自动驾驶传感器如何进行数据融合?
自动驾驶感知模块中传感器融合已经成为了标配,只是这里融合的层次有不同,可以是硬件层(如禾赛,Innovusion的产品),也可以是数据层(这里的讨论范围),还可以是任务层像障碍物检测(obstacle detection),车道线检测(lane detection),分割(segmentation)和跟踪(tracking)以及车辆自身定位(localization)等。
有些传感器之间很难在底层融合,比如摄像头或者激光雷达和毫米波雷达之间,因为毫米波雷达的目标分辨率很低(无法确定目标大小和轮廓),但可以在高层上探索融合,比如目标速度估计,跟踪的轨迹等等。
这里主要介绍一下激光雷达和摄像头的数据融合,实际是激光雷达点云投影在摄像头图像平面形成的深度和图像估计的深度进行结合,理论上可以将图像估计的深度反投到3-D空间形成点云和激光雷达的点云融合,但很少人用。原因是,深度图的误差在3-D空间会放大,另外是3-D空间的点云分析手段不如图像的深度图成熟,毕竟2.5-D还是研究的历史长,比如以前的RGB-D传感器,Kinect或者RealSense。
这种融合的思路非常明确:一边儿图像传感器成本低,分辨率高(可以轻松达到2K-4K);另一边儿激光雷达成本高,分辨率低,深度探测距离短。可是,激光雷达点云测距精确度非常高,测距远远大于那些Infrared/TOF depth sensor,对室外环境的抗干扰能力也强,同时图像作为被动视觉系统的主要传感器,深度估计精度差,更麻烦的是稳定性和鲁棒性差。所以,能不能把激光雷达的稀疏深度数据和致密的图像深度数据结合,形成互补?
另外,稀疏的深度图如何upsample变得致密,这也是一个已经进行的研究题目,类似image-based depth upsampling之类的工作。还有,激光雷达得到的点云投到摄像头的图像平面会发现,有一些不反射激光的物体表面造成“黑洞”,还有远距离的街道或者天空区域基本上是没有数据显示,这样就牵涉到另一个研究题目,image-based depth inpainting / completion。
解决这个问题的前提是,激光雷达和摄像头的标定和同步是完成的,所以激光雷达的点云可以校准投影到摄像头的图像平面,形成相对稀疏的深度图。
我们分析的次序还是先传统方法,后深度学习方法,最近后一种方法的文章2017年以后逐渐增多。笔者开始这方面工作是恰恰是2017年,非常荣幸地发现当时发表的学术论文和自己的方向非常接近,并且笔者在这些论文公开化之前已经申请了多个专利。
传统方法
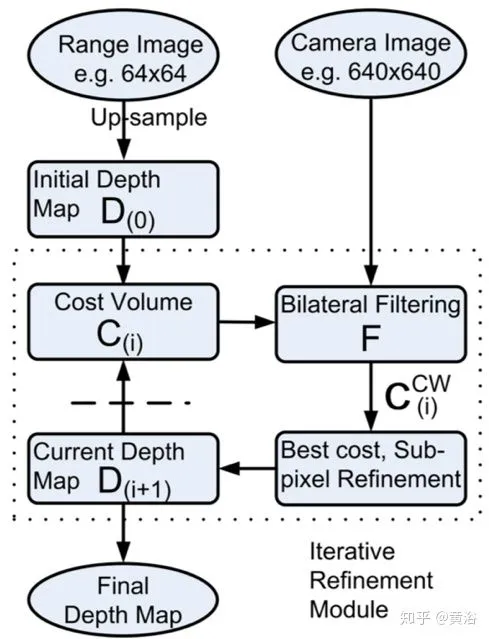
首先,把任务看成一个深度图内插问题,那么方法类似SR和upsampling,只是需要RGB图像的引导,即image-guided。
实现这种图像和深度之间的结合,需要的是图像特征和深度图特征之间的相关性,这个假设条件在激光雷达和摄像头传感器标定和校准的时候已经提到过,这里就是要把它应用在pixel(像素)/depel(深度素)/surfel(表面素)/voxel(体素)这个层次。
基本上,技术上可以分成两种途径:局部法和全局法。这样归纳,看着和其他几个经典的计算机视觉问题,如光流计算,立体视觉匹配和图像分割类似。
是否还记得图像滤波的历史?均值滤波-》高斯滤波-》中值滤波-》Anisotropic Diffusion -》Bilateral滤波(等价于前者)-》Non Local Means滤波-》BM3D,这些都是局部法。那么Joint Bilateral Filtering呢,还有著名的Guided image filtering,在这里都可以发挥作用。
这是一个例子:bilateral filter
再看一个类似的方法:guided image filtering
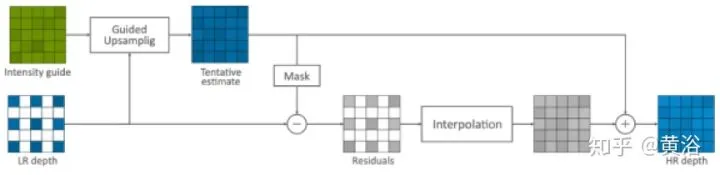
还有上述方法的改进型:二次内插,第一次是在残差域内插,第二次是应用前面的guided image filtering方法。

