIB可不是封测代工厂(OSAT)能做的。一般性能的Chiplet基本上就是台积电的InFo,OSAT也能做封装。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。