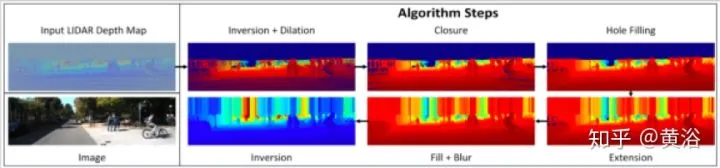
特别需要说一下,最近有一个方法,采用传统形态学滤波法,性能不比深度学习CNN差,不妨看一下它的流程图:有兴趣可以搜搜 “In Defense of Classical Image Processing: Fast Depth Completion on the CPU“,其结果和CNN方法的比较也附上。

全局法,自然就是MRF,CRF,TV(Total variation),dictionary learning 和 Sparse Coding之类。下面为避免繁琐的公式拷贝,就直接给出论文题目吧。
下一个是“Image Guided Depth Upsampling using Anisotropic Total Generalized Variation“:采用TV,传感器虽然是ToF,激光雷达也适用。接着一个是“Semantically Guided Depth Upsampling”:引入语义分割,类似depth ordering。

如果把稀疏深度图看成一个需要填补的问题,那么就属于另外一个话题:image-guided depth inpainting/completion,这方面的技术基本都是全局法,比如“Depth Image Inpainting: Improving Low Rank Matrix Completion with Low Gradient Regularization“:

有一类方法,将激光雷达点云投影到图像平面的点作为prior或者"seed",去修正图像的深度估计过程,这就好比一个由激光雷达点云投影到图像上的稀疏点构成的网格(grid),去指导/约束双目图像匹配。
下面这个方法将Disparity Space Image (DSI)的视差范围缩小:

如图方法结合激光雷达点云的投影和立体匹配构成新的prior:

下面介绍深度学习的方法。
深度学习方法
从2017年开始,这个方面的应用深度学习的论文开始多起来了,一是自动驾驶对传感器融合的重视提供了motivation,二是深度学习在深度图估计/分割/光流估计等领域的推广应用让研究人员开始布局着手多传感器融合的深度学习解法。
笔者看到的这方面公开的第一篇论文应该是2017年9月MIT博士生Fangchang Ma作为第一作写的,“Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image“。其实第一篇公开的论文是在2017年8月,来自德国Andreas Geiger研究组的论文在International Conference on 3D Vision (3DV)发表,“Sparsity Invariant CNN”。
他们开拓性的工作使Kitti Vision Benchmark Suite启动了2018年的Depth Completion and Prediction Competition,不过MIT获得了当年Depth Completion的冠军。几天前(2019年2月)刚刚公开的最新论文,是来自University of Pennsylvania的研究组,“DFuseNet: Fusion of RGB and Sparse Depth for Image Guided Dense Depth Completion”。
先说Sparsity Invariant CNN。输入是深度图和对应的Mask图,后者就是指激光雷达投影到图像平面有值的标志图,为此设计了一个称为sparse CNN的模型,定义了sparse convolution的layer:
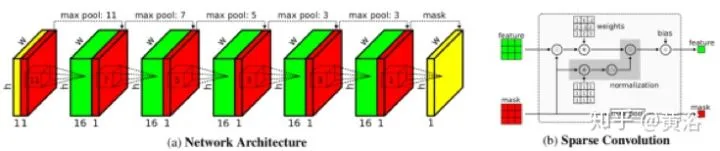
结果想证明这种模型比传统CNN模型好:

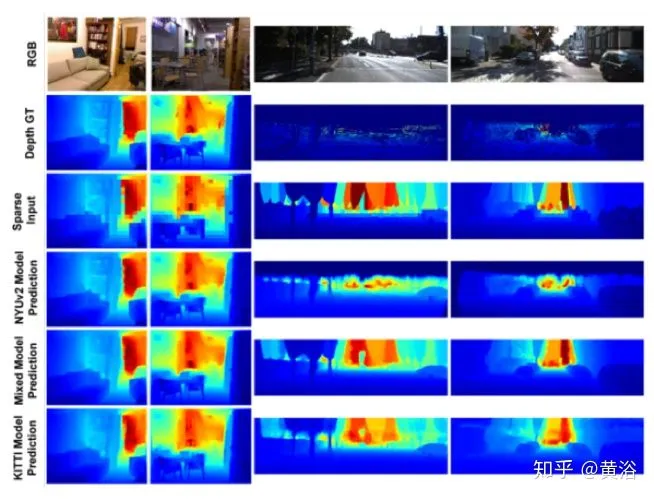
再回头看看MIT的方法。一开始还是“暴力”方法:其中针对KITTi和NYU Depth(室内)设计了不同模型
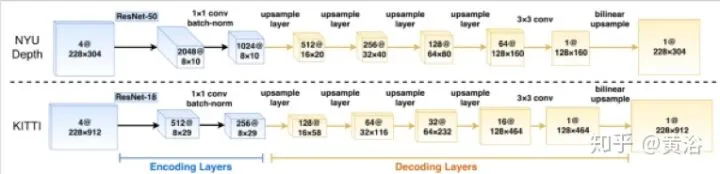
结果看上去不错的:
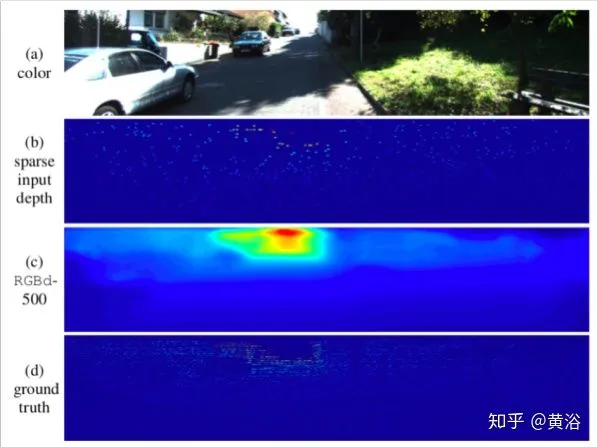
差不多一年以后,监督学习RGB到深度图的CNN方法和利用相邻帧运动的连续性约束self-learning方法也发表了,凭此方法MIT获得了KITTI比赛的冠军:
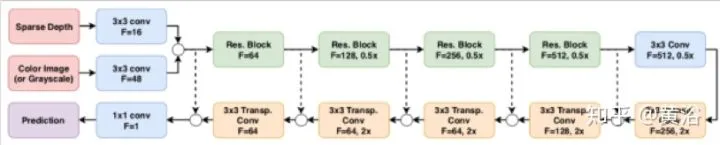

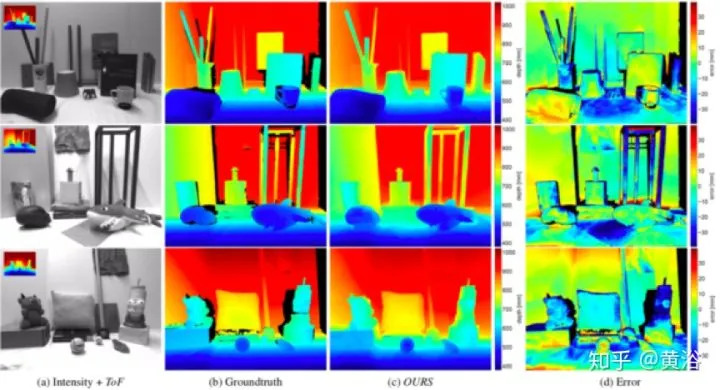
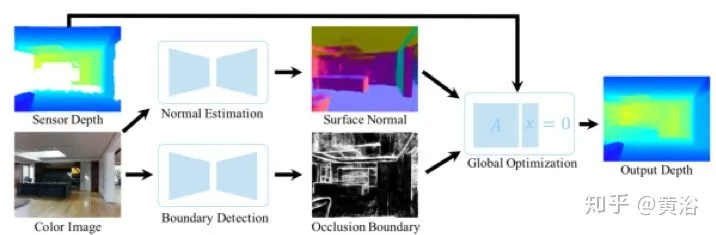
一个同时估计surface normals 和 occlusion boundaries的方法如下,听起来和单目深度估计很相似的路数,“Deep Depth Completion of a RGB-D Image“:

这是AR公司MagicLeap发表的论文,“Estimating Depth from RGB and Sparse Sensing“:模型称为Deep Depth Densification (D3),
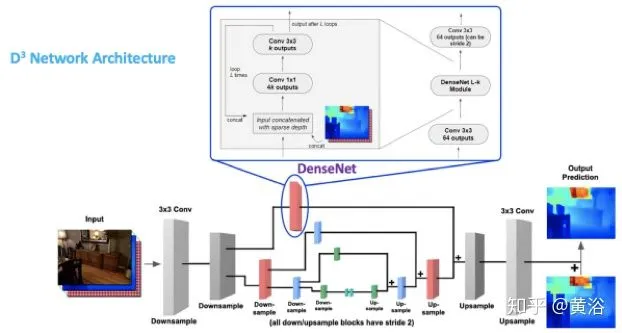
它通过RGB图像,深度图和Mask图输入生成了两个特征图:二者合并为一个feature map

看看结果:
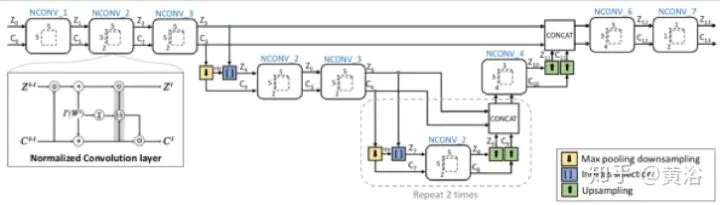
再看另一个工作 “Propagating Confidences through CNNs for Sparse Data Regression“:提出normalized convolution (NConv)layer的改进思路,训练的时候NConv layer通过估计的confidence score最大化地融合 multi scale 的 feature map

ICRA的论文“High-precision Depth Estimation with the 3D LiDAR and Stereo Fusion“只是在合并RGB image和depth map之前先通过几个convolution layer提取feature map:
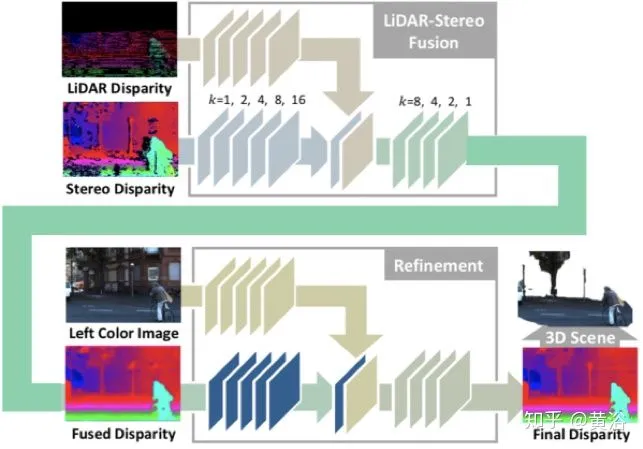
看结果:其中第三行是立体视觉算法SGM的结果,第四行才是该方法的。

法国INRIA的工作,“Sparse and Dense Data with CNNs: Depth Completion and Semantic Segmentation“:不采用Mask输入(文章分析其中的原因是因为layer-by-layer的传递造成失效),而语义分割作为训练的另一个目标。

作者发现CNN方法在早期层将RGB和深度图直接合并输入性能不如晚一些合并(这个和任务层的融合比还是early fusion),这也是它的第二个发现,这一点和上个论文观点一致。
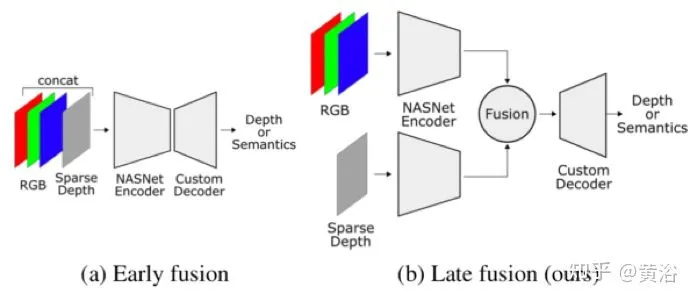
看结果:

Note:在这两篇论文发表一年之前,笔者已经在专利申请中把RGB图像和深度图合并的两种CNN模型方法都讨论了,并且还补充了一种CNN之后采用CRF合并的模型方法,该思路也是来自于传统机器学习的方法。当然单目或者双目图像输入都已经讨论。
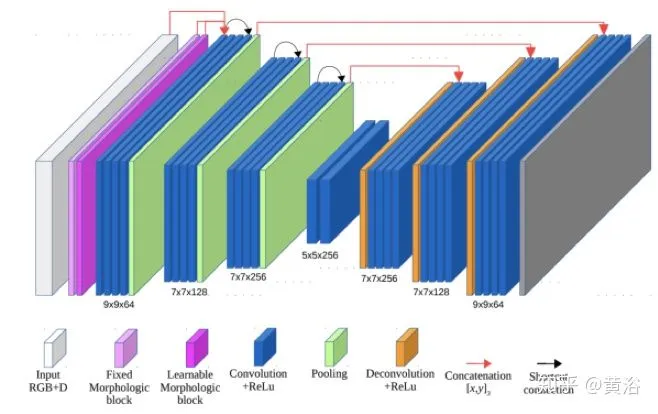
有一篇文章,“Learn Morphological Operators for Depth Completion“,同样利用图像分割的思路来帮助depth completion,只是它定义了一种Contra-harmonic Mean Filter layer近似形态学算子(structured element),放在一个U-Net模型:

ETH+Princeton+Microsoft的论文 “DeepLiDAR: Deep Surface Normal Guided Depth Prediction from LiDAR and Color Image“:还是需要输入Mask图(嗯嗯,有不同看法吗),也引入了surface normal图增强depth prediction,还有confidence mask,特别加入了attention机制(目标驱动)。
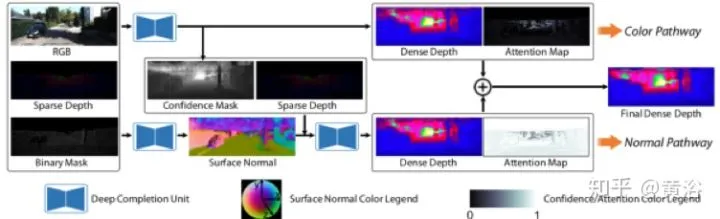
看看结果:

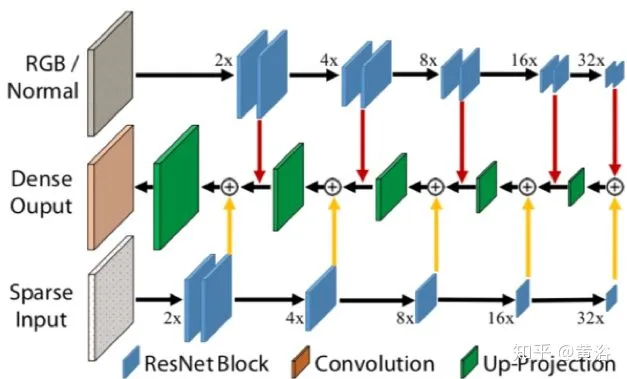
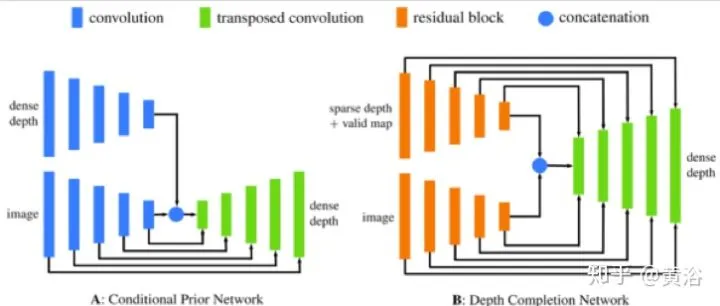
论文“Dense Depth Posterior (DDP) from Single Image and Sparse Range“提出了两步学习法,一是Conditional Prior Network (CPN) ,二是Depth Completion Network (DCN) :
最后一个论文,是刚刚出来的“DFuseNet: Fusion of RGB and Sparse Depth for Image Guided Dense Depth Completion“:基于Spatial Pyramid Pooling (SPP) blocks 分别做depth和image的encoder,训练的时候stereo不是必须的,mono也行(参照单目的深度估计采用的训练方法)。
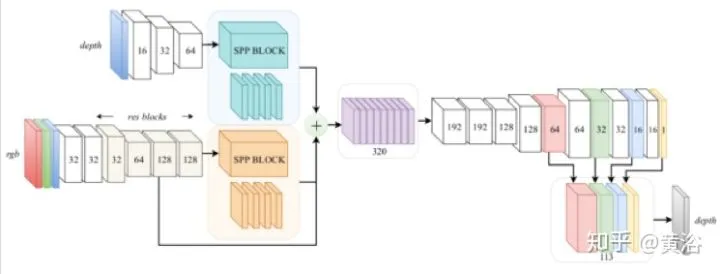
这里是SPP的结构:

下面结果(2-3行)第2行是单目图像训练的,第3行是双目立体图像训练的:
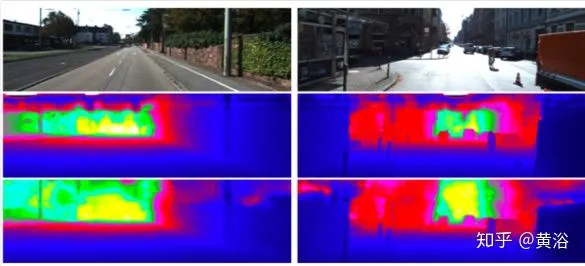
简单归纳以下这方面深度学习的工作:大家都是从暴力训练的模型开始,慢慢加入几何约束,联合训练的思路普遍接受。似乎拖延RGB和depth合并的时机是共识,分别训练feature map比较好,要不要Mask图输入还有待讨论。
本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